
Tekoälyn läsnäolosta nyky-yhteiskunnassa on tulossa yhä jokapäiväisempää – erityisesti, kun suuret yritykset, kuten Netflix, Amazon, Facebook, Spotify ja monet muut, ottavat jatkuvasti käyttöön tekoälyyn liittyviä ratkaisuja, jotka ovat suorassa vuorovaikutuksessa (usein kulissien takana) kuluttajien kanssa joka päivä.
Kun näitä tekoälyyn liittyviä ratkaisuja sovelletaan oikein liiketoimintaongelmiin, ne voivat tarjota todella uniikkeja ratkaisuja, jotka skaalautuvat ja parantavat toimintaa ajan mittaan luoden näin merkittävän vaikutuksen sekä yritykselle että käyttäjälle. Mutta mitä tarkoittaa tekoälyratkaisun ”asianmukainen soveltaminen”? Tarkoittaako se, että on olemassa väärä tapa? Tuotteen näkökulmasta lyhyt vastaus on kyllä, ja selvitämme miksi näin on myöhemmin tässä artikkelissa, kun menemme syvemmälle.
Yleiskatsaus: Aluksi hahmotellaan 5 datatieteen tai koneoppimisen käyttötapausta Netflixissä. Sitten keskustelemme joistakin liiketoiminnan tarpeista vs. teknisistä näkökohdista, joita tuotepäällikkö tarkastelee. Sitten sukellamme hieman syvemmälle siihen, mikä on ehkä mielenkiintoisin näistä viidestä käyttötapauksesta, kun tunnistamme, mitä liiketoimintaongelmaa sillä pyritään ratkaisemaan.
1. Rakennetaan yksinkertainen neuroverkko!
2. Päätöspuut koneoppimisessa
3. Intuitiivinen johdatus koneoppimiseen
4. Passiivisen vs. aktiivisen tekoälyn tasapaino.
5 tekoälyn/datan/koneoppimisen käyttötapauksia Netflixissä
- Elokuvasuositusten personointi – Käyttäjät, jotka katsovat A:ta, katsovat todennäköisesti B:tä. Tämä on ehkä Netflixin tunnetuin ominaisuus. Netflix käyttää muiden samankaltaisen maun omaavien käyttäjien katseluhistoriaa suositellakseen, mitä sinua kiinnostaa ehkä eniten katsoa seuraavaksi, jotta pysyt mukana ja jatkat kuukausittaista tilaustasi lisää.
- Pikkukuvien/taidekuvien automaattinen generointi ja personointi – Netflix käyttää tuhansia videokuvia olemassa olevasta elokuvasta tai näytöksestä lähtökohtana pikkukuvien generoinnissa, ja Netflix tekee näihin kuviin huomautuksia, minkä jälkeen se asettaa jokaisen kuvan paremmuusjärjestykseen yrittäessään tunnistaa, mitkä pikkukuvat johtavat suurimmalla todennäköisyydellä klikkaukseesi. Nämä laskelmat perustuvat siihen, mitä muut sinun kaltaisesi ovat klikanneet. Yksi havainto voisi olla, että käyttäjät, jotka pitävät tietyistä näyttelijöistä/elokuvagenreistä, klikkaavat todennäköisemmin pikkukuvia, joissa on tiettyjä näyttelijöitä/kuvaominaisuuksia.
- Elokuvatuotannon kuvauspaikkojen etsintä (esituotanto) – Tietojen käyttäminen apuna päättäessä, missä ja milloin on parasta kuvata elokuvan kuvauspaikat, kun otetaan huomioon aikatauluun (näyttelijöiden ja kuvausryhmän saatavuus), budjettiin (tapahtumapaikkaan, lento- ja hotellikustannuksiin) ja tuotantokohtauksen vaatimuksiin (päivä- tai yökuvaus ja sääolosuhteiden aiheuttamien riskien esiintyminen paikanpäällä…) liittyvät rajoitukset. Huomaa, että tämä on enemmänkin datatieteen optimointiongelma kuin koneoppimismalli, joka tekee ennusteita aiempien tietojen perusteella.
- Elokuvan editointi (jälkituotanto) – Historiatietojen käyttäminen siitä, milloin laadunvalvontatarkistukset ovat epäonnistuneet aiemmin (kun tekstityksen synkronointi ääniin/liikkeisiin ei ole ollut kunnossa aiemmin) – jotta voidaan ennustaa, milloin manuaalisesta tarkistuksesta on suurin hyöty muutoin hyvinkin aikaavievässä ja työläässä prosessissa.
- Suoratoiston laatu – Aiempien katselutietojen käyttäminen kaistanleveyden käytön ennustamiseen, jotta Netflix voi päättää, milloin alueelliset palvelimet voidaan tallentaa välimuistiin nopeampien latausaikojen saamiseksi (odotettavissa olevan) kysynnän huipun aikana.
