
Forsøget af AI i dagens samfund bliver mere og mere allestedsnærværende – især fordi store virksomheder som Netflix, Amazon, Facebook, Spotify og mange flere løbende implementerer AI-relaterede løsninger, der interagerer direkte (ofte bag kulisserne) med forbrugerne hver dag.
Når de anvendes korrekt på forretningsproblemer, kan disse AI-relaterede løsninger give virkelig unikke løsninger, der skaleres og forbedres over tid, hvilket skaber en betydelig effekt for både virksomhed og bruger. Men hvad betyder det at “anvende en AI-løsning korrekt”? Betyder det, at der er en forkert måde? Fra et produktperspektiv er det korte svar ja, og vi vil komme ind på hvorfor det er sådan senere i denne artikel, når vi graver dybere.
Oversigt: Først vil vi skitsere 5 use cases af datavidenskab eller maskinlæring hos Netflix. Derefter vil vi diskutere nogle forretningsbehov vs. tekniske overvejelser, som en produktchef ville se på. Derefter vil vi dykke lidt dybere ned i det måske mest interessante af disse 5 use cases, da vi identificerer, hvilket forretningsproblem det søger at løse.
1. Lad os bygge et simpelt neuralt net!
2. Beslutningstræer i maskinlæring
3. En intuitiv introduktion til maskinlæring
4. Balancen mellem passiv vs. aktiv A.I.
5 Use Cases of AI/Data/Machine Learning at Netflix
- Personalisering af filmanbefalinger – Brugere, der ser A, vil sandsynligvis se B. Dette er måske den mest velkendte funktion i en Netflix. Netflix bruger seerhistorikken for andre brugere med samme smag til at anbefale, hvad du måske er mest interesseret i at se næste gang, så du forbliver engageret og fortsætter dit månedlige abonnement for mere.
- Automatisk generering og personalisering af miniaturebilleder/kunstværker – Netflix bruger tusindvis af videobilleder fra en eksisterende film eller udsendelse som udgangspunkt for generering af miniaturebilleder, kommenterer disse billeder og rangerer derefter hvert billede i et forsøg på at identificere, hvilke miniaturebilleder der har størst sandsynlighed for at resultere i dit klik. Disse beregninger er baseret på, hvad andre, der ligner dig, har klikket på. Et resultat kunne være, at brugere, der kan lide bestemte skuespillere/filmgenrer, er mere tilbøjelige til at klikke på miniaturebilleder med bestemte skuespillere/billedeattributter.
- Location Scouting for Movie Production (Pre-Production) – Brug af data til at hjælpe med at beslutte, hvor og hvornår det er bedst at optage en film – under hensyntagen til begrænsninger i forbindelse med planlægning (skuespillere/besætningers tilgængelighed), budget (sted, fly-/hotelomkostninger) og krav til produktionsscener (optagelse om dagen eller om natten, sandsynlighed for risiko for vejrforhold på et sted). Bemærk, at dette er mere et datalogisk optimeringsproblem end en maskinlæringsmodel, der foretager forudsigelser baseret på tidligere data.
- Filmredigering (postproduktion) – Udnyttelse af historiske data om, hvornår kvalitetskontrollen tidligere er mislykkedes (når synkroniseringen af undertekster til lyd/bevægelser ikke fungerede tidligere) – for at forudsige, hvornår en manuel kontrol er mest fordelagtig i det, der ellers kan være en meget tidskrævende og besværlig proces.
- Streamingkvalitet – Brug af tidligere visningsdata til at forudsige båndbreddeforbrug for at hjælpe Netflix med at beslutte, hvornår regionale servere skal cachelagres for hurtigere indlæsningstider under spidsbelastning (forventet) efterspørgsel.
Disse 5 anvendelsestilfælde/applikationer af datavidenskab eller maskinlæring bare i Netflix alene har haft en så skalerbar indvirkning, at de for altid har ændret det teknologiske landskab og brugeroplevelsen for millioner og flere fremover. Adoption af disse AI-relaterede løsninger vil kun blive stærkere med tiden.
