In relationele databases maken we tabellen om gegevens in verschillende formaten op te slaan. SQL Server slaat gegevens op in een rij- en kolomformaat dat een waarde bevat die aan elk gegevenstype is gekoppeld. Wanneer we SQL-tabellen ontwerpen, definiëren we gegevenstypen zoals integer, float, decimal, varchar en bit. Bijvoorbeeld, een tabel die klantgegevens opslaat kan velden hebben zoals klantnaam, email, adres, staat, land enzovoort. Diverse SQL-opdrachten worden uitgevoerd op een SQL-tabel en kunnen worden onderverdeeld in de volgende categorieën:
- Data Definition Language (DDL): Deze commando’s worden gebruikt om de databaseobjecten in een database te maken en te wijzigen.
- Create: Creëert objecten
- Wijzigt: Wijzigt objecten
- Drop: Verwijdert objecten
- Truncate: Verwijdert alle gegevens uit een tabel
- Data Manipulation Language (DML): Deze opdrachten voegen gegevens in de database in, halen ze op, wijzigen, verwijderen ze en werken ze bij.
- Selecteren: Haalt gegevens op uit een enkele of meerdere tabellen
- Invoegen: Voegt nieuwe gegevens toe in een tabel
- Update: Wijzigt bestaande gegevens
- Delete: Verwijdert bestaande records in een tabel
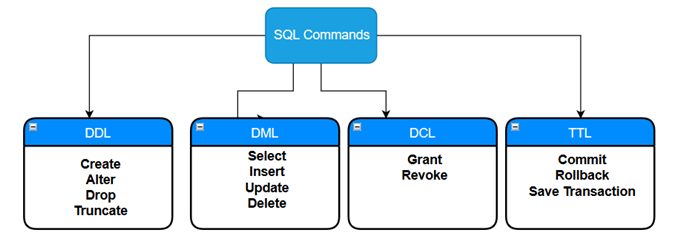
- Data Control Language (DCL): Deze opdrachten worden geassocieerd met controles van rechten of machtigingen in een database.
- Verlenen: Wijst machtigingen toe aan een gebruiker
- Revoke: Trekt machtigingen van een gebruiker in
- Transaction Control Language (TCL): Deze commando’s controleren transacties in een database.
- Commit: Slaat de door de query aangebrachte wijzigingen op
- Rollback: Rollt een expliciete of impliciete transactie terug naar het begin van de transactie, of naar een savepoint binnen de transactie
- Save transactions: Stelt een opslagpunt of marker in binnen een transactie
Stel dat u gegevens over klantbestellingen hebt opgeslagen in een SQL-tabel. Als u continu gegevens in deze tabel blijft invoegen, kan de tabel miljoenen records bevatten, wat tot prestatieproblemen in uw toepassingen zou leiden. Uw index onderhoud zou ook extreem tijdrovend kunnen worden. Vaak hoeft u orders die ouder zijn dan drie jaar niet te bewaren. In die gevallen zou u die records uit de tabel kunnen verwijderen. Dit zou zowel opslagruimte besparen als uw onderhoudsinspanningen verminderen.
U kunt gegevens op twee manieren uit een SQL-tabel verwijderen:
- Met behulp van een SQL delete-instructie
- Met behulp van een truncate
We zullen het verschil tussen deze SQL-commando’s later bekijken. Laten we eerst het SQL delete statement onderzoeken.
Een SQL delete statement zonder voorwaarden
In data manipulation language (DML) statements, een SQL delete statement verwijdert de rijen uit een tabel. U kunt een specifieke rij of alle rijen verwijderen. Een basis delete statement heeft geen argumenten nodig.
Laten we een Orders SQL tabel maken met het onderstaande script. Deze tabel heeft drie kolommen , en .
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Voeg een paar records in deze tabel in.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Nu, stel dat we de tabelgegevens willen verwijderen. U kunt de tabelnaam opgeven om gegevens te verwijderen met het delete statement. Beide SQL statements zijn hetzelfde. We kunnen de tabelnaam opgeven met het (optionele) sleutelwoord of de tabelnaam direct na de delete opgeven.
Delete OrdersGoDelete from OrdersGO
Een SQL delete statement met gefilterde gegevens
Deze SQL delete statements verwijderen alle gegevens van de tabel. Gewoonlijk verwijderen we niet alle rijen uit een SQL tabel. Om een specifieke rij te verwijderen, kunnen we een where clause toevoegen aan het delete statement. De where-clausule bevat de filtercriteria en bepaalt uiteindelijk welke rij(en) moeten worden verwijderd.