Näillä viidellä käyttötapauksella/sovelluksella, jotka koskevat datatieteiden tai koneoppimisen hyödyntämistä pelkästään Netflixissä, on ollut niin skaalautuva vaikutus, että ne ovat muuttaneet ikuisiksi ajoiksi teknologiakenttää ja miljoonien käyttäjien käyttäjäkokemusta, ja niitä on luvassa vielä lisää. Näiden tekoälyyn liittyvien ratkaisujen omaksuminen tulee vain vahvistumaan ajan mittaan.
Mutta ennen kuin nämä käyttötapaukset olivat niin arkipäiväisiä kuin ne ovat nykyään, ja niitä käyttivät kaltaisesi käyttäjät, kuten sinä ja minä, joku tai joku ryhmä Netflixissä yhdisti nämä tekoälyratkaisut asianmukaisesti liiketoiminnalliseen tarpeeseen. Ilman tätä liiketaloudellista yhteyttä nämä käyttötapaukset olisivat pelkkiä ”pie-in-the-sky” -ideoita, jotka istuisivat backlogin pohjalla kuten niin monet muutkin hienot ideat. Vain oikeanlaisen asemoinnin ja Netflixin keskeiseen liiketoimintaongelmaan liittämisen ansiosta näistä ideoista tuli todellisuutta, jota ne ovat nyt.

- Mikä on liiketoiminnan tarve/ongelma?
- Leffasuositukset: Ongelman tunnistaminen
- Henkilökohtainen kuvan pikkukuva / taideteos: Ongelman tunnistaminen
- Okei, pikkukuvat ovat tärkeitä. But What Exactly Do We Tweak?
- Tuotepohdintoja personoiduissa kuvien pikkukuvissa
- Mitä dataa meillä on?
- Miten Netflix käyttää dataa rakentaakseen käyttäjäprofiilin kiinnostuksen kohteiden maailmankaikkeuden
- Netflix-käyttäjien kuvitteleminen uudelleen matemaattisessa suhteessa toisiinsa
- Mitä Netflix oppi kaikesta tästä datasta?
- Johtopäätöksinä: Netflix käytti tekoälyä (enimmäkseen) oikealla tavalla. Opitaan heidän lähestymistavastaan.
Mikä on liiketoiminnan tarve/ongelma?
Huomaa, että jokaisessa edellä tunnistamassani käyttötapauksessa jokainen liittyy tiettyyn liiketoimintatarpeeseen, tavoitteeseen tai hypoteesiin.
Tämä on ehdottoman tärkeää jokaiselle tuotepäällikölle – välttää tekniikan harrastajan kiusausta, joka ihmettelee datatieteen / tai ML:n yksityiskohtia älyllisistä syistä tunnistamatta selkeästi ongelmaa tai liiketoimintatarvetta – ja mahdollisesti käyttää arvokkaita teknisiä resursseja ilman liiketoiminnallista vaikutusta.
Tuotepäälliköiden on viime kädessä yhdistettävä liiketoimintaongelma kunnolla datan koneoppimisratkaisuun. Haluamme välttää sitä, että ratkaisu jahtaa ongelmaa, muuten hanke menettää vauhtia yrityksessä: insinöörit eivät ole selvillä siitä, mikä on heidän Pohjantähtensä, sidosryhmät eri puolilla organisaatiota eivät osallistu ja kohdista tarvittavia resursseja, jotta hanke onnistuisi jne.
Varmista, että on olemassa ongelma, johon tekoälyratkaisu voidaan suoraan liittää
Koneoppiminen (ML) on potentiaalinen tekoälyratkaisu – mutta meidän on ensin määriteltävä ongelma, ennen kuin voimme määrätä kyseisen ratkaisun.
Mitä liiketoiminnallista tulosta yritämme saavuttaa ML:n avulla? Koska tämä liiketoiminnan ydintarve ohjaa käytettävien ML-mallien parametreja, mitä tietoja kerätään ja käsitellään jne. Emme tee ML:ää tarjotaksemme personointia vain siksi, että se on mielenkiintoista tekniikkaa – meidän on yhdistettävä se liiketoimintaongelmaan. Data-asiantuntijat ovat asiantuntijoita, jotka pystyvät löytämään datasta oivalluksia, mutta tuotepäällikön tehtävänä on yhdistää se asianmukaisesti liiketoiminnan tarpeeseen tai ongelmaan ja verrata sitä kilpaileviin prioriteetteihin.
Tekniikan harrastaja voisi esimerkiksi sanoa:
Eikö olisi siistiä, jos voisit analysoida / väitellä jaksosta äänellä Netflixin kanssa – ja Netflix voisi tuhansista muiden käyttäjien reaktioista kyseiseen jaksoon saadun datan avulla vastata älykkäästi kommentteihisi edestakaisessa kaksisuuntaisessa vuoropuhelussa?