Men før disse use cases blev så almindelige, som de er i dag, og brugt af brugere som dig og mig, var der nogen eller en gruppe inden for Netflix, der på korrekt vis forbandt disse AI-løsninger med et forretningsbehov. Uden denne forretningsmæssige forbindelse ville disse use cases blot være tærte-i-himlen-idéer, der lå nederst i en backlog ligesom så mange andre gode idéer. Kun gennem korrekt positionering og forbindelse med Netflix’ centrale forretningsproblem blev disse idéer den virkelighed, som de er i dag.

- Hvad er det forretningsmæssige behov/problem?
- Filmanbefalinger: Identificering af problemet
- Personaliserede billedminiaturer/kunstværker: Identificering af problemet
- OK, miniaturebilleder er vigtige. Men hvad præcis skal vi justere?
- Produktovervejelser i forbindelse med personaliserede billedminiaturer
- Hvilke data har vi?
- Hvordan Netflix bruger data til at konstruere et univers af brugerprofilinteresser
- Reimagining Netflix Users in Mathematical Relation To Each Other
- Hvad har Netflix lært af alle disse data?
- I konklusion: Netflix implementerede AI (for det meste) på den rigtige måde. Lad os lære af deres tilgang.
Hvad er det forretningsmæssige behov/problem?
Bemærk i hver af de use cases, jeg har identificeret ovenfor, at de hver især er forbundet med et specifikt forretningsbehov, mål eller en hypotese.
Dette er absolut vigtigt for enhver produktchef – for at undgå fristelsen af den teknologiske entusiast, der forundres over detaljerne i datavidenskab / eller ML af intellektuelle årsager uden klart at identificere problemet eller forretningsbehovet – og potentielt bruger værdifulde tekniske ressourcer uden nogen forretningsmæssig effekt.
I sidste ende skal produktcheferne korrekt forbinde et forretningsproblem med en data-maskinlæringsløsning. Vi vil gerne undgå at have en løsning, der jagter efter et problem, ellers vil projektet miste momentum i virksomheden: Ingeniørerne vil ikke være klar over, hvad deres nordstjerne er, interessenterne på tværs af organisationen vil ikke købe ind og allokere de nødvendige ressourcer til at gøre projektet til en succes, osv.
Sørg for, at der er et problem, som en AI-løsning kan forbindes direkte med
Machine learning (ML) er en potentiel AI-løsning – men vi er nødt til først at definere problemet, før vi foreskriver denne løsning.
Hvad er det forretningsresultat, vi forsøger at opnå med ML? For dette centrale forretningsbehov er det, der styrer parametrene for de ML-modeller, der anvendes, hvilke data der indsamles og behandles osv. Vi laver ikke ML for at levere personalisering, bare fordi det er interessant teknologi – vi skal forbinde det med et forretningsproblem. Data scientists er specialister i at afdække indsigter fra dataene, men det er produktchefens rolle at koble det korrekt til et forretningsbehov eller problem og sammenligne det med konkurrerende prioriteter.
En teknisk entusiast kunne f.eks. sige:
Vil det ikke være fedt, hvis du kunne analysere/debattere et afsnit ved hjælp af stemme med Netflix – og Netflix med datainput fra tusindvis af andre brugeres reaktioner på det pågældende afsnit kunne reagere intelligent på dine kommentarer i en 2-vejs dialog frem og tilbage?
Ja, det ville være en ret fantastisk brugssituation, der udnytter naturlig sprogbehandling (NLP) til at forstå din kommentar efter episoden i kontekst. Ud over NLP bruger denne use case tekst til stemmepersonligheder samt sentimentanalyse af, hvordan tusindvis af andre følte om, hvad der skete i den pågældende episode, eller hvad de føler om en bestemt karakter. Det er faktisk en smuk sammensmeltning af flere banebrydende teknologier i én use case.