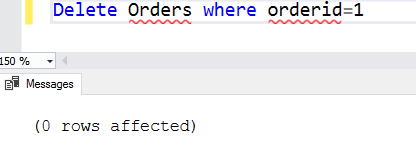
Voorbeeld, stel dat we order id 1 willen verwijderen. Zodra we een where-clausule toevoegen, controleert SQL Server eerst de corresponderende rijen en verwijdert die specifieke rijen.
Delete Orders where orderid=1
Als de where-clausule voorwaarde false is, verwijdert het geen rijen. Bijvoorbeeld, we verwijderden de geordende 1 uit de tabel orders. Als we het statement opnieuw uitvoeren, vindt het geen rijen die voldoen aan de where clause voorwaarde. In dit geval retourneert het 0 rijen.
SQL wisstatement en TOP-clausule
U kunt het TOP-statement ook gebruiken om de rijen te verwijderen. Bijvoorbeeld, de onderstaande query verwijdert de top 100 rijen uit de tabel Orders.
Delete top (100)from Orders
Omdat we geen ‘ORDER BY’ hebben opgegeven, kiest het willekeurige rijen en verwijdert ze. We kunnen de Order by clausule gebruiken om de gegevens te sorteren en de bovenste rijen te verwijderen. In de onderstaande query worden de rijen in aflopende volgorde gesorteerd en vervolgens uit de tabel verwijderd.
Delete from Orders where In(Select top 100 FROM Ordersorder by Desc)
Rijen verwijderen op basis van een andere tabel
Soms moeten we rijen verwijderen op basis van een andere tabel. Deze tabel kan al dan niet in dezelfde database bestaan.
- Tabelopzoeking
We kunnen de tabelopzoekmethode of SQL join gebruiken om deze rijen te verwijderen. We willen bijvoorbeeld rijen uit de tabel verwijderen die aan de volgende voorwaarde voldoen:
Het moet corresponderende rijen in de . tabel hebben.
Kijk naar de onderstaande query, hier hebben we een select statement in de where clause van het delete statement. SQL Server krijgt eerst de rijen die voldoen aan de select statement en verwijdert deze rijen vervolgens uit de tabel met de SQL delete statement.
Delete Orders where orderid in(Select orderidfrom Customer)
- SQL Join
Aternatief kunnen we SQL joins tussen deze tabellen gebruiken en de rijen verwijderen. In de onderstaande query voegen we de tabellen ] samen met de tabel. Een SQL join werkt altijd op een gemeenschappelijke kolom tussen de tabellen. We hebben een kolom die beide tabellen samen te voegen.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Om de bovenstaande verwijdering verklaring te begrijpen, laten we eens kijken naar de werkelijke uitvoeringsplan.
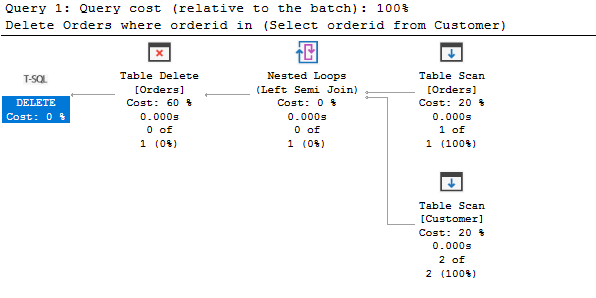
Volgens het uitvoeringsplan, het voert een tabel scan op beide tabellen, krijgt de overeenkomende gegevens en verwijdert ze uit de tabel Orders.
- Gemeenschappelijke tabeluitdrukking (CTE)
We kunnen een gemeenschappelijke tabeluitdrukking (CTE) ook gebruiken om de rijen uit een SQL-tabel te verwijderen. Eerst definiëren we een CTE om de rij te vinden die we willen verwijderen.
Dan voegen we de CTE samen met de SQL-tabel Orders en verwijderen de rijen.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Effecten op het identiteitsbereik
Identiteitskolommen in SQL Server genereren unieke, opeenvolgende waarden voor uw kolom. Ze worden in de eerste plaats gebruikt om een rij in de SQL-tabel op unieke wijze te identificeren. Een primary key kolom is ook een goede keuze voor een geclusterde index in SQL Server.
In het onderstaande script, hebben we een tabel. Deze tabel heeft een identiteitskolom id.
Create Table Employee(id int identity(1,1),varchar(50))
We hebben 50 records in deze tabel ingevoegd die de identiteitswaarden voor de id-kolom hebben gegenereerd.
