Hvis du skal til et teknologisk interview, stiller de dig sandsynligvis et spørgsmål om at implementere en algoritme til at bestemme, om en streng har alle unikke tegn. Hvad hvis du ikke kan bruge bruge bruge yderligere datastruktur, ifølge Cracking the coding Interview, 6th Edition pp.192.
Du bør stille første spørgsmål svarvejr ved hjælp af en ASCII- eller Unicode-streng. ASCII står for American Standard Code for Information Interchange (amerikansk standardkode for informationsudveksling). Den bruger tal til at repræsentere tekst. Tal (1,2,3 osv.), bogstaver (a, b, c osv.) og symboler (!) kaldes tegn. Husk, at ASCII altid har enklere tegn og lavere 8-bit byte, da det repræsenterer 128 tegn for at mindske lagerstørrelsen. ASCII har 256, hvilket ville være tilfældet i udvidet. Oprindeligt var dens tegnkoder 7 bit lange, men derefter blev den udvidet til at have en bitlængde på 8. Original = 128 tegn, udvidet = 256. Hvis ikke, så brug Unicode for at øge lagerstørrelsen.

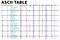
Unicode repræsenterer de fleste skriftsprog i verden. ASCII har sin pendant i Unicode. Forskellen mellem ASCII og Unicode er, at ASCII repræsenterer små bogstaver (a-z), store bogstaver (A-Z), cifre (0-9) og symboler som f.eks. tegnsætningstegn, mens Unicode repræsenterer bogstaver på engelsk, arabisk, græsk osv. matematiske symboler, historiske skrifter, emoji, der dækker et bredere udvalg af tegn end ASCII.