Se você vai ter uma entrevista tecnológica, eles provavelmente lhe fazem uma pergunta desafiadora como implementar um algoritmo para determinar se uma string tem todos os caracteres únicos. E se você não puder usar uma estrutura de dados adicional, de acordo com o Cracking the coding Interview, 6th Edition pp.192.
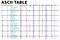
Você deve fazer a primeira pergunta meteorológica usando uma string ASCII ou Unicode. ASCII significa “American Standard Code for Information Interchange” (Código padrão americano para intercâmbio de informações). Ele usa números para representar o texto. Dígitos (1,2,3, etc.), letras (a, b, c, etc.) e símbolos (!) são chamados de caracteres. Lembre-se que, ASCII tem sempre caracteres mais simples e byte de 8 bits mais baixo, pois representa 128 caracteres para diminuir o tamanho do armazenamento. ASCII tem 256 caracteres, o que seria o caso em estendido. Originalmente seus códigos de caracteres tinham 7 bits de comprimento, mas depois foi estendido para ter um comprimento de 8 bits. Original = 128 caracteres, estendido = 256. Se não, então usando Unicode para aumentar o tamanho de armazenamento.
 >
> >
>
>
>
 >
>>>
>
>
>
>
Unicode representa a maioria das línguas escritas no mundo. O ASCII tem o seu equivalente em Unicode. A diferença entre ASCII e Unicode é que ASCII representa letras minúsculas (a-z), letras maiúsculas (A-Z), dígitos (0-9) e símbolos como pontuação, enquanto Unicode representa letras de inglês, árabe, grego, etc. símbolos matemáticos, scripts históricos, emoji cobrindo uma ampla gama de caracteres do que ASCII.