Joo, se olisi aika mahtava käyttötapaus, jossa hyödynnettäisiin luonnollisen kielen prosessointia (NLP) ymmärtämään jakson jälkeistä kommenttiasi kontekstissa. NLP:n lisäksi tässä käyttötapauksessa hyödynnetään tekstin ja äänen välisiä persoonallisuuksia sekä sentimenttianalyysiä siitä, miten tuhannet muut kokivat sen, mitä kyseisessä jaksossa tapahtui, tai mitä mieltä he ovat tietystä hahmosta. Kyseessä on todellakin useiden huipputekniikoiden hieno yhdistäminen yhdessä käyttötapauksessa.
Jos tämän MVP-pilottiversio osoittaisi, että käyttäjät, jotka käyttivät hänen uutta ominaisuuttaan, pysyivät pidempään tai palasivat useammin tai auttoivat lisäämään Netflixin suusanallista mainontaa, se saattaisi ansaita lisäresursseja. Alkuperäinen päätös MVP:n rakentamisesta riippuisi sidosryhmien tekemästä strategisesta päätöksestä, jota ei välttämättä priorisoitaisi mittarin perusteella. Se riippuu yrityksen strategiasta.
Mutta niin kaunis käyttäjäskenaario kuin yllä oleva on, minkä ongelman se ratkaisee?
Miten se liittyy Netflixin pääongelmaan eli siihen, että käyttäjät pysyvät kuukausittain tilaajina? Jos se liittyy, mitä todisteita (laadullisia tai määrällisiä) meillä on tuon suhteen tueksi?
Ja jos tämä on oikeutettu ratkaisu kyseiseen ongelmaan, onko olemassa yksinkertaisempaa versiota tästä ratkaisusta, joka voisi yhtä lailla ratkaista kyseisen ongelman mutta olisi teknisesti vähemmän monimutkainen? Esimerkiksi, miten pelkän tekstinsyötön ja tekstitulostuksen monimutkaisuus voisi vaikuttaa vaivannäköön ja vaikutukseen käyttäjien sitoutumiseen?
Mitä jos keskusteleva tekoälykäyttöliittymä ilman ääniosuutta (pelkkä teksti) saavuttaisi 80 % tavoitellusta käyttäjien sitoutumisesta, mutta vaatisi vain 40 % kehitystyöstä? Kannattaisiko tällaista vaihtoehtoista reittiä harkita?
Millainen vaikutus tällaisella ratkaisulla olisi liiketoimintaan verrattuna työmäärään? Miten tätä suhdetta verrataan muihin kilpaileviin tehtäviin backlogissa?
Nämä ovat kaikki tuotekeskeisiä kysymyksiä, joita PM:n pitäisi kysyä, jotta teknologiaratkaisut voidaan sovittaa yhteen liiketoiminnan tarpeiden kanssa. Koska viime kädessä liiketoimintatarpeet ohjaavat ML-mallin parametreja, ei päinvastoin.
Katsotaanpa siis vielä kerran elokuvasuosituksia ja noita personoituja pikkukuvia – mikä on ongelma tai liiketoiminnan tavoite?

Leffasuositukset: Ongelman tunnistaminen
Tässä ongelmana on se, että Netflixillä on valtava kokoelma sisältöä (Netflixin mukaan yli 100 miljoonaa erilaista tuotetta), joka muuttuu jatkuvasti ja jonka kuluttaminen voi olla käyttäjälle ylivoimaista. Käyttäjät eivät halua turhautua etsiessään kiinnostuksen kohteisiinsa sopivaa sisältöä. Mikä on siis paras tapa antaa kullekin käyttäjälle mahdollisuus käyttää tätä tietoa tavalla, joka lopulta maksimoi tilaususkollisuuden?
Tuotteen tavoitteisiin kuuluvat:
- Katsojamäärän kasvattaminen / säilyttäminen kulutettujen minuuttien määrässä,
- Tutkittujen nimikkeiden määrän kasvattaminen, uudelleenkirjautumistiheys
- Ylittää se vähimmäiskynnys, jonka yritys määrittelee menestysmittariksi
- Kokonaisuutena kuukausittaisen tilaususkollisuuden lisääminen / tilaajien peruutusten vähentäminen
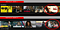
Henkilökohtainen kuvan pikkukuva / taideteos: Ongelman tunnistaminen
Tämä käyttötapaus on elokuvasuositusten osajoukko. Koska elokuvasuositukset annetaan käyttäjälle, meillä on nyt vielä yksi liiketoiminta- / käyttäjäongelma.
Ongelma: Miten (ja milloin) esitämme elokuvasuosituksen käyttäjälle parhaalla mahdollisella tavalla siten, että maksimoidaan katsojamäärät ja kuukausittainen tilaajamäärä?
Yksi tapa antaa suositus on kuvien pienoiskuvien avulla – mutta minkälaisen pienoiskuvan annamme? Ja kuinka varmoja olemme siitä, että kuvan pikkukuvan muokkaaminen vaikuttaa katsojamääriin tai tilaajauskollisuuteen positiivisella tavalla?