Declare @id int=1While(@id<=50)BEGINInsert into Employee() values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
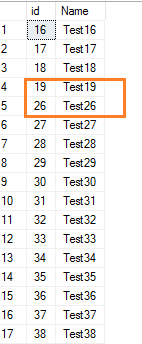
Als we een paar rijen uit de SQL-tabel verwijderen, worden de identiteitswaarden voor de volgende waarden niet opnieuw ingesteld. Laten we bijvoorbeeld een paar rijen verwijderen die de identiteitswaarden 20 tot 25 hebben.
Delete from employeewhere id between 20 and 25
Nu, bekijk de tabelrecords.
Select * from employee where id>15Het toont het gat in het bereik van de identiteitswaarden.
SQL delete statement en het transactielog
SQL delete logt elke verwijderde rij in het transactielogboek. Stel dat u miljoenen records uit een SQL-tabel moet verwijderen. Je wilt niet een groot aantal records in een enkele transactie verwijderen omdat je logbestand dan exponentieel kan groeien en je database ook onbeschikbaar kan worden. Als je een transactie halverwege annuleert, kan het uren duren om een delete statement terug te draaien.
In dit geval moet je altijd rijen in kleine chunks verwijderen en die chunks regelmatig committen. U kunt bijvoorbeeld een batch van 10.000 rijen tegelijk verwijderen, deze committen en naar de volgende batch gaan. Wanneer SQL Server de batch commit, kan de groei van het transactielogboek worden gecontroleerd.
Best practices
- U moet altijd een backup maken voordat u gegevens verwijdert.
- Standaard maakt SQL Server gebruik van impliciete transacties en committeert de records zonder de gebruiker te vragen. Als best practice moet u een expliciete transactie starten met Begin Transactie. Dit geeft u de controle om de transactie vast te leggen of terug te draaien. U moet ook regelmatig back-ups van het transactielogboek maken als uw database in volledige herstelmodus staat.
- U wilt gegevens in kleine brokjes verwijderen om overmatig transactielogboekgebruik te voorkomen. Het voorkomt ook blokkades voor andere SQL-transacties.
- U moet machtigingen beperken zodat gebruikers geen gegevens kunnen verwijderen. Alleen geautoriseerde gebruikers mogen toegang hebben om gegevens uit een SQL-tabel te verwijderen.
- U wilt het verwijderstatement uitvoeren met een where-clausule. Hiermee worden gefilterde gegevens uit een SQL-tabel verwijderd. Als uw toepassing vereist dat gegevens vaak worden verwijderd, is het een goed idee om de identiteitswaarden periodiek opnieuw in te stellen. Anders kunt u te maken krijgen met identiteitswaarde-uitputting.
- In het geval dat u de tabel wilt leegmaken, is het raadzaam om het truncate statement te gebruiken. Het truncate statement verwijdert alle gegevens uit een tabel, gebruikt minimale transactielogging, stelt het identiteitswaardebereik opnieuw in, en is sneller dan het SQL delete statement omdat het alle pagina’s voor de tabel onmiddellijk dealloceert.
- In het geval dat u foreign key constraints (ouder-kind relatie) gebruikt voor uw tabellen, moet u de rij verwijderen uit een kindrij en vervolgens uit de oudertabel. Als u de rij uit de parent tabel verwijdert, kunt u ook de cascade op verwijderen optie gebruiken om automatisch de rij uit een kind tabel te verwijderen. U kunt verwijzen naar het artikel: Delete cascade en update cascade in SQL Server foreign key voor verdere inzichten.
- Als u de top statement gebruikt om de rijen te verwijderen, verwijdert SQL Server de rijen willekeurig. U moet altijd de top-clausule gebruiken met de bijbehorende Order by- en Group by-clausule.
- Een delete-instructie verwerft een exclusief intentielock op de referentietabel; daarom kunnen gedurende die tijd geen andere transacties de gegevens wijzigen. U kunt de NOLOCK-hint gebruiken om de gegevens te lezen.
- U moet het gebruik van de tabel hint vermijden om het standaard vergrendelingsgedrag van het SQL delete statement op te heffen; het moet alleen worden gebruikt door ervaren DBA’s en ontwikkelaars.
Belangrijke overwegingen
Er zijn veel voordelen verbonden aan het gebruik van SQL delete statements om gegevens uit een SQL tabel te verwijderen, maar zoals u kunt zien, vereist het een methodische aanpak. Het is belangrijk om gegevens altijd in kleine batches te verwijderen en om voorzichtig te werk te gaan bij het verwijderen van gegevens uit een productie instance. Een back-upstrategie waarmee gegevens zo snel mogelijk kunnen worden hersteld, is een must om downtime of toekomstige gevolgen voor de prestaties te voorkomen.