Em bases de dados relacionais, criamos tabelas para armazenar dados em vários formatos. O SQL Server armazena os dados em um formato de linha e coluna que contém um valor associado a cada tipo de dado. Quando desenhamos tabelas SQL, definimos tipos de dados como inteiros, float, decimal, varchar e bit. Por exemplo, uma tabela que armazena dados de clientes pode ter campos como nome do cliente, e-mail, endereço, estado, país e assim por diante. Vários comandos SQL são executados em uma tabela SQL e podem ser divididos nas seguintes categorias:
- Data Definition Language (DDL): Estes comandos são usados para criar e modificar os objetos do banco de dados em um banco de dados.
- Create: Cria objectos
- Alterar: Modifica objetos
- Drop: Apaga objetos
- Truncar: Apaga todos os dados de uma tabela
- Linguagem de Manipulação de Dados (DML): Estes comandos inserem, recuperam, modificam, apagam e actualizam dados na base de dados.
- Select: Recupera dados de uma única ou múltiplas tabelas
- Insert: Adiciona novos dados em uma tabela
- Update: Modifica dados existentes
- Delete: Apaga registros existentes em uma tabela
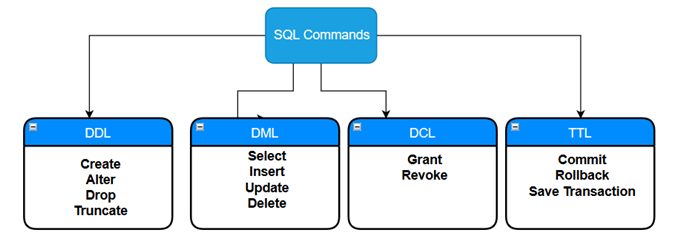
- Data Control Language (DCL): Estes comandos estão associados a direitos ou controles de permissão em uma base de dados.
- Grant: Atribui permissões a um usuário
- Revogar: Revogar permissões de um usuário
- Transaction Control Language (TCL): Estes comandos controlam transações em uma base de dados.
- Commit: Salva as alterações feitas pela consulta
- Rollback: Rolls back uma transação explícita ou implícita para o início da transação, ou para um ponto de gravação dentro da transação
- Salvar transações: Define um ponto de salvamento ou marcador dentro de uma transação
Suponha que você tenha dados de pedidos de clientes armazenados em uma tabela SQL. Se você continuasse inserindo dados nesta tabela continuamente, a tabela poderia conter milhões de registros, o que causaria problemas de desempenho dentro dos seus aplicativos. A manutenção do seu índice também pode se tornar extremamente demorada. Muitas vezes, você não precisa reter pedidos com mais de três anos de idade. Nesses casos, você poderia excluir esses registros da tabela. Isso economizaria espaço de armazenamento, além de reduzir seus esforços de manutenção.
Você pode remover dados de uma tabela SQL de duas maneiras:
- Usando uma instrução de exclusão SQL
- Usando um truncado
Vemos a diferença entre esses comandos SQL mais tarde. Vamos primeiro explorar a instrução SQL delete.
Uma instrução SQL delete sem quaisquer condições
Em instruções da linguagem de manipulação de dados (DML), uma instrução SQL delete remove as linhas de uma tabela. Você pode excluir uma linha específica ou todas as linhas. Uma instrução de exclusão básica não requer nenhum argumento.
Vamos criar uma tabela SQL de Ordens usando o script abaixo. Esta tabela tem três colunas , e .
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Inserir alguns registos nesta tabela.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Agora, suponha que queremos apagar os dados da tabela. Você pode especificar o nome da tabela para remover os dados usando a instrução de exclusão. As duas instruções SQL são as mesmas. Podemos especificar o nome da tabela a partir da palavra-chave (opcional) ou especificar o nome da tabela diretamente após a instrução de exclusão.
Delete OrdersGoDelete from OrdersGO
Uma instrução de exclusão SQL com dados filtrados
Estas instruções de exclusão SQL excluem todos os dados da tabela. Normalmente, não removemos todas as linhas de uma tabela SQL. Para remover uma linha específica, podemos adicionar uma cláusula where com a instrução delete. A cláusula where contém o critério de filtro e eventualmente determina qual(is) linha(s) remover.
