
Přítomnost umělé inteligence v dnešní společnosti je stále všudypřítomnější – zejména proto, že velké společnosti jako Netflix, Amazon, Facebook, Spotify a mnoho dalších neustále zavádějí řešení související s umělou inteligencí, která přímo komunikují (často v zákulisí) se spotřebiteli každý den.
Pokud jsou tato řešení související s umělou inteligencí správně aplikována na obchodní problémy, mohou poskytnout skutečně jedinečná řešení, která se v průběhu času škálují a zlepšují, což vytváří významný dopad pro podnik i uživatele. Co však znamená „správně aplikovat“ řešení AI? Znamená to, že existuje špatný způsob? Z produktového hlediska je krátká odpověď ano a k tomu, proč tomu tak je, se dostaneme později v tomto článku, až se dostaneme hlouběji.
Přehled: Nejprve si nastíníme 5 případů použití datové vědy nebo strojového učení ve společnosti Netflix. Poté probereme některé obchodní potřeby versus technické úvahy, na které by se měl zaměřit produktový manažer. Poté se ponoříme trochu hlouběji do asi nejzajímavějšího z těchto 5 případů použití, protože určíme, jaký obchodní problém se snaží vyřešit.
1. Sestavíme jednoduchou neuronovou síť!
2. Rozhodovací stromy ve strojovém učení
3. Intuitivní úvod do strojového učení
4. Rovnováha mezi pasivní a aktivní A.I.
5 Případů použití umělé inteligence/dat/strojového učení ve společnosti Netflix
- Personalizace filmových doporučení – uživatelé, kteří sledují film A, budou pravděpodobně sledovat film B. To je asi nejznámější funkce služby Netflix. Netflix využívá historii sledování ostatních uživatelů s podobným vkusem k tomu, aby vám doporučil, co byste mohli sledovat příště, abyste zůstali zaujati a pokračovali ve svém měsíčním předplatném na další filmy.
- Automatické generování a personalizace miniatur/obrázků – Na základě tisíců videosnímků z existujícího filmu nebo seriálu jako výchozího bodu pro generování miniatur Netflix tyto snímky anotuje a poté jednotlivé snímky hodnotí ve snaze určit, které miniatury mají největší pravděpodobnost, že povedou k vašemu kliknutí. Tyto výpočty vycházejí z toho, na co klikli ostatní, kteří jsou vám podobní. Jedním ze zjištění by mohlo být, že uživatelé, kteří mají rádi určité herce / filmové žánry, s větší pravděpodobností kliknou na náhledy s určitými herci / atributy obrazu.
- Vyhledávání lokací pro filmovou produkci (předprodukce) – Využití dat pro pomoc při rozhodování o tom, kde a kdy je nejlepší natáčet filmové scény – vzhledem k omezením plánování (dostupnost herců / štábu), rozpočtu (místo natáčení, náklady na letenku / hotel) a požadavkům na produkční scénu (denní vs. noční natáčení, pravděpodobnost rizika meteorologických událostí v dané lokalitě). Všimněte si, že se jedná spíše o optimalizační problém datové vědy než o model strojového učení, který vytváří předpovědi na základě údajů z minulosti.
- Střih filmu (postprodukce) -Využití historických údajů o tom, kdy v minulosti selhaly kontroly kvality (když v minulosti nebyla synchronizace titulků se zvukem/pohyby) – k předpovědi, kdy je nejvýhodnější provést ruční kontrolu v procesu, který by jinak mohl být časově velmi náročný a pracný.
- Kvalita streamování – využití dat z minulých sledování k předvídání využití šířky pásma, aby se Netflix mohl rozhodnout, kdy má v době největší (očekávané) poptávky ukládat do mezipaměti regionální servery pro rychlejší načítání.
Těchto 5 případů použití / aplikací datové vědy nebo strojového učení jen v samotném Netflixu mělo tak škálovatelný dopad, že navždy změnily technologické prostředí a uživatelský zážitek pro miliony lidí a další. Přijetí těchto řešení souvisejících s umělou inteligencí bude časem jen sílit.