Hvis en pilot-MVP-version af dette viste, at brugere, der engagerede sig i hans nye funktion, blev længere eller kom tilbage oftere eller hjalp med at skabe mere mund-til-mund-påtale om Netflix, så kunne det berettige yderligere ressourcer. Den indledende beslutning om at bygge denne MVP ville afhænge af en strategisk beslutning truffet af interessenterne, ikke nødvendigvis prioriteret af metrikken. Det vil afhænge af virksomhedens strategi.
Men så smukt et brugerscenarie, som ovenstående er, hvilket problem løser det?
Hvordan hænger det sammen med Netflix’ hovedproblem med at holde brugerne abonneret hver måned? Hvis det er relateret, hvilke beviser (kvalitative eller kvantitative) har vi så for at understøtte dette forhold?
Og hvis dette er en legitim løsning på dette problem, er der så en enklere version af denne løsning, der på samme måde kunne løse problemet, men som er mindre teknisk kompleks? Hvordan kan f.eks. kompleksiteten af blot tekstinput og tekstoutput i stedet for stemmeinput og stemmeoutput påvirke indsatsniveauet og virkningen på brugerengagementet?
Hvad hvis en AI-grænseflade uden stemmedelen (blot tekst) opnåede 80 % af det tilsigtede brugerengagement, men kun krævede 40 % af udviklingsindsatsen? Ville det være værd at overveje en sådan alternativ vej?
Hvilken forretningsmæssig indvirkning ville en sådan løsning have i forhold til indsatsniveauet? Hvordan er dette forhold i forhold til andre konkurrerende opgaver i backloggen?
Dette er alle produktfokuserede spørgsmål, som en PM bør stille for at tilpasse teknologiske løsninger til forretningsbehovene. For i sidste ende er det forretningsbehovet, der styrer parametrene for en ML-model, og ikke omvendt.
Så lad os endnu en gang se på filmanbefalinger og de personlige miniaturebilleder – hvad er problemet eller forretningsmålet?

Filmanbefalinger: Identificering af problemet
Her er problemet, at Netflix har en enorm samling af indhold (over 100 millioner forskellige produkter, ifølge Netflix), som konstant ændrer sig og kan være overvældende for en bruger at forbruge. Brugerne ønsker ikke at blive frustreret over at skulle finde indhold, der er relevant for deres interesser. Så hvad er den bedste måde at give den enkelte bruger mulighed for at forbruge disse data på en måde, der i sidste ende maksimerer abonnementsloyaliteten?
Produktmålene omfatter:
- Stigning / opretholdelse af seertal i form af antal forbrugte minutter,
- Stigning i antal udforskede titler, hyppighed af at logge ind igen
- Overskridelse af en hvilken som helst minimumstærskel, som virksomheden bestemmer, er en succesmetrik
- Gennemsnitlig stigning i loyalitet over for månedlige abonnementer / fald i opsigelser af abonnenter
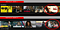
Personaliserede billedminiaturer/kunstværker: Identificering af problemet
Denne brugssituation er en delmængde af filmanbefalinger. Eftersom der gives filmanbefalinger til brugeren, har vi nu endnu et forretnings-/brugerproblem.
Problem: Hvordan (og hvornår) præsenterer vi bedst denne filmanbefaling for brugeren på en måde, der maksimerer seertallet og den månedlige abonnentloyalitet?
En måde at give denne anbefaling på er gennem en billedminiature – men hvilken slags miniature skal vi give? Og hvor sikre er vi på, at det vil påvirke seertallet eller abonnentloyaliteten positivt, hvis vi justerer en billedminiature?
Og hvor vigtig er miniaturebilledet? Har vi data til det?