Ja kuinka tärkeä tuo pikkukuva on? Onko meillä siitä tietoa?
Datan kerääminen hypoteesin tueksi
Voitte olla varmoja siitä, että joku Netflixin tuotekeskeinen henkilö – joskus ennen vuotta 2014 – kyseli sisäisesti juuri näitä samoja kysymyksiä. Ja tämä henkilö tai ryhmä teki yhteistyötä (luultavasti UX:n ja siihen liittyvien sidosryhmien kanssa) kootakseen käyttäjätutkimuksia tai dataa muualla todistaakseen, että kuvan pikkukuvan ja katsojamäärien välillä oli todellakin vahva yhteys.
Se oli heidän hypoteesinsa: että kuvan pikkukuvan taiteellisen sisällön säätämisellä voisi olla vahva yhteys katsojamääriin.
Nyt kävi ilmi, että jo vuonna 2014 Netflix teki tutkimuksia, jotka osoittivat, kuinka tärkeä tuo pikkukuva on:
Nick Nelson, Netflixin luovien palveluiden globaalijohtaja, selitti, että yhtiö teki vuoden 2014 alussa tutkimuksen, jonka mukaan taideteos ei ollut ”vain suurin vaikuttaja” käyttäjän päätökseen siitä, mitä hän katsoo, vaan se myös muodosti yli 82 prosenttia hänen keskittymisestään, kun hän selaili Netflixiä.
”Huomasimme myös, että käyttäjät käyttivät Netflixissä ollessaan keskimäärin 1,8 sekuntia jokaisen heille esitetyn nimikkeen tarkasteluun”, Nelson kirjoitti. ”Olimme yllättyneitä siitä, miten suuri vaikutus kuvalla oli siihen, että jäsen löysi hyvää sisältöä, ja siitä, miten vähän aikaa meillä oli aikaa herättää heidän kiinnostuksensa.”
Pieni, vakuuttava pikkukuva voi merkitä eroa sen välillä, vietätkö koko viikonlopun katsomalla Netflixin uusimman Originals-hitin vai menetätkö kiinnostuksesi ja siirryt kilpailevaan palveluun, kuten Huluun tai vastaaviin OTT-suoratoistopalveluihin, kuten ESPN/Disney/HBO Go:hon.”
Tutkimusten perusteella yllä oleva hypoteesi osoittautui siis hyvin paikkansapitäväksi.”
Okei, pikkukuvat ovat tärkeitä. But What Exactly Do We Tweak?
Ja miten strukturoimaton datajoukko, kuten joukko kuvien pikkukuvia, syötetään digitaaliseen/matemaattiseen koneoppimisen malliin? Vastaamme tähän jälkimmäiseen kysymykseen alempana.
Ensiksi, kun otetaan huomioon, kuinka tärkeä pikkukuva oli käyttäjän päätökselle katsoa jotain, miten Netflix voi luoda parempia pikkukuvia jokaiselle käyttäjälle, jotta se lisäisi todennäköisyyttä, että käyttäjä katsoo videon?
Elokuvan alkuperäisen taiteen käyttäminen ainoana pikkukuvana, jota käytetään jokaiselle yksittäiselle henkilölle, ei todennäköisesti tuota korkeimpia klikkausprosentteja. Yritys jättää todennäköisesti klikkauksia (ja katsojien suoratoistoaikaa) pöydälle!
Mitä jos Netflix loisi kustomoidusti jokaiselle käyttäjälle erilaisen pikkukuvan, joka on optimoitu lisäämään klikkausprosenttia?
Mitä asioita kuvien pikkukuvassa on Netflixin kontrolloitavissa, joita se voi säätää klikkausprosentin nostamiseksi?

Minkä näyttelijän/näyttelijöiden/hahmojen pitäisi olla tuossa pikkukuvassa, jos sellaisia on? Kuinka monta? Mikä automaattisesti luotu kehys- tai julistevariaatio houkuttelisi tiettyä käyttäjää klikkaamaan sitä? Mikä valaistus toimii parhaiten? Suodattimet?
Mitä tietoja meillä on muiden käyttäjien aiemmasta klikkauskäyttäytymisestä, joista voimme vetää assosiaatioita, jotta voimme auttaa tekemään tämän pikkukuvapäätöksen mittakaavassa?
- Nostaa elokuvasuositusten klikkausprosenttia (CTR) – merkitsee sitoutumista
- Hypoteesi, jonka mukaan korkeammat sitoutumisprosentit johtavat korkeampaan tilaajatyytyväisyyteen ja -uskollisuuteen
Tämä on siis todella mielenkiintoinen ongelma, joka liittyy kuvien pienoiskuviin ja jolla voi olla valtava vaikutus siihen, miten todennäköisesti joku klikkaa videota ja katsoo sen.