Než se však tyto případy použití staly tak běžnými, jako jsou dnes, a používali je uživatelé jako vy nebo já, někdo nebo nějaká skupina v rámci společnosti Netflix tato řešení umělé inteligence řádně propojila s obchodní potřebou. Bez tohoto obchodního propojení by tyto případy užití byly pouhým nápadem z říše snů, který by ležel na dně zásobníku nevyřízených úkolů jako mnoho jiných skvělých nápadů. Pouze díky správnému umístění a propojení s hlavním obchodním problémem společnosti Netflix se tyto nápady staly takovou realitou, jakou jsou dnes.

- Jaká je obchodní potřeba/problém?
- Doporučení filmů:
- Personalizované miniatury obrázků / umělecká díla: Identifikace problému
- OK, miniatury jsou důležité. Ale co přesně ladíme?“
- Produktové aspekty personalizovaných miniatur obrázků
- Jaká data máme k dispozici?
- Jak Netflix využívá data k sestavení vesmíru zájmových profilů uživatelů
- Představení uživatelů Netflixu ve vzájemném matematickém vztahu
- Co se Netflix ze všech těchto dat naučil?
- V závěru: Netflix nasadil umělou inteligenci (většinou) správným způsobem. Poučme se z jejich přístupu.
Jaká je obchodní potřeba/problém?
Všimněte si, že v každém z případů užití, které jsem identifikoval výše, je každý z nich spojen s konkrétní obchodní potřebou, cílem nebo hypotézou.
To je naprosto důležité pro každého produktového manažera – aby se vyhnul pokušení technického nadšence, který se z intelektuálních důvodů podivuje nad detaily datové vědy / nebo ML, aniž by jasně identifikoval problém nebo obchodní potřebu – potenciálně spotřebovává cenné technické zdroje bez obchodního dopadu.
Koneckonců, produktoví manažeři musí správně propojit obchodní problém s řešením strojového učení dat. Chceme se vyhnout tomu, abychom měli řešení, které se honí za problémem, jinak projekt ztratí ve firmě dynamiku: inženýři nebudou mít jasno v tom, co je jejich severní hvězdou, zainteresované strany napříč organizací nebudou nakupovat a alokovat potřebné zdroje, aby byl projekt úspěšný, atd.
Ujistěte se, že existuje problém, s nímž lze řešení AI přímo spojit
Machine learning (ML) je potenciálním řešením AI – ale před předepsáním tohoto řešení musíme nejprve definovat problém.
Jakého obchodního výsledku se snažíme pomocí ML dosáhnout? Protože tato základní obchodní potřeba je tím, co určuje parametry použitých modelů ML, jaká data se shromažďují a zpracovávají atd. Neděláme ML, abychom poskytovali personalizaci jen proto, že je to zajímavá technologie – musíme ji spojit s obchodním problémem. Datoví vědci jsou specialisté na odhalování poznatků z dat, ale úkolem produktového manažera je správně je propojit s obchodní potřebou nebo problémem a porovnat je s konkurenčními prioritami.
Například technologický nadšenec by mohl říci:
Nebylo by skvělé, kdybyste mohli analyzovat / debatovat o epizodě pomocí hlasu s Netflixem – a Netflix by díky datovým vstupům z reakcí tisíců dalších uživatelů na tuto epizodu mohl inteligentně reagovat na vaše komentáře ve dvoustranném dialogu tam a zpět?
Ano, to by byl docela úžasný případ použití využívající zpracování přirozeného jazyka (NLP) k pochopení vašeho komentáře po epizodě v kontextu. Kromě NLP tento případ užití využívá text k hlasovým osobnostem a také analýzu sentimentu, jak se tisíce dalších lidí cítily ohledně toho, co se v dané epizodě stalo, nebo co si myslí o určité postavě. Vskutku se jedná o krásné spojení několika špičkových technologií v jednom případu užití.
