V relačních databázích vytváříme tabulky pro ukládání dat v různých formátech. SQL Server ukládá data ve formátu řádků a sloupců, které uchovávají hodnotu spojenou s každým datovým typem. Při návrhu tabulek SQL definujeme datové typy, například integer, float, decimal, varchar a bit. Například tabulka, která uchovává údaje o zákaznících, může mít pole jako jméno zákazníka, e-mail, adresa, stát, země atd. Nad tabulkou SQL se provádějí různé příkazy SQL, které lze rozdělit do následujících kategorií:
- Jazyk definice dat (DDL): Tyto příkazy se používají k vytváření a úpravám databázových objektů v databázi.
- Vytvořit: Vytváří objekty
- Alter: Modifikuje objekty
- Drop: Odstraní objekty
- Truncate: Odstraní objekty: Odstraní všechna data z tabulky
- Jazyk pro manipulaci s daty (DML):
- Select: Tyto příkazy vkládají, načítají, upravují, odstraňují a aktualizují data v databázi: Příkazy pro načtení dat z jedné nebo více tabulek
- Vložení: Přidá nová data do tabulky
- Aktualizace: Upraví existující data
- Odstranění: Odstraní existující záznamy v tabulce
- Jazyk pro řízení dat (DCL): Tyto příkazy jsou spojeny s řízením práv nebo oprávnění v databázi.
- Udělit: Přiděluje uživateli oprávnění
- Odvolat: Odvolává oprávnění uživateli
- Jazyk pro řízení transakcí (TCL):
- Commit: Tyto příkazy řídí transakce v databázi: Uloží změny provedené dotazem
- Rollback: Vrátí explicitní nebo implicitní transakci na začátek transakce nebo na bod uložení uvnitř transakce
- Uložit transakce: Nastaví bod uložení nebo značku v rámci transakce
Předpokládejme, že máte v tabulce SQL uložena data objednávek zákazníků. Pokud byste do této tabulky neustále vkládali data, mohla by tabulka obsahovat miliony záznamů, což by způsobilo problémy s výkonem v rámci vašich aplikací. Také údržba vašich indexů by mohla být časově velmi náročná. Často nepotřebujete uchovávat objednávky starší než tři roky. V těchto případech byste mohli tyto záznamy z tabulky odstranit. Tím byste ušetřili místo v úložišti a také snížili nároky na údržbu.
Data můžete z tabulky SQL odstranit dvěma způsoby:
- Pomocí příkazu SQL delete
- Pomocí příkazu truncate
Na rozdíl mezi těmito příkazy SQL se podíváme později. Nejprve prozkoumáme příkaz SQL delete.
Příkaz SQL delete bez jakýchkoli podmínek
V příkazech jazyka pro manipulaci s daty (DML) odstraňuje příkaz SQL delete řádky z tabulky. Můžete odstranit konkrétní řádek nebo všechny řádky. Základní příkaz delete nevyžaduje žádné argumenty.
Vytvořme tabulku Orders SQL pomocí níže uvedeného skriptu. Tato tabulka má tři sloupce , a .
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Vložíme do této tabulky několik záznamů.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Předpokládejme, že nyní chceme data z tabulky odstranit. Pro odstranění dat můžete zadat název tabulky pomocí příkazu delete. Oba příkazy SQL jsou stejné. Můžeme zadat název tabulky z (nepovinného) klíčového slova nebo zadat název tabulky přímo za příkazem delete.
Delete OrdersGoDelete from OrdersGO
Příkaz SQL delete s filtrovanými daty
Těmito příkazy SQL odstraníme všechna data tabulky. Obvykle z tabulky SQL neodstraňujeme všechny řádky. Chceme-li odstranit konkrétní řádek, můžeme k příkazu delete přidat klauzuli where. Klauzule where obsahuje kritéria filtru a nakonec určuje, které řádky se odstraní.
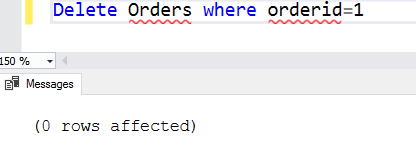
Předpokládejme například, že chceme odstranit id objednávky 1. Jakmile přidáme klauzuli where, SQL Server nejprve zkontroluje odpovídající řádky a odstraní tyto konkrétní řádky.
