
A mesterséges intelligencia jelenléte a mai társadalomban egyre inkább mindenütt jelen van – különösen, mivel az olyan nagyvállalatok, mint a Netflix, az Amazon, a Facebook, a Spotify és még sokan mások folyamatosan telepítik a mesterséges intelligenciával kapcsolatos megoldásokat, amelyek közvetlenül (gyakran a színfalak mögött) lépnek kapcsolatba a fogyasztókkal nap mint nap.
Az üzleti problémákra megfelelően alkalmazva ezek a mesterséges intelligenciával kapcsolatos megoldások valóban egyedi megoldásokat nyújthatnak, amelyek idővel skálázódnak és javulnak, jelentős hatást gyakorolva mind az üzlet, mind a felhasználó számára. De mit jelent egy AI-megoldás “megfelelő alkalmazása”? Ez azt jelenti, hogy van rossz út? Termékszempontból a rövid válasz igen, és hogy miért van ez így, arra a cikk későbbi részében térünk ki, amikor mélyebbre ásunk.
Áttekintés: Először is felvázoljuk az adattudomány vagy a gépi tanulás 5 felhasználási esetét a Netflixnél. Ezután megvitatunk néhány üzleti igényt vs. technikai megfontolást, amelyet egy termékmenedzser megvizsgálna. Ezután egy kicsit mélyebben belemerülünk az 5 felhasználási eset közül talán a legérdekesebbbe, mivel azonosítjuk, hogy milyen üzleti problémát kíván megoldani.
1. Építsünk egy egyszerű neurális hálót!
2. Döntésfák a gépi tanulásban
3. Egy intuitív bevezetés a gépi tanulásba
4. A passzív vs. aktív AI egyensúlya.
5 Use Cases of AI/Data/Machine Learning at Netflix
- Filmajánlások személyre szabása – Azok a felhasználók, akik megnézik A-t, valószínűleg megnézik B-t. Ez talán a Netflix legismertebb funkciója. A Netflix más, hasonló ízlésű felhasználók nézési előzményeit használja arra, hogy ajánlja, mit nézhetne meg legközelebb, hogy Ön továbbra is elkötelezett maradjon, és folytassa havi előfizetését a továbbiakra.
- A miniatűrök/művészeti alkotások automatikus generálása és személyre szabása – A Netflix egy meglévő film vagy műsor több ezer videóképét használja kiindulási pontként a miniatűrök generálásához