Als je een technologisch interview gaat houden, stellen ze je waarschijnlijk een uitdagende vraag zoals implementeer een algoritme om te bepalen of een string alle unieke tekens heeft. Wat als je niet kunt gebruiken gebruik maken van extra datastructuur, volgens de Cracking the coding Interview, 6th Edition pp.192.
Je moet eerste vraag antwoord weer met behulp van een ASCII of Unicode string. ASCII staat voor American Standard Code for Information Interchange. Het gebruikt cijfers om tekst weer te geven. Cijfers (1,2,3, enz.), letters (a, b, c, enz.) en symbolen (!) worden karakters genoemd. Onthoud dat ASCII altijd eenvoudigere tekens en lagere 8-bits bytes heeft, omdat het 128 tekens vertegenwoordigt om de opslagruimte te verkleinen. ASCII heeft 256 dit zou het geval zijn in uitgebreid. Oorspronkelijk waren de karaktercodes 7 bits lang, maar daarna werd het uitgebreid tot een bitlengte van 8. Origineel = 128 tekens, uitgebreid = 256. Zo niet, dan met behulp van Unicode de opslagruimte vergroten.

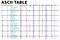
Unicode vertegenwoordigt de meeste geschreven talen in de wereld. ASCII heeft zijn equivalent in Unicode. Het verschil tussen ASCII en Unicode is dat ASCII staat voor kleine letters (a-z), hoofdletters (A-Z), cijfers (0-9) en symbolen zoals leestekens, terwijl Unicode staat voor letters van het Engels, Arabisch, Grieks enz. wiskundige symbolen, historische schriften, emoji die een breder scala aan tekens omvatten dan ASCII.