Delete Orders where orderid=1
Pokud je podmínka klauzule where false, neodstraní žádné řádky. Například jsme z tabulky orders odstranili řádek 1. Pokud příkaz provedeme znovu, nenajde žádné řádky, které by splňovaly podmínku klauzule where. V tomto případě vrátí 0 ovlivněných řádků.
Příkaz SQL delete a klauzule TOP
K odstranění řádků můžete použít i příkaz TOP. Například níže uvedený dotaz odstraní 100 nejlepších řádků z tabulky Objednávky.
Delete top (100)from Orders
Protože jsme nezadali žádné ‚ORDER BY‘, vybere náhodné řádky a odstraní je. Klauzuli Order by můžeme využít k seřazení dat a odstranění horních řádků. V níže uvedeném dotazu se seřadí sestupně a pak je z tabulky odstraní.
Delete from Orders where In(Select top 100 FROM Ordersorder by Desc)
Mazání řádků na základě jiné tabulky
Někdy potřebujeme odstranit řádky na základě jiné tabulky. Tato tabulka může existovat ve stejné databázi nebo ne.
- Vyhledání tabulky
K odstranění těchto řádků můžeme použít metodu vyhledání tabulky nebo spojení SQL. Chceme například odstranit řádky z tabulky, které splňují následující podmínku:
Měly by mít odpovídající řádky v tabulce .
Podívejte se na níže uvedený dotaz, zde máme příkaz select v klauzuli where příkazu delete. SQL Server nejprve získá řádky, které vyhovují příkazu select, a poté tyto řádky z tabulky odstraní pomocí příkazu SQL delete.
Delete Orders where orderid in(Select orderidfrom Customer)
- SQL Join
Alternativně můžeme použít SQL join mezi těmito tabulkami a řádky odstranit. V níže uvedeném dotazu spojíme tabulky ] s tabulkou. Spojení SQL pracuje vždy na společném sloupci mezi tabulkami. Máme sloupec, který spojuje obě tabulky dohromady.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Abychom pochopili výše uvedený příkaz k odstranění, zobrazíme si aktuální plán provedení.
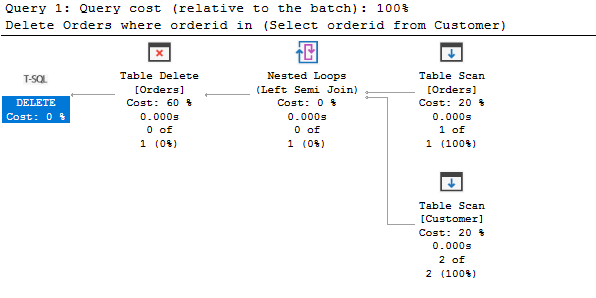
Podle plánu provedení provede prohledání obou tabulek, získá odpovídající data a odstraní je z tabulky Orders.
- Běžný tabulkový výraz (CTE)
K odstranění řádků z tabulky SQL můžeme použít také běžný tabulkový výraz (CTE). Nejprve definujeme CTE, abychom našli řádek, který chceme odstranit.
Poté spojíme CTE s příkazy tabulky SQL a odstraníme řádky.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Vliv na rozsah identity
Sloupce identity v SQL Serveru generují jedinečné, sekvenční hodnoty pro váš sloupec. Používají se především k jednoznačné identifikaci řádku v tabulce SQL. Sloupec primárního klíče je také dobrou volbou pro clusterový index v SQL Serveru.
V níže uvedeném skriptu máme tabulku. Tato tabulka má sloupec identity id.
Create Table Employee(id int identity(1,1),varchar(50))
Do této tabulky jsme vložili 50 záznamů, které vygenerovaly hodnoty identity pro sloupec id.