Indsamling af data til støtte for hypotesen
Du kan være sikker på, at en produktfokuseret person hos Netflix – på et tidspunkt før 2014 – stillede præcis de samme spørgsmål internt. Og denne person eller gruppe arbejdede sammen (sandsynligvis med UX og relaterede interessenter) for at sammensætte brugerundersøgelser eller data andre steder for at bevise, at der faktisk var en stærk sammenhæng mellem en billedminiatur og seertal.
Det var deres hypotese: at justeringen af det kunstneriske indhold af en billedminiatur kunne have en stærk sammenhæng med seertal.
Det viser sig, at Netflix tilbage i 2014 gennemførte undersøgelser, der viste, hvor vigtig miniaturebilledet er:
Nick Nelson, Netflix’ globale chef for kreative tjenester, forklarede, at virksomheden i begyndelsen af 2014 gennemførte undersøgelser, der viste, at kunstværket “ikke kun var den største påvirkningsfaktor” for en brugers beslutning om, hvad han/hun ville se, men at det også udgjorde over 82 procent af deres fokus, mens de surfede på Netflix.
“Vi så også, at brugerne i gennemsnit brugte 1,8 sekunder på at overveje hver enkelt titel, de blev præsenteret for, mens de var på Netflix”, skrev Nelson. “Vi blev overrasket over, hvor stor betydning et billede havde for, at et medlem kunne finde godt indhold, og hvor lidt tid vi havde til at fange deres interesse.”
En lille, overbevisende miniature kan betyde forskellen mellem at få dig til at bruge hele weekenden på at se Netflix’ seneste Originals-hit eller miste interessen og hoppe over til en konkurrerende tjeneste som Hulu eller lignende OTT-streamingtjenester som ESPN / Disney / HBO Go.”
Så baseret på undersøgelser viste ovenstående hypotese sig at være meget sand.”
OK, miniaturebilleder er vigtige. Men hvad præcis skal vi justere?
Og hvordan bliver et ustruktureret datasæt som en masse billedminiaturer fodret ind i en digital/matematisk maskinlæringsmodel? Vi besvarer dette andet spørgsmål længere nede.
For det første, i betragtning af hvor vigtig miniaturebilledet var for en brugers beslutning om at se noget, hvordan kan Netflix generere bedre miniaturebilleder for hver bruger for at øge chancen for, at en bruger vil se en video?
Det vil højst sandsynligt ikke give de højeste klikrater at bruge filmens originale kunst som det eneste miniaturebillede, der bruges til hver enkelt person. Virksomheden efterlader sandsynligvis klik (og seernes streamtid) på bordet!
Hvad nu hvis Netflix brugerdefineret skabte en anden miniature for hver bruger, som er optimeret til at øge klikraten?
Hvad er der for ting i en billedminiature, som Netflix har kontrol over, og som de kan justere for at øge klikraten?

Hvilken skuespiller(e)/karakter(er) skal være på den pågældende miniaturebillede, hvis nogen? Hvor mange? Hvilken automatisk genereret ramme eller plakatvariant ville være mest tillokkende for en bestemt bruger at klikke på? Hvilken belysning virker bedst? Filtre?
Hvilke data har vi om andre brugeres tidligere klikadfærd, som vi kan drage associationer fra for at hjælpe med at informere denne thumbnail-beslutning på skala?
- Stigning af click-thru-rates (CTR) for filmanbefalinger – tegn på engagement
- Hypotese om, at højere engagementrater vil føre til højere abonnenttilfredshed og loyalitet
Så dette er et virkelig interessant problem med billedminiaturen, der kan have en enorm indvirkning på sandsynligheden for, at nogen klikker på en video og ser den.
Hvis målet er at maksimere sandsynligheden for at se ved at justere miniaturebilledet – hvilke produktbeslutninger skal man så overveje?