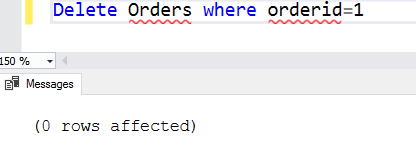
Por exemplo, suponha que queremos remover a ordem id 1. Uma vez que adicionamos uma cláusula where, o SQL Server primeiro verifica as linhas correspondentes e remove aquelas linhas específicas.
Delete Orders where orderid=1
Se a condição da cláusula where for falsa, ela não remove nenhuma linha. Por exemplo, removemos a ordem 1 da tabela de ordens. Se executarmos a declaração novamente, ela não encontrará nenhuma linha para satisfazer a condição de cláusula where. Neste caso, ele retorna 0 linhas afetadas.
SQL delete statement e TOP clause
Você pode usar o comando TOP para deletar as linhas também. Por exemplo, a consulta abaixo deleta as 100 primeiras linhas da tabela Ordens.
Delete top (100)from Orders
Desde que não tenhamos especificado nenhum ‘ORDER BY’, ele escolhe linhas aleatórias e as deleta. Podemos utilizar a Ordem por cláusula para ordenar os dados e excluir as linhas superiores. Na consulta abaixo, ele ordena as linhas em ordem decrescente, e depois as exclui da tabela.
Delete from Orders where In(Select top 100 FROM Ordersorder by Desc)
Deleting rows based on another table
Some times we need to delete rows based on another table. Esta tabela pode ou não existir na mesma base de dados.
- Mesa de procura
Podemos usar o método de procura de tabelas ou SQL join para apagar estas linhas. Por exemplo, queremos apagar linhas da tabela que satisfaçam a seguinte condição:
Deve ter as linhas correspondentes na tabela.
Consulte a consulta abaixo, aqui temos uma instrução select na cláusula where da instrução delete. O SQL Server primeiro obtém as linhas que satisfazem a instrução select e depois remove essas linhas da tabela usando a instrução delete do SQL.
Delete Orders where orderid in(Select orderidfrom Customer)
- SQL Join
Alternativamente, podemos usar as junções SQL entre estas tabelas e remover as linhas. Na consulta abaixo, nós juntamos as tabelas ] com a tabela. Um join SQL funciona sempre em uma coluna comum entre as tabelas. Temos uma coluna que une as duas tabelas.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Para entender a instrução de exclusão acima, vamos ver o plano de execução real.
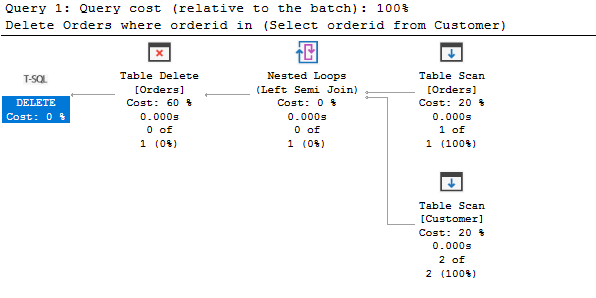
Como pelo plano de execução, ele realiza uma varredura de tabela em ambas as tabelas, obtém os dados correspondentes e os apaga da tabela Ordens.
- Expressão de tabela comum (CTE)
Podemos usar uma expressão de tabela comum (CTE) para apagar as linhas de uma tabela SQL também. Primeiro, definimos uma CTE para encontrar a linha que queremos remover.
Então, juntamos a CTE com as ordens da tabela SQL e apagamos as linhas.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Impacto no intervalo de identidade
Colunas de identidade no SQL Server geram valores únicos e sequenciais para a sua coluna. Elas são usadas principalmente para identificar de forma única uma linha na tabela SQL. Uma coluna chave primária é também uma boa escolha para um índice agrupado no SQL Server.
No script abaixo, temos uma tabela. Esta tabela tem uma coluna de identidade id.
Create Table Employee(id int identity(1,1),varchar(50))
Inserimos 50 registos nesta tabela que geraram os valores de identidade para a coluna id.