Pokud by pilotní verze MVP ukázala, že uživatelé, kteří se zapojili do jeho nové funkce, zůstali déle nebo se častěji vraceli nebo pomohli zvýšit povědomí o Netflixu, pak by to mohlo odůvodnit další zdroje. Počáteční rozhodnutí o vybudování této MVP by záviselo na strategickém rozhodnutí zúčastněných stran, které by nemuselo být nutně prioritní podle metriky. To bude záviset na strategii společnosti.
Ale jak krásný je výše uvedený uživatelský scénář, jaký problém to řeší?
Jak to souvisí s hlavním problémem Netflixu, kterým je udržet si uživatele předplacené každý měsíc? Pokud to souvisí, jaké důkazy (kvalitativní nebo kvantitativní) máme na podporu tohoto vztahu?
A pokud je to legitimní řešení tohoto problému, existuje jednodušší verze tohoto řešení, která by mohla stejně tak splnit tento problém, ale byla by méně technicky složitá? Jak by například místo hlasového vstupu a hlasového výstupu mohla složitost pouhého textového vstupu a textového výstupu ovlivnit úroveň úsilí a dopad na zapojení uživatelů?
Co kdyby konverzační rozhraní s umělou inteligencí bez hlasové části (pouze text) dosáhlo 80 % zamýšleného zapojení uživatelů, ale vyžadovalo pouze 40 % úsilí na vývoj? Stálo by za to uvažovat o takové alternativní cestě?
Jaký dopad na podnikání by takové řešení mělo v porovnání s úrovní úsilí? Jaký je tento poměr v porovnání s ostatními konkurenčními úkoly v backlogu?“
To vše jsou otázky zaměřené na produkt, které by si měl PM klást, aby sladil technologická řešení s obchodními potřebami. Protože v konečném důsledku jsou to obchodní potřeby, které určují parametry modelu ML, nikoli naopak.
Podívejme se tedy ještě jednou na filmová doporučení a tyto personalizované miniatury – jaký je problém nebo obchodní cíl?

Doporučení filmů:
Problém spočívá v tom, že Netflix má obrovskou sbírku obsahu (podle společnosti Netflix více než 100 milionů různých produktů), která se neustále mění a její konzumace může být pro uživatele zahlcující. Uživatelé nechtějí být frustrováni při hledání obsahu odpovídajícího jejich zájmům. Jaký je tedy nejlepší způsob, jak umožnit každému uživateli konzumovat tato data způsobem, který v konečném důsledku maximalizuje věrnost předplatitelům?
Mezi cíle produktu patří:
- Zvýšit / udržet sledovanost z hlediska # spotřebovaných minut,
- Zvýšit # prozkoumaných titulů, frekvence opětovného přihlašování
- Překročení libovolné minimální hranice, kterou společnost určí jako metriku úspěchu
- Celkové zvýšení loajality k měsíčnímu předplatnému / snížení počtu zrušených předplatitelů
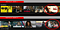
Personalizované miniatury obrázků / umělecká díla: Identifikace problému
Tento případ užití je podmnožinou Doporučení filmů. Vzhledem k tomu, že doporučení filmů jsou poskytována uživateli, máme nyní další obchodní / uživatelský problém.
Problém: Jak (a kdy) nejlépe prezentovat toto filmové doporučení uživateli způsobem, který maximalizuje sledovanost a měsíční věrnost předplatitelů?
Jedním ze způsobů, jak poskytnout toto doporučení, je obrazová miniatura – ale jakou miniaturu poskytneme? A nakolik jsme si jisti, že úprava miniatury obrázku pozitivně ovlivní sledovanost nebo věrnost předplatitelů?
A nakolik je tato miniatura důležitá? Máme pro to data?