Produktovervejelser i forbindelse med personaliserede billedminiaturer
Vi vil ikke dykke ned i hver af de ovennævnte brugssituationer, men lad os dykke lidt længere ned i den anden: Artwork / Thumbnail Personalization
Dette er en datadrevet personaliseringsfunktion, der sidder oven på Movie Recommendation Engine
Produktovervejelser
Algoritmer er fantastiske, men de har begrænsninger. En produktchef bør altid tænke forud for mulige edge case-scenarier, hvor algoritmen måske ikke opnår de bedste resultater.
- Hver film bør ideelt set have en personlig miniature, der maksimerer klik. Da Netflix har data om klikadfærd hos andre personer med lignende interesser, er det en rimelig hypotese at gætte på, at hvis andre personer med lignende interesser og se-historik havde en høj klikrate på en bestemt miniature, så er det sandsynligt, at denne billedminiature vil præstere vil præstere på en ny person, som endnu ikke er blevet anbefalet denne film / miniature.
- Den personlige miniature bør tage hensyn til andre film der bliver anbefalet på samme tid – og hvad disse billedanbefalinger er. Lad os sige, at Netflix anbefaler 2 forskellige Spiderman-film til en bruger side om side – og at de begge har Spiderman med kameramasken afvendt. Den ene er Tobey Maguire og den anden er Andrew Garfield. Ville det ikke være mærkeligt for brugeren at se begge portrætter af Maguire og Garfield som Spiderman med maskerne af – side om side? Noget at tage højde for, hvis det nogensinde skulle ske.
Et enkelt miniaturebillede kunne fungere godt isoleret set, men det er måske ikke godt nok, når der vises en side med et dusin miniaturebilleder. Hvis de alle er optimeret til at se ens ud, så kan de som gruppe virke mindre overbevisende hver for sig. Så det vil være vigtigt at se på hvert enkelt miniaturebillede sammen med det, der ellers præsenteres. - Data er godt, men pas på med algoritmer, der gør deres arbejde for godt, hvilket resulterer i utilsigtede konsekvenser/falsk positive resultater!
I statistikken kalder man dette en type I-fejl – at man fejlagtigt (eller ukorrekt) foreslår en miniature af et billede, som ikke burde foreslås.
Et eksempel herpå: Se bare på eksemplet nedenfor med Like Father, en film med Kristen Bell i hovedrollen. Alligevel lavede Netflix’ algoritme (vistnok) falske thumbnail-anbefalinger af understøttende sorte skuespillere/skuespillerinder, som ikke rigtig repræsenterer det, som filmen handlede om, men som oplevede en højere klikrate blandt visse etniske målgrupper.

Så vær opmærksom på, at en alt for optimeret/personaliseret oplevelse kan skabe en monoton brugeroplevelse, der i nogle tilfælde kan være misvisende for brugeren. Vi ønsker at give en sund blanding af det velkendte med det uventede, men også at skildre indholdet præcist for brugeren, så de ikke bliver uretmæssigt vildledt.
Her er et andet eksempel:
Baseret på høj sandsynlighed for click-thru-rates (CTR’er) endte Netflix med at præsentere miniaturebilleder for brugere, der matchede en brugers etnicitet – – – selv når den pågældende (normalt) bærende skuespiller/skuespillerinde kun havde meget lidt screentime i den pågældende film.
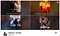
Selv om dette er et datastøttet initiativ, er det helt tydeligt for brugeren, at der er en følelse af uoprigtighed, som kan være vildledende i forhold til, at en miniaturebillede repræsenterer den pågældende film præcist (type I falsk positiv fejl).
Selvfølgelig vil denne algoritme sandsynligvis blive finjusteret med tiden, men læren her er, at man ikke skal overdrive, når man udnytter data – anvend noget sund fornuft for at afbalancere det.
Vi ønsker ikke at vildlede brugerne uretmæssigt eller lade dem vide, at de bliver behandlet anderledes på grund af f.eks. deres race.
4. Endelig bør algoritmen tage hensyn til, hvilke miniaturebilleder brugeren tidligere har set i forbindelse med denne film, og tilstræbe at give en ensartet, ikke-forvirrende brugeroplevelse.