Jos tavoitteena on maksimoida katsomisen todennäköisyys muokkaamalla pikkukuvaa – mitä tuotepäätöksiä on otettava huomioon?
Tuotepohdintoja personoiduissa kuvien pikkukuvissa
Emmekä aio sukeltaa kuhunkin yllä olevaan käyttötapaukseen, mutta sukelletaanpa hieman syvemmälle toiseen niistä: Taideteosten / pikkukuvien personointi
Tämä on dataan perustuva personointiominaisuus, joka istuu Elokuvasuositusmoottorin päälle
Tuoteharkinta
Algoritmit ovat hienoja, mutta niillä on rajoituksensa. Tuotepäällikön tulisi aina miettiä etukäteen mahdollisia ääritapauksia, joissa algoritmi ei välttämättä tuota parhaita tuloksia.
- Jokaiseen elokuvaan tulisi ideaalitilanteessa saada personoitu pikkukuva, joka maksimoi klikkaukset. Sanotaan, että Netflix suosittelee käyttäjälle kahta eri Hämähäkkimies-elokuvaa vierekkäin – ja molemmissa on Hämähäkkimies kameraan päin naamio pois päältä. Toisessa on Tobey Maguire ja toisessa Andrew Garfield. Eikö olisi outoa, jos käyttäjä näkisi vierekkäin sekä Maguiren että Garfieldin Hämähäkkimiehen muotokuvat ilman naamioita? Se olisi otettava huomioon, jos niin joskus tapahtuisi.
Yksi kuvan pikkukuva voisi toimia hyvin yksinään, mutta se ei välttämättä riitä, kun sivulle ilmestyy kymmenkunta pikkukuvaa. Jos ne kaikki on optimoitu näyttämään samalta, niin ryhmänä jokainen niistä voi vaikuttaa vähemmän vakuuttavalta. Joten jokaisen pikkukuvan tarkastelu yhdessä sen kanssa, mitä muuta esitetään, on tärkeää. - Data on hienoa, mutta varo algoritmeja, jotka tekevät työnsä liian hyvin, mikä johtaa tahattomiin seurauksiin / vääriin positiivisiin tuloksiin!
Tilastotieteessä tätä kutsutaan tyypin I virheeksi – virheellisesti (tai väärin) ehdotetaan kuvan pikkukuvaa, jota ei pitäisi ehdottaa.
Tapausesimerkki: Katso alla olevaa esimerkkiä Kristen Bellin tähdittämästä elokuvasta Like Father. Silti Netflixin algoritmi teki (kiistatta) vääriä pikkukuvasuosituksia tukevista mustista näyttelijöistä/näyttelijöistä, jotka eivät oikeastaan edusta sitä, mistä elokuvassa oli kyse, mutta kokivat kuitenkin korkeamman klikkausprosentin tiettyjen etnisten yleisöjen keskuudessa.

Ole siis tietoinen siitä, että liiaksi optimoitu/yksilöllinen käyttökokemus voi luoda yksitoikkoisen käyttökokemuksen, joka joissain tapauksissa voi olla harhaanjohtava käyttäjälle. Haluamme tarjota terveen sekoituksen tuttua ja odottamatonta, mutta myös kuvata sisältöä käyttäjälle tarkasti, jotta häntä ei johdeta väärin.
Tässä on toinen esimerkki:
Korkean todennäköisen klikkausprosentin (CTR) perusteella Netflix päätyi esittämään käyttäjille pikkukuvia, jotka vastasivat käyttäjän etnistä alkuperää – – vaikka kyseisellä (yleensä) sivuosanäyttelijällä/-näyttelijättärellä olisi ollut kyseisessä elokuvassa vain vähän esitysaikaa.
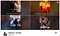
Vaikka tämä on datan tukema aloite, käyttäjälle on melko ilmeistä, että on olemassa tunne epäsiveellisyydestä, joka voi olla harhaanjohtava sen suhteen, että pikkukuva edustaa tarkasti kyseistä elokuvaa (tyypin I väärä positiivinen virhe).
Tämä algoritmi tietysti luultavasti hienosäädetään ajan mittaan, mutta oppi tässä on se, että ei kannata liioitella, kun hyödynnät dataa – sovella maalaisjärkeä tasapainottamaan sitä.
Me emme halua johtaa käyttäjiä väärin tai antaa heille ymmärtää, että heitä kohdellaan eri tavalla esimerkiksi heidän rotunsa vuoksi.
4. Lopuksi algoritmin tulisi ottaa huomioon, mitä pikkukuvia käyttäjä on aiemmin nähnyt tämän elokuvan yhteydessä, ja pyrkiä tarjoamaan johdonmukainen, ei-hämmentävä käyttäjäkokemus.