Declare @id int=1While(@id<=50)BEGINInsert into Employee() values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
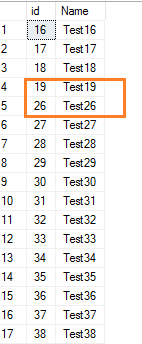
Pokud z tabulky SQL odstraníme několik řádků, nedojde k obnovení hodnot identity pro následující hodnoty. Odstraňme například několik řádků, které mají hodnoty identity 20 až 25.
Delete from employeewhere id between 20 and 25
Nyní si zobrazíme záznamy v tabulce.
Select * from employee where id>15Zobrazí se mezera v rozsahu hodnot identity.
PříkazSQL delete a protokol transakcí
SQL delete zaznamená každé odstranění řádku do protokolu transakcí. Předpokládejme, že potřebujete odstranit miliony záznamů z tabulky SQL. Nechcete odstranit velké množství záznamů v jedné transakci, protože by to mohlo způsobit exponenciální růst souboru protokolu a databáze by také mohla být nedostupná. Pokud transakci zrušíte uprostřed, může trvat hodiny, než se příkaz k odstranění vrátí zpět.
V tomto případě byste měli vždy mazat řádky po malých částech a tyto části pravidelně odevzdávat. Můžete například smazat dávku 10 000 řádků najednou, odevzdat ji a přejít k další dávce. Když SQL Server odevzdá chunk, lze řídit růst protokolu transakcí.
Osvědčené postupy
- Před mazáním dat byste měli vždy provést zálohu.
- Ve výchozím nastavení SQL Server používá implicitní transakce a odevzdává záznamy bez dotazu uživatele. Jako osvědčený postup byste měli spustit explicitní transakci pomocí příkazu Begin Transaction. To vám dává kontrolu nad odevzdáním nebo vrácením transakce. Pokud je databáze v režimu plné obnovy, měli byste také provádět časté zálohování protokolu transakcí.
- Data chcete mazat po malých částech, abyste se vyhnuli nadměrnému využívání protokolu transakcí. Tím se také vyhnete blokování i pro jiné transakce SQL.
- Měli byste omezit oprávnění, aby uživatelé nemohli mazat data. Přístup k odstraňování dat z tabulky SQL by měli mít pouze oprávnění uživatelé.
- Příkaz delete chcete spouštět s klauzulí where. Ten odstraní z tabulky SQL filtrovaná data. Pokud vaše aplikace vyžaduje časté mazání dat, je dobré pravidelně obnovovat hodnoty identity. V opačném případě byste mohli mít problémy s vyčerpáním hodnot identity.
- V případě, že chcete tabulku vyprázdnit, je vhodné použít příkaz truncate. Příkaz truncate odstraní všechna data z tabulky, používá minimální protokolování transakcí, resetuje rozsah hodnot identit a je rychlejší než příkaz SQL delete, protože okamžitě vyřadí všechny stránky pro tabulku.
- V případě, že pro své tabulky používáte omezení cizího klíče (vztah rodič-dítě), měli byste odstranit řádek z podřízeného řádku a poté z nadřízené tabulky. Pokud odstraníte řádek z nadřazeného řádku, můžete také použít možnost kaskády při mazání, která automaticky odstraní řádek z podřízené tabulky. Můžete se podívat na článek:
- Použijete-li k odstranění řádků příkaz top, SQL Server odstraní řádky náhodně. Vždy byste měli použít klauzuli top s odpovídající klauzulí Order by a Group by.
- Příkaz delete získá exkluzivní zámek záměru na referenční tabulce, proto po tuto dobu nemohou data upravovat žádné jiné transakce. Pro čtení dat můžete použít nápovědu NOLOCK.
- Měli byste se vyvarovat použití hintu tabulky k přepsání výchozího zamykacího chování příkazu SQL delete; měli by jej používat pouze zkušení DBA a vývojáři.
Důležité úvahy
Použití příkazu SQL delete k odstranění dat z tabulky SQL má mnoho výhod, ale jak vidíte, vyžaduje metodický přístup. Je důležité vždy odstraňovat data v malých dávkách a při odstraňování dat z produkční instance postupovat opatrně. Abyste se vyhnuli výpadkům nebo budoucím dopadům na výkon, je nutné mít zálohovací strategii, která umožní obnovit data v minimálním čase.