Shromažďování dat na podporu této hypotézy
No, můžete si být jisti, že nějaký produktově zaměřený člověk ve společnosti Netflix – v době před rokem 2014 – si interně kladl úplně stejné otázky. A tento člověk nebo skupina spolupracovala (pravděpodobně s UX a souvisejícími zainteresovanými stranami) na sestavení uživatelských studií nebo dat z jiných míst, aby dokázala, že skutečně existuje silná vazba mezi miniaturou obrázku a sledovaností.
To byla jejich hypotéza: že úprava uměleckého obsahu miniatury obrázku může mít silnou vazbu na sledovanost.
No, ukázalo se, že už v roce 2014 Netflix provedl studie, které ukázaly, jak důležitá je miniatura:
Nick Nelson, globální manažer kreativních služeb Netflixu, vysvětlil, že společnost počátkem roku 2014 provedla výzkum, který zjistil, že umělecké dílo „nejenže má největší vliv“ na rozhodování uživatelů o tom, co budou sledovat, ale také tvoří více než 82 procent jejich pozornosti při prohlížení Netflixu.
„Zjistili jsme také, že uživatelé strávili v průměru 1,8 sekundy zvažováním každého titulu, který jim byl při prohlížení Netflixu předložen,“ napsal Nelson. „Překvapilo nás, jak velký vliv měl obrázek na to, aby člen našel skvělý obsah, a jak málo času jsme měli na to, abychom je zaujali.“
Malá, přesvědčivá miniatura může znamenat rozdíl mezi tím, zda strávíte celý víkend sledováním nejnovějšího hitu Originals společnosti Netflix, nebo ztratíte zájem a přejdete ke konkurenční službě, jako je Hulu nebo podobné OTT streamovací služby jako ESPN / Disney / HBO Go.
Na základě studií se tedy ukázalo, že výše uvedená hypotéza je velmi pravdivá.
OK, miniatury jsou důležité. Ale co přesně ladíme?“
A jak se nestrukturovaný soubor dat, jako je soubor miniatur obrázků, vloží do digitálního/matematického modelu strojového učení? Na tuto druhou otázku odpovíme dále.
Předně, vzhledem k tomu, jak důležitá byla miniatura pro rozhodnutí uživatele něco sledovat, jak může Netflix generovat lepší miniatury pro každého uživatele, aby zvýšil šanci, že se uživatel na video podívá?
Používání originální grafiky filmu jako jediné miniatury používané pro každého jednotlivého člověka s největší pravděpodobností nepřinese nejvyšší míru kliknutí. Podnik pravděpodobně nechává kliknutí (a divácký streamovací čas) na stole!
Co kdyby Netflix na zakázku vytvořil pro každého uživatele jinou miniaturu, která by byla optimalizovaná tak, aby zvýšila míru kliknutí?
Jaké věci v miniatuře obrázku, které má Netflix pod kontrolou, může upravit, aby zvýšil míru těchto kliknutí?

Který herec (herci)/která postava (postavy) by měla být na této miniatuře, pokud nějaká je? Kolik jich je? Která automaticky generovaná varianta snímku nebo plakátu by byla pro konkrétního uživatele nejlákavější, aby na ni kliknul? Jaké osvětlení funguje nejlépe? Filtry?“
Jaké máme údaje o minulém chování jiných uživatelů při klikání, z nichž můžeme čerpat asociace, které nám pomohou při rozhodování o této miniatuře v měřítku?
- Zvýšení míry prokliku (CTR) u doporučení filmů – což znamená zapojení
- Hypotéza, že vyšší míra zapojení povede k vyšší spokojenosti a loajalitě předplatitelů
Toto je opravdu zajímavý problém s miniaturou obrázku, která může mít obrovský vliv na pravděpodobnost, že někdo na video klikne a podívá se.
Jestliže je cílem maximalizovat pravděpodobnost sledování úpravou miniatury – jaká rozhodnutí o produktu je třeba zvážit?
Produktové aspekty personalizovaných miniatur obrázků
Nebudeme se zabývat každým z výše uvedených případů použití, ale ponoříme se trochu hlouběji do druhého z nich: Personalizace uměleckých děl / miniatur
Jedná se o funkci personalizace založenou na datech, která je umístěna nad doporučovacím mechanismem filmů
Úvahy o produktech
Algoritmy jsou skvělé, ale mají svá omezení. Produktový manažer by měl vždy dopředu myslet na možné okrajové scénáře, ve kterých algoritmus nemusí přinést nejlepší výsledky.
- Každý film by měl mít v ideálním případě personalizovanou miniaturu, která maximalizuje počet kliknutí. Vzhledem k tomu, že Netflix má k dispozici údaje o chování při klikání jiných lidí s podobnými zájmy, je rozumnou hypotézou odhadnout, že pokud jiní lidé s podobnými zájmy a historií sledování měli vysokou míru kliknutí na určitou miniaturu, pak je pravděpodobné, že tato miniatura snímku bude fungovat i u nového člověka, kterému tento film / miniatura dosud nebyla doporučena.
- Personalizovaná miniatura by měla brát v úvahu další filmy, které jsou tam doporučovány ve stejnou dobu – a jaké jsou tyto doporučené snímky. Řekněme, že Netflix uživateli doporučuje 2 různé filmy se Spidermanem vedle sebe – a na obou je Spiderman s vypnutou maskou kamery. V jednom je Tobey Maguire a ve druhém Andrew Garfield. Nebylo by pro uživatele divné vidět oba portréty Maguirea a Garfielda jako Spidermana se sundanými maskami – vedle sebe? Pokud by k tomu někdy došlo, je třeba s tím počítat.
Jedna miniatura obrázku by mohla dobře fungovat izolovaně, ale to nemusí stačit, když se zobrazí stránka s tuctem miniatur. Pokud jsou všechny optimalizovány tak, aby vypadaly stejně, pak jako skupina může každá z nich působit méně přesvědčivě. Důležitý tedy bude pohled na každou miniaturu společně s tím, co dalšího je prezentováno. - Data jsou skvělá, ale pozor na algoritmy, které dělají svou práci příliš dobře, což vede k nezamýšleným důsledkům / falešně pozitivním výsledkům!
Ve statistice se tomu říká chyba typu I – falešné (nebo nesprávné) navržení miniatury obrázku, která by neměla být navržena.
Příklad: Podívejte se na níže uvedený příklad filmu Like Father, ve kterém hraje Kristen Bell. Přesto algoritmus Netflixu (pravděpodobně) falešně doporučil miniatury podporující černošské herce/herečky, které ve skutečnosti nepředstavují to, o čem film byl, ale zaznamenaly vyšší míru kliknutí u určitého etnického publika.

Uvědomte si tedy, že příliš optimalizované / personalizované prostředí může vytvořit monotónní uživatelský zážitek, který může být v některých případech pro uživatele zavádějící. Chceme poskytnout zdravý mix známého s neočekávaným, ale také přesně zobrazit obsah uživateli, aby nebyl nesprávně uveden v omyl.
Tady je další příklad:
Na základě vysoké pravděpodobnosti rychlosti prokliku (CTR) Netflix nakonec zobrazil uživatelům náhledy, které odpovídaly etnické příslušnosti uživatele – – i když měl tento (obvykle) vedlejší herec/herečka v daném filmu velmi málo prostoru.
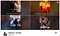
Přestože se jedná o iniciativu podpořenou daty, je pro uživatele zcela zřejmé, že je zde cítit nespravedlnost, která může být zavádějící, pokud jde o miniaturu přesně reprezentující daný film (chyba falešné pozitivity typu I).
Jistě, tento algoritmus bude pravděpodobně časem doladěn, ale poučením je, že to při využívání dat nepřehánějte – použijte zdravý rozum, abyste to vyvážili.
Nechceme uživatele nevhodně uvádět v omyl nebo mu dávat najevo, že se s ním zachází jinak například kvůli jeho rase.
4. A konečně, algoritmus by měl brát v úvahu, jaké miniatury uživatel dříve viděl v souvislosti s tímto filmem, a snažit se poskytnout konzistentní, nematoucí uživatelský zážitek.
Chceme se vyhnout tomu, aby uživatel viděl různé miniatury pokaždé, když se mu tento film zobrazí. Nejenže by to uživatele mátlo, ale také by to produktovému manažerovi ztížilo přiřazení atribuce ke kliknutí – který obrázek vedl k vyšší míře prokliku (CTR), když se neustále mění? PM musí být schopen správně přiřadit každý nový výsledek ke konkrétní změně – proto je důležité zachovat konzistentní přiřazení dat.
Toto jsou tedy některé věci, které by měl produktový manažer zvážit při navrhování okrajových scénářů a k čemu mohou vést extrémní případy využití dat. Když už mluvíme o datech, na základě čeho konkrétně Netflix pracuje?
Jaká data máme k dispozici?
Tato otázka má dvě části:
- Jaká data Netflix používá k vytváření těchto personalizovaných miniatur/obrázků?
- Jaká data Netflix používá k cílení těchto na míru vytvořených miniatur na příslušné osoby?
Pro první otázku uvažte, že
- Jedna hodinová epizoda seriálu Stranger Things má >86 000 statických videosnímků
- Každému z těchto videosnímků lze jednotlivě přiřadit určité atributy, které se později použijí k vyfiltrování nejlepších kandidátů na miniatury prostřednictvím sady nástrojů a algoritmů nazývaných estetická vizuální analýza (AVA). Ta je navržena tak, aby z každého statického snímku videa našla nejlepší vlastní miniaturu
- Anotace Netflix – Netflix vytvoří pro každý snímek metadata zahrnující jas (,67), # obličejů (3) , odstíny pleti (,2), pravděpodobnost nahoty (,03), úroveň rozmazání pohybu (4), symetrii (.4)
- Netflix Image Ranking – Netflix používá výše uvedená metadata k tomu, aby vybral konkrétní snímky, které jsou nejkvalitnější (dobré osvětlení, žádné rozmazání pohybu, pravděpodobně obsahují nějaký záběr obličeje hlavních postav ze slušného úhlu, neobsahují neautorizovaný značkový obsah atd) a nejklikatelnější
Pro druhou otázku, jaká data Netflix používá k určení toho, na koho má tyto vlastní generované náhledy cílit, uvažte, že Netflix sleduje:
- # zhlédnutých filmů, # minut každého zhlédnutého pořadu
- % dokončení každého videa/seriálu
- # upvotes, které filmy byly oblíbené atd
- % celkového zhlédnutého obsahu, který lze připsat nějakému konkrétnímu pořadu (a tedy úroveň afinity daného uživatele ke konkrétnímu pořadu nebo souvisejícím hercům)
- jakékoli sezónní nebo týdenní trendy související s úrovní zapojení uživatele atd.
Zajímavé je, že v polovině roku 2018 přestala společnost Netflix přijímat uživatelská hodnocení jako datový bod, který dříve získávala pouze na svých webových stránkách. Proč? Protože tato „funkce“ ve skutečnosti snižuje sledovanost, protože negativní recenze odrazují uživatele od vyzkoušení videa. Je to jen další příklad toho, jak obchodní potřeba přebíjí oblíbenou potřebu uživatelů!“
Takže Netflix má o každém svém zákazníkovi TUNU dat – od zhlédnutých videí až po kliknuté obrázky. Co se všemi těmito daty dělají?“
Jak Netflix využívá data k sestavení vesmíru zájmových profilů uživatelů
No, používají je k tomu, aby sestavili 360 profilů každého uživatele a matematicky indexovali každého uživatele podle stovek, možná tisíců různých atributů.
Dělají to proto, aby se pokusili seskupit lidi s podobnými zájmy dohromady, takže mohou použít data od jednoho uživatele k tomu, aby pomohli předpovědět pravděpodobné chování dalších podobných uživatelů.
Jak toto seskupování podobných uživatelských profilů funguje a jak z těchto dat produktový manažer získá smysl?
Když jsem prošel složitou matematiku a algoritmy spojené s maticemi, vektory a analýzou n-rozměrných rysů, zjistil jsem, že nejjednodušší způsob, jak pochopit, jak to funguje, je prostřednictvím 3D-prostorové reprezentace více než 10 rozměrů.
Tady je snímek obrazovky, který jsem pořídil při použití nástroje TensorBoard společnosti Google na databázi ručně psaných číslic mNIST. Jedná se o efektní graf zvaný t-SNE plot – efektivně 3D zobrazení mnohem více rozměrů než jen 3. V tomto případě zobrazujeme 10 rozměrů (jeden pro každou číslici od 1 do 10) na 3D souřadném systému podobném kouli.
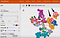
Polohu každé ručně psané číslice v tomto prostorovém zobrazení lze popsat vektorem – souřadnicově podobnou řadou čísel napříč libovolným počtem dimenzí funkce.
Podobně u uživatelů Netflixu lze polohu každého profilu uživatele ve výše uvedeném grafu popsat číselnými hodnotami, z nichž každá představuje jednotlivou dimenzi zájmu daného uživatele – včetně žánru filmu, oblíbených herců/hereček, tématu filmu atd.
Představení uživatelů Netflixu ve vzájemném matematickém vztahu
Představme si ve výše uvedeném diagramu číslic, že:
- „6“ = romantická komedie
- „4“ = thriller
Pokud je uživatel Netflixem označen jako „6“, pak bude umístěn v obecné blízkosti místa, kde se ve výše uvedeném prostorovém zobrazení nacházejí všechny ostatní tyrkysové šestky (blízko dolní části).
Podobně, pokud je uživatel označen Netflixem jako „4“, pak bude umístěn v obecné blízkosti místa, kde jsou všechny ostatní purpurové 4 ve výše uvedeném prostorovém zobrazení (blízko horní části).

Všimněte si, jak se tyrkysová oblast „6“ (romantické komedie) poněkud překrývá s šedou oblastí „5“. To by mohlo být analogické tomu, že uživatelé, kteří mají rádi romantické komedie, by mohli mít rádi také parodie nebo satiry, protože v obou případech jde o smích.
Podobně, protože purpurový region „4“ (thriller) je poněkud blízko růžovému regionu „9“ – tento růžový region „9“ by mohl představovat ty, kteří mají rádi akční filmy – matematicky blíže regionu thriller „4“ než regionu romantická komedie „6“.
Dává to smysl? Při prostorovém znázornění tedy vzdálenost mezi dvěma profily uživatelů představuje, jak podobný/odlišný je jejich vkus. Samozřejmě to může být nekonečně složitější, když má někdo, kdo má rád romantické komedie, rád také thrillery – ale účelem této analogie je ukázat obecnou představu matematických / prostorových vztahů mezi různými kategoriemi.
Skupiny zájmů, které spolu souvisejí, by se objevily blíže u sebe a mohly by být dobrým prediktorem toho, co se uživateli bude líbit, za předpokladu, že se mu líbí něco jiného v okolí.
Takto Netflix, nebo vlastně jakákoli společnost využívající ML modely, vytváří vztahy mezi zdánlivě nestrukturovanými daty a mění tato data v čísla. Tato čísla sama o sobě nedávají příliš velký smysl, ale dohromady ve vzájemném vztahu začnou dávat smysl.
U téhož filmu Dobrý Will Hunting níže by se jednomu uživateli identifikovanému jako fanoušek komedie zobrazila miniatura Robina Williamse (komika), zatímco jinému uživateli identifikovanému jako fanoušek romantické komedie by se zobrazila miniatura líbajícího se Matta Damona a Minnie Driver. I když to není dokonalé, algoritmy společnosti Netflix naznačují, že taková úroveň personalizace na základě charakteristik uživatelského profilu zvyšuje pravděpodobnost míry prokliku.

Takže si to shrňme. Hromada miniatur obrázků Netflixu je hromada nestrukturovaných dat.
Ale jakmile Netflix anotuje každou miniaturu a přiřadí ke každé z nich metadata, která popisují, co je na dané miniatuře – nyní máme číselnou reprezentaci těchto nestrukturovaných dat.
Vyneseme tuto číselnou reprezentaci ve formě vektorů na 3D kouli, jak jsme to udělali výše – a nyní Netflix začne vytvářet vztahy mezi datovými body.
Netflix pak najde datové body, které jsou si relativně blízko, a použije je k předpovědi budoucího chování při kliknutí. Pokud se předpovědi ukáží jako špatné nebo dobré, upraví podle toho matematické umístění těchto charakteristik, dokud se model časem nestane lepším a lepším.
Takto tedy Netflix mění nestrukturovaná data na matematické reprezentace. Jako základ pro vytváření a zlepšování doporučení miniatur obrázků používá relační vzdálenost mezi datovými body.
Co se Netflix ze všech těchto dat naučil?
Když už víme, jak Netflix mění obrázky na čísla v modelu strojového učení, jaké poznatky Netflix zjistil ze všech těch zpracování dat a A/B testů, které provádí už tolik let?
No, kromě toho, že se naučili miliony jednotlivých miniatur, které v průběhu času přeměnily uživatele na věrné předplatitele, zde je několik dalších věcí, které se Netflix naučil, co funguje, pokud jde o miniatury:
- Ukazujte detailní záběry emocionálně výrazných tváří
- Ukazujte lidem padouchy místo hrdinů
- Neukládejte více než tři postavy
V závěru: Netflix nasadil umělou inteligenci (většinou) správným způsobem. Poučme se z jejich přístupu.
Netflix odvedl fenomenální práci při aplikaci AI, datové vědy a strojového učení „správným způsobem“ – pomocí přístupu založeného na produktech, který se zaměřuje nejprve na obchodní potřeby a poté na řešení AI, nikoli naopak.
Při správné aplikaci dokáže AI zázraky.
Viděli jsme, jak účinná mohou být řešení AI při personalizaci zážitku ve prospěch společnosti Netflix z hlediska předplatného i uživatelů z hlediska celkové spokojenosti.
Viděli jsme také omezení algoritmů, které to „přehánějí“, a diskutovali jsme o konkrétních příkladech, kdy algoritmus společnosti Netflix prezentoval barevným lidem zavádějící náhledy, protože algoritmus optimalizoval klikání, čímž efektivně „podvedl“ uživatele, aby klikali na návnadu. K tomu docházelo, i když tato miniatura přesně nereprezentovala dané video.
Žádný algoritmus nebude dokonalý v zohledňování všech nuancí lidské zkušenosti. Algoritmy navržené tak, aby využívaly metriky, ve skutečnosti dělají právě to – je tedy úkolem produktového manažera, aby ve spolupráci s designéry nebo dalšími členy týmu našel způsoby, jak tyto nedostatky v algoritmech odstranit.
V budoucnu bude integrace umělé inteligence ve společnosti i v podnikové sféře stále rozšířenější.
Technologové mohou mít tendenci předepisovat existující řešení umělé inteligence, ale ve skutečnosti je nejefektivnějším způsobem, jak přijmout umělou inteligenci, způsob, jakým to udělala společnost Netflix – nejprve z pohledu podnikání.
Ponořte se do hloubky a uvidíte, že Netflix generoval podpůrná data předtím, než učinil strategický krok vpřed.
Jak se svět AI, datové vědy a strojového učení neustále rozrůstá, my všichni produktoví manažeři si můžeme vzít lekci nebo dvě z příručky společnosti Netflix, pokud jde o správné nasazení řešení AI.