Haluamme välttää sitä, että käyttäjä näkee erilaisia pikkukuvia joka kerta, kun kyseinen elokuva ilmestyy käyttäjälle. Tämä ei ainoastaan hämmentäisi käyttäjää, vaan tekisi myös tuotepäällikön kannalta vaikeaksi määrittää klikkaukselle attribuutiota – mikä kuva johti korkeampaan klikkausprosenttiin (CTR), kun se vaihtuu jatkuvasti? Tuotepäälliköiden on pystyttävä liittämään jokainen uusi tulos asianmukaisesti tiettyyn muutokseen – joten johdonmukaisen datan määrittelyn ylläpitäminen on tärkeää.
Näissä on siis joitakin asioita, joita tuotepäällikkö harkitsisi suunnitellessaan ääritapausskenaarioita ja sitä, mihin datan käytön ääritapaukset voivat johtaa. Datasta puheen ollen, millä nimenomaan Netflix työskentelee?
Mitä dataa meillä on?
Tässä on kaksi osaa:
- Mitä dataa Netflix käyttää luodakseen nämä yksilölliset pikkukuvat/taideteokset?
- Mitä dataa Netflix käyttää kohdistaakseen nämä yksilöllisesti luodut pienoiskuvat sopivalle henkilölle?
Ensimmäisen kysymyksen osalta ajatellaan, että
- Tunnin mittaisessa Stranger Things -ohjelman jaksossa on >86 000 staattista videokuvakehystä
- Näille videokuvakehyksille voidaan määrittää erikseen tietyt attribuutit, joita käytetään myöhemmin suodattamaan parhaita pikkukuvakandidaattiehdokkaita joukon työkaluja ja algoritmeja, joita kutsutaan nimellä AVA-analyysi (AVA). Tämän tarkoituksena on löytää paras mukautettu pikkukuvakuva videon jokaisesta staattisesta kehyksestä
- Netflix Annotation – Netflix luo metatietoja jokaisesta kehyksestä, mukaan lukien kirkkaus (.67), kasvojen lukumäärä (3) , ihon sävyt (.2), alastomuuden todennäköisyys (.03), liikkeen epätarkkuuden taso (4), symmetria (.4)
- Netflix Image Ranking – Netflix käyttää edellä mainittuja metatietoja poimimaan tietyt kuvat, jotka ovat korkealaatuisimpia (hyvä valaistus, ei liikkeen epätarkkuutta, sisältävät todennäköisesti kasvokuvan tärkeimmistä hahmoista kunnollisesta kuvakulmasta, eivät sisällä luvatonta brändisisältöä jne.) ja joita on helpointa napsauttaa
Toiseen kysymykseen siitä, mitä tietoja Netflix käyttää määrittääkseen, ketä kohdennetaan näillä yksilöllisesti luoduilla pienoiskuvilla:
- Katsottujen elokuvien määrä, katsottujen minuuttien määrä kustakin ohjelmasta
- Kunkin videon/sarjan loppuunsaattamisprosentti
- Yliäänestysten määrä, mitkä elokuvat saivat suosikkeja jne
- Kokonaiskatselusisällön prosentuaalinen osuus, joka johtuu jostain tietystä ohjelmasta (ja näin ollen taso, jolla käyttäjällä on affiniteettiä tiettyyn ohjelmaan tai siihen liittyviin roolihenkilöihin nähden), kausiluonteiset tai viikoittaiset kehityssuunnat, jotka liittyvät käyttäjän sitoutumisen tasoon, jne.
Huomioitavaa on, että vuoden 2018 puolivälissä Netflix lakkasi hyväksymästä käyttäjien arvosteluja datapisteeksi, joita se oli aiemmin pyytänyt vain verkkosivuillaan. Miksi? Koska tämä ”ominaisuus” itse asiassa vähentää katsojamääriä, sillä negatiiviset arvostelut lannistavat käyttäjiä kokeilemasta videota. Tämä on jälleen yksi esimerkki siitä, miten liiketoiminnan tarve syrjäyttää suositun käyttäjän tarpeen!
Netflixillä on siis TONTI tietoa jokaisesta asiakkaastaan – katsotuista videoista klikattuihin kuviin. Mitä he tekevät kaikella tällä datalla?
Miten Netflix käyttää dataa rakentaakseen käyttäjäprofiilin kiinnostuksen kohteiden maailmankaikkeuden
No, he käyttävät sitä kootakseen 360 profiilin jokaisesta käyttäjästä ja indeksoidakseen matemaattisesti jokaisen käyttäjän satojen, mahdollisesti jopa tuhansien erilaisten attribuuttien mukaan.
Ne tekevät tämän yrittäessään ryhmitellä samankaltaisia mielenkiinnon kohteita omaavia henkilöitä yhteen, jotta he voivat käyttää yhdestä käyttäjästä kerättyä dataa apuna ennustaakseen toisten, samankaltaisia mielenkiinnon kohteita omaavien käyttäjien todennäköistä käytöstä.
Miten tämä samankaltaisten käyttäjäprofiilien ryhmittely toimii ja miten tuotepäällikkö saa tietoa hyödynnettyä?