Declare @id int=1While(@id<=50)BEGINInsert into Employee() values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
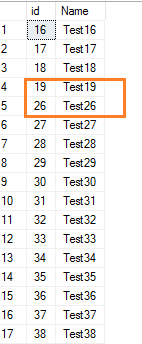
Se eliminarmos algumas linhas da tabela SQL, ela não reinicia os valores de identidade para os valores subsequentes. Por exemplo, vamos apagar algumas linhas que têm valores de identidade 20 a 25.
>
Delete from employeewhere id between 20 and 25
Agora, veja a tabela records.
Select * from employee where id>15Mostra a lacuna na faixa de valores de identidade.
SQL delete statement e o log de transação
SQL delete logs cada linha deletada no log de transação. Suponha que você precisa excluir milhões de registros de uma tabela SQL. Você não quer apagar um grande número de registros em uma única transação porque isso pode fazer seu arquivo de log crescer exponencialmente e sua base de dados também pode não estar disponível. Se você cancelar uma transação no meio, pode levar horas para reverter uma declaração de exclusão.
Neste caso, você deve sempre excluir linhas em pequenos trechos e submeter esses trechos regularmente. Por exemplo, você pode apagar um lote de 10.000 linhas de cada vez, submetê-lo e movê-lo para o próximo lote. Quando o SQL Server submete o trecho, o crescimento do log de transações pode ser controlado.
Melhores práticas
- Você deve sempre executar um backup antes de excluir os dados.
- Por padrão, o SQL Server usa transações implícitas e submete os registros sem perguntar ao usuário. Como melhor prática, você deve iniciar uma transação explícita usando Begin Transaction (Iniciar Transação). Isto dá-lhe o controlo para submeter ou reverter a transacção. Você também deve executar backups de logs de transações freqüentes se sua base de dados estiver em modo de recuperação total.
- Você quer excluir dados em pequenos pedaços para evitar o uso excessivo de logs de transações. Também evita bloqueios para outras transações SQL.
- Você deve restringir as permissões para que os usuários não possam excluir os dados. Apenas os usuários autorizados devem ter acesso para remover dados de uma tabela SQL.
- Você quer executar a instrução de exclusão com uma cláusula where. Ela remove os dados filtrados de uma tabela SQL. Se a sua aplicação requer a exclusão frequente de dados, é uma boa idéia redefinir os valores de identidade periodicamente. Caso contrário, você pode enfrentar problemas de exaustão de valores de identidade.
- No caso de querer esvaziar a tabela, é aconselhável usar a instrução truncada. A instrução truncada remove todos os dados de uma tabela, usa um mínimo de registro de transações, redefine o intervalo de valores de identidade e é mais rápida que a instrução de exclusão SQL porque desaloca todas as páginas da tabela imediatamente.
- No caso de você usar restrições de chave estrangeira (relação pai-filho) para suas tabelas, você deve excluir a linha de uma linha filha e, em seguida, da tabela pai. Se você eliminar a linha da linha pai, também pode utilizar a opção em cascata na eliminação para eliminar automaticamente a linha de uma tabela filha. O usuário pode consultar o artigo: Delete cascade and update cascade in SQL Server foreign key for further insights.
- If you use the top statement to delete the rows, SQL Server delete the rows randomly. Você deve sempre usar a cláusula superior com a correspondente Ordem por e Agrupar por cláusula.
- Uma instrução de exclusão adquire um bloqueio exclusivo de intenção na tabela de referência; portanto, durante esse tempo, nenhuma outra transação pode modificar os dados. Você pode usar a dica NOLOCK para ler os dados.
- Você deve evitar usar a dica da tabela para anular o comportamento padrão de bloqueio da instrução de exclusão SQL; ela deve ser usada somente por DBAs e desenvolvedores experientes.
Considerações importantes
Existem muitos benefícios em usar instruções de exclusão SQL para remover dados de uma tabela SQL, mas como você pode ver, ela requer uma abordagem metódica. É importante sempre excluir dados em pequenos lotes e proceder com cautela ao excluir dados de uma instância de produção. Ter uma estratégia de backup para recuperar os dados no mínimo de tempo é uma necessidade para evitar paradas ou impactos futuros no desempenho.