Vi ønsker at undgå, at brugeren ser forskellige miniaturebilleder, hver gang denne film vises for brugeren. Det ville ikke blot forvirre brugeren, men det ville også gøre det vanskeligt for en produktchef at tildele et klik en tilskrivning – hvilket billede resulterede i en højere klikfrekvens (CTR), når det hele tiden skifter? PM’er skal kunne tildele hvert nyt resultat korrekt til en specifik ændring – så det er vigtigt at opretholde en konsistent datatilskrivning.
Så det er nogle ting, som en produktchef ville overveje, når han/hun udformer edge case-scenarier, og hvad ekstreme tilfælde af dataforbrug kan resultere i. Apropos data, hvad arbejder Netflix specifikt ud fra?
Hvilke data har vi?
Der er 2 dele til dette:
- Hvilke data bruger Netflix til at oprette disse personlige miniaturebilleder/kunstværker?
- Hvilke data bruger Netflix til at målrette disse specialfremstillede miniaturebilleder til den relevante person?
For det første spørgsmål skal du tænke på, at
- En 1 times episode af Stranger Things har >86.000 statiske videorammer
- Disse videorammer kan hver især tildeles visse attributter, der senere bruges til at filtrere ned til de bedste thumbnail-kandidater gennem et sæt værktøjer og algoritmer kaldet Aesthetic Visual Analysis (AVA). Dette er designet til at finde det bedste brugerdefinerede miniaturebillede ud af hvert statisk billede i videoen
- Netflix-annotation – Netflix opretter metadata for hvert billede, herunder lysstyrke (.67), antal ansigter (3) , hudfarver (.2), sandsynlighed for nøgenhed (.03), grad af bevægelsesudsløring (4), symmetri (.4)
- Netflix Image Ranking – Netflix bruger metadataene fra ovenstående til at udvælge specifikke billeder, der er af højeste kvalitet (god belysning, ingen motion blur, indeholder sandsynligvis et eller andet ansigtsbillede af hovedpersoner fra en anstændig vinkel, indeholder ikke uautoriseret branded content osv.) og mest klikbare
For det andet spørgsmål om, hvilke data Netflix bruger til at identificere, hvem de skal målrette disse brugerdefinerede genererede miniaturebilleder mod, skal du overveje, at Netflix sporer:
- # sete film, antal minutter af hver serie, der er set
- % fuldført for hver video/serie
- # upvotes, hvilke film der blev favoriseret osv
- % af det samlede indhold, der kan tilskrives en specifik serie (og dermed graden af affinitet, som brugeren har til en specifik serie eller relaterede skuespillere)
- nogle sæsonmæssige eller ugentlige tendenser i forbindelse med en brugers engagement osv.
Interessant at bemærke er, at Netflix i midten af 2018 stoppede med at acceptere brugeranmeldelser som et datapunkt, som de tidligere kun havde bedt om på deres websted. Hvorfor? Fordi denne “funktion” faktisk reducerer seertallet, da negative anmeldelser afskrækker brugerne fra at prøve en video. Dette er blot endnu et eksempel på, hvordan et forretningsbehov går forud for et populært brugerbehov!
Så Netflix har et TON af data om hver enkelt af sine kunder – fra sete videoer til klikkede billeder. Hvad gør de med alle disse data?
Hvordan Netflix bruger data til at konstruere et univers af brugerprofilinteresser
Ja, de bruger dem til at sammensætte en 360-profil af hver bruger og matematisk indeksere hver bruger i henhold til hundredvis, muligvis tusindvis af forskellige attributter.
Det gør de for at forsøge at gruppere folk med lignende interesser sammen, så de kan bruge data fra én bruger til at hjælpe med at forudsige andre lignende brugeres sandsynlige adfærd.
Hvordan fungerer denne gruppering af lignende brugerprofiler, og hvordan giver en produktchef mening med disse data?