Käveltyäni läpi monimutkaista matematiikkaa ja algoritmeja, jotka liittyvät matriiseihin, vektoreihin ja n-ulotteiseen ominaisuusanalyysiin, huomasin, että helpoin tapa ymmärtää, miten tämä toimii, on yli 10 ulottuvuuden 3D-avaruudellinen esitys.
Tässä on kuvakaappaus, jonka otin käyttäessäni Googlen TensorBoardia mNIST-tietokannassa, joka sisältää käsinkirjoitettuja numeroita. Kyseessä on hieno kuvaaja nimeltä t-SNE-diagrammi – käytännössä 3D-esitys paljon useammasta ulottuvuudesta kuin vain kolmesta. Tässä tapauksessa näytetään 10 ulottuvuutta (yksi jokaiselle numerolle 1-10) 3D-pallomaisessa koordinaatistossa.
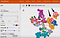
Kunkin käsinkirjoitetun numeron sijaintia tässä avaruudellisessa esityksessä voidaan kuvata vektorilla – koordinaattien kaltaisella numerosarjalla, joka koostuu kuinka monesta ominaisuusulottuvuudesta tahansa.
Neetflix-käyttäjien kohdalla kunkin käyttäjäprofiilin sijaintia yllä olevassa kaaviossa voitaisiin kuvata numeerisilla arvoilla, joista kukin edustaa yksittäistä kyseistä käyttäjän kiinnostuksen dimensiota – mukaan lukien elokuvan genre, suosikkinäyttelijät/-suosikkinäyttelijät, leffan aihealueet, jne.
Netflix-käyttäjien kuvitteleminen uudelleen matemaattisessa suhteessa toisiinsa
Toteutetaan yllä olevassa numerokaaviossa, että:
- ”6” = romanttinen komedia
- ”4” = trilleri
Jos Netflix on merkinnyt käyttäjän numeroksi ”6”, hän sijoittuu yleiseen läheisyyteen, jossa kaikki muut turkoosit kuutoset ovat yllä olevassa avaruudellisessa esityksessä (lähellä pohjaa).
Jos Netflix merkitsee käyttäjälle ”4”, hänet sijoitetaan yleiseen läheisyyteen, jossa kaikki muut magentanpunaiset neloset ovat yllä olevassa avaruudellisessa esityksessä (lähellä yläreunaa).

Huomaa, kuinka turkoosi ”6”-alue (romanttinen komedia) on jossain määrin päällekkäinen harmaan ”5”-alueen kanssa. Tämä voisi olla analogia sille, että käyttäjät, jotka pitävät romanttisista komedioista, voisivat myös pitää parodia- tai satiirielokuvista, koska niihin molempiin liittyy naurua.
Niin ikään, koska magentanpunainen ”4”-alue (trilleri) on jonkin verran lähellä vaaleanpunaista ”9”-aluetta – tämä vaaleanpunainen ”9”-alue voisi edustaa toimintaelokuvista pitäviä henkilöitä, jotka ovat matemaattisesti lähempänä trillerin ”4”-aluetta kuin romanttisen komedian ”6”-aluetta.
Onko siinä järkeä? Paikkatietoisesti esitettynä kahden käyttäjäprofiilin välinen etäisyys edustaa siis sitä, kuinka samankaltaisia/erilaisia heidän makunsa ovat. Tämä voi tietysti muuttua äärettömän paljon monimutkaisemmaksi, kun joku, joka pitää romanttisista komedioista, pitää myös trillereistä – mutta tämän analogian tarkoituksena on osoittaa yleinen ajatus eri kategorioiden välisistä matemaattisista/tilallisista suhteista.
Interintäryhmät, jotka liittyvät toisiinsa, näkyisivät lähempänä toisiaan ja voisivat olla hyviä ennusteita siitä, mistä käyttäjä pitää, kun otetaan huomioon, että käyttäjä pitää jostain muusta lähistöllä olevasta asiasta.
Näin Netflix tai oikeastaan mikä tahansa ML-malleja hyödyntävä yritys luo suhteita näennäisesti jäsentymättömän datan välille ja kääntää datan numeroiksi. Näissä numeroissa ei ole yksinään paljon järkeä, mutta yhdessä suhteessa toisiinsa niissä alkaa olla järkeä.
Saman alla olevan Good Will Hunting -elokuvan kohdalla yhdelle käyttäjälle, joka on tunnistettu komedian ystäväksi, näytetään Robin Williamsin (koomikko) pikkukuva, kun taas toiselle käyttäjälle, joka on tunnistettu romanttisen komedian ystäväksi, näytetään pussailun pikkukuva, jossa esiintyvät Matt Damon ja Minnie Driver. Vaikka tämä ei olekaan täydellistä, Netflixin algoritmit viittaavat siihen, että tällainen käyttäjäprofiilin ominaisuuksiin perustuva personoinnin taso lisää klikkausprosentin todennäköisyyttä.

Kerrataan siis yhteenveto. Joukko Netflixin kuvien pikkukuvia on joukko jäsentymätöntä dataa.
Mutta kun Netflix kommentoi jokaisen pikkukuvan ja määrittää metatietoja kuhunkin kuvaamaan, mitä kyseisessä pikkukuvassa on – nyt meillä on numeerinen esitys tuosta jäsentymättömästä datasta.
Plotataan tämä numeerinen esitys vektoreiden muodossa 3D-pallon poikki, kuten teimme edellä – ja nyt Netflix alkaa muodostaa datapisteiden välisiä suhteita.
Netflix löytää sitten datapisteitä, jotka ovat suhteellisen lähellä toisiaan, ja käyttää niitä ennustamaan tulevaa klikkauskäyttäytymistä. Jos ennusteet osoittautuvat huonoiksi tai hyviksi, he muokkaavat näiden ominaisuuksien matemaattista sijoittelua vastaavasti, kunnes malli muuttuu ajan mittaan yhä paremmaksi.
Siten Netflix siis muuttaa jäsentymätöntä dataa matemaattisiksi esityksiksi. Se käyttää datapisteiden välistä suhteellista etäisyyttä perustana kuvien pikkukuvasuositusten tekemiselle ja parantamiselle.
Mitä Netflix oppi kaikesta tästä datasta?
Nyt kun tiedämme, miten Netflix muuttaa kuvat numeroiksi koneoppimismallissa, mitä oivalluksia Netflix on löytänyt kaikesta datankäsittelystä ja A/B-testeistä, joita se on suorittanut niin monen vuoden ajan?
Noh, sen lisäksi, että Netflix on oppinut miljoonista yksittäisistä pikkukuvista, jotka ovat ajan mittaan muuttaneet käyttäjät uskollisiksi tilaajiksi, tässä on muutamia muita asioita, jotka Netflix on oppinut siitä, mikä toimii pikkukuvien suhteen:
- näytetään lähikuvia emotionaalisesti ilmeikkäistä kasvoista
- näytetään ihmisistä roistoja sankareiden sijasta
- Ei näytetä enempää kuin kolmea hahmoa
Johtopäätöksinä: Netflix käytti tekoälyä (enimmäkseen) oikealla tavalla. Opitaan heidän lähestymistavastaan.
Netflix on tehnyt ilmiömäistä työtä soveltaessaan tekoälyä, datatiedettä ja koneoppimista ”oikealla tavalla” – käyttäen tuotepohjaista lähestymistapaa, jossa keskitytään ensin liiketoimintatarpeeseen ja sen jälkeen tekoälyratkaisuun eikä päinvastoin.
Oikein sovellettuna tekoäly voi tehdä ihmeitä.
Olemme nähneet, kuinka tehokkaita tekoälyratkaisut voivat olla kokemuksen personoinnissa, mikä hyödyttää sekä Netflixiä tilausten osalta että käyttäjiä yleisen tyytyväisyyden osalta.
Olemme myös nähneet rajoituksia algoritmeille, jotka ”liioittelevat”, ja keskustelleet konkreettisista esimerkeistä, joissa Netflixin algoritmi esitti harhaanjohtavia pienoiskuvia värillisille ihmisille, koska algoritmi optimoi klikkauksia, mikä tosiasiassa ”huijautti” käyttäjät klikkaamaan syöttejä. Näin tapahtui silloinkin, kun kyseinen pikkukuva ei edustanut tarkasti kyseistä videota.
Kään algoritmi ei ole täydellinen ottamaan huomioon kaikkia ihmiskokemuksen vivahteita. Itse asiassa algoritmit, jotka on suunniteltu hyödyntämään mittareita, tekevät juuri niin, joten tuotepäällikön tehtävänä on työskennellä suunnittelun tai muiden tiimin jäsenten kanssa löytääkseen keinoja, joilla nämä algoritmien puutteet voidaan korjata.
Tulevaisuudessa tekoälyn integrointi yhteiskuntaan sekä yritystoimintaan yleistyy entisestään.
Teknologeilla saattaa olla taipumus määrätä olemassa olevia tekoälyratkaisuja, mutta oikeasti tehokkain tapa ottaa tekoäly käyttöön on se, miten Netflix teki – ensin liiketoimintavetoisesta näkökulmasta.
Kaivaudu syvemmälle ja huomaat, että Netflix tuotti sitä tukevaa dataa ennen kuin se teki strategisen siirron eteenpäin.
Kun tekoälyn, datatieteen ja koneoppimisen maailma jatkaa kasvuaan, me tuotepäälliköt voimme kaikki ottaa oppitunnin tai kaksi Netflixin pelikirjasta, kun kyse on tekoälyratkaisujen asianmukaisesta käyttöönotosta.
Hyväksyttiin Netflixin algoritmi.Hyväksyttiin.