Har jeg gennemgået den komplekse matematik og de algoritmer, der er forbundet med matricer, vektorer og n-dimensionel funktionsanalyse, fandt jeg ud af, at den nemmeste måde at forstå, hvordan dette fungerer, er gennem en 3D-rumlig repræsentation af 10+ dimensioner.
Her er et skærmbillede, jeg tog, da jeg brugte Googles TensorBoard på mNIST-databasen med håndskrevne cifre. Det er et smart plot kaldet t-SNE-plot – effektivt en 3D-repræsentation af en meget flere dimensioner end blot 3. I dette tilfælde viser vi 10 dimensioner (en for hvert ciffer fra 1 til 10) på et 3D-sfærelignende koordinatsystem.
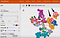
Hvert håndskrevet tals position i denne rumlige repræsentation kan beskrives ved en vektor – en koordinatlignende række af tal på tværs af hvor mange funktionsdimensioner som helst.
Sådan kunne hver brugerprofilens position i ovenstående diagram med Netflix-brugere ligeledes beskrives ved numeriske værdier, der hver især repræsenterer en individuel dimension af den pågældende brugers interesse – herunder filmgenre, yndlingsskuespillere/skuespillerinder, filmemne osv.
Reimagining Netflix Users in Mathematical Relation To Each Other
Lad os lade som om, at i det ovenstående taldiagram, at:
- “6” = romantisk komedie
- “4” = thriller
Hvis en bruger bliver betegnet som en “6” af Netflix, så vil han/hun blive placeret i den generelle nærhed af, hvor alle de andre turkise 6’ere befinder sig i ovenstående rumlige repræsentation (nær bunden).
Sådan vil en bruger, hvis han/hun af Netflix bliver betegnet som et “4”, blive placeret i den generelle nærhed af, hvor alle de andre magenta 4’ere befinder sig i ovenstående rumlige repræsentation (nær toppen).

Bemærk, hvordan det turkise “6”-område (romantisk komedie) overlapper noget med det grå “5”-område. Dette kunne være analogt med, at brugere, der kan lide romantiske komedier, også kan lide parodi- eller satirefilm, fordi de begge involverer grin.
Det samme gælder, da den magenta “4”-region (thriller) ligger noget tæt på den lyserøde “9”-region – denne lyserøde 9-region kunne repræsentere dem, der kan lide actionfilm – matematisk set tættere på thriller “4”-regionen end på den romantiske komedie “6”-regionen.
Giver det mening? Så når afstanden mellem to brugerprofiler repræsenteres rumligt, repræsenterer afstanden mellem to brugerprofiler, hvor ens/forskellig deres smag er. Selvfølgelig kan dette blive uendeligt meget mere komplekst, når en person, der kan lide romantiske komedier, også kan lide thrillere – men formålet med denne analogi er at vise den generelle idé om matematiske / rumlige relationer mellem forskellige kategorier.
Interessegrupper, der er relateret til hinanden, ville fremstå tættere på hinanden og kunne være gode forudsigere af, hvad en bruger vil kunne lide, givet at brugeren kan lide noget andet i nærheden.
Det er sådan Netflix, eller virkelig enhver virksomhed, der udnytter ML-modeller, skaber relationer mellem tilsyneladende ustrukturerede data og omdanner disse data til tal. Disse tal giver ikke meget mening i sig selv, men sammen i forhold til hinanden begynder de at give mening.
For den samme Good Will Hunting-film nedenfor vil en bruger, der er identificeret som en komediefan, få vist et miniaturebillede af Robin Williams (komiker), mens en anden bruger, der er identificeret som en fan af en romantisk komedie, vil få vist et miniaturebillede af et kys med Matt Damon og Minnie Driver. Selv om det ikke er perfekt, tyder Netflix’ algoritmer på, at et sådant niveau af personalisering baseret på brugerprofilens karakteristika øger sandsynligheden for klikfrekvens.

Så lad os opsummere. En masse Netflix-billedminiaturer er en masse ustrukturerede data.
Men når Netflix annoterer hvert miniaturebillede og tildeler metadata til hvert enkelt for at beskrive, hvad der er i det pågældende miniaturebillede – så har vi nu en numerisk repræsentation af disse ustrukturerede data.
Plot denne numeriske repræsentation i form af vektorer på tværs af en 3D-sfære, som vi gjorde ovenfor – og nu begynder Netflix at danne relationer mellem datapunkterne.
Netflix finder derefter datapunkter, der ligger relativt tæt på hinanden, og bruger dem til at forudsige fremtidig klikadfærd. Hvis forudsigelserne viser sig at være dårlige eller gode, justerer de den matematiske placering af disse karakteristika i overensstemmelse hermed, indtil modellen bliver bedre og bedre over tid.
Sådan forvandler Netflix ustrukturerede data til matematiske repræsentationer. De bruger den relationelle afstand mellem datapunkter som grundlag for at lave og forbedre anbefalinger af miniaturebilleder.
Hvad har Netflix lært af alle disse data?
Når vi nu ved, hvordan Netflix omdanner billeder til tal i en maskinlæringsmodel, hvad er så nogle indsigter, som Netflix har fundet ud af alle de databehandlinger og A/B-tests, de har udført i så mange år?
Jamen, ud over at lære de millioner af individuelle miniaturebilleder, der konverterede brugere til loyale abonnenter over tid, er her et par yderligere ting, som Netflix har lært om, hvad der virker med hensyn til miniaturebilleder:
- Vis nærbilleder af følelsesmæssigt udtryksfulde ansigter
- Vis folk skurke i stedet for helte
- Vis ikke mere end tre karakterer
I konklusion: Netflix implementerede AI (for det meste) på den rigtige måde. Lad os lære af deres tilgang.
Netflix har gjort et fænomenalt stykke arbejde med at anvende AI, datalogi og maskinlæring på den “rigtige måde” – ved hjælp af en produktbaseret tilgang, der fokuserer på forretningsbehovet først og derefter AI-løsningen, snarere end omvendt.
Når AI anvendes korrekt, kan den gøre underværker.
Vi har set, hvor effektive AI-løsninger kan være til at personliggøre oplevelsen til gavn for både Netflix i form af abonnementer og brugerne i form af generel tilfredshed.
Vi har også set begrænsninger ved algoritmer, der “overdriver”, og vi har diskuteret specifikke eksempler, hvor Netflix-algoritmen præsenterede misvisende miniaturebilleder for farvede personer, fordi algoritmen optimerede for klik, hvilket effektivt “narrede” brugerne til at klikke på lokkemad. Dette skete, selv om miniaturebilledet ikke repræsenterede den pågældende video nøjagtigt.
Ingen algoritme vil være perfekt til at tage højde for alle nuancerne i en menneskelig oplevelse. Faktisk vil algoritmer, der er designet til at udnytte målinger, gøre netop dette – så det er produktchefens rolle at arbejde sammen med design eller andre teammedlemmer for at finde måder at løse disse mangler i algoritmerne på.
Fremadrettet vil integrationen af AI i samfundet såvel som i virksomhedsområdet fortsat blive mere og mere udbredt.
Teknologer har måske en tendens til at foreskrive eksisterende AI-løsninger, men i virkeligheden er den mest effektive måde at indføre AI på den måde, som Netflix gjorde det – først og fremmest ud fra et forretningsdrevet perspektiv.
Grav dybt, og du vil se, at Netflix genererede understøttende data, før de tog det strategiske skridt fremad.
Da verden af AI, datavidenskab og maskinlæring fortsætter med at vokse, kan vi produktchefer alle tage en lektion eller to fra Netflix’ playbook, når det kommer til korrekt implementering af AI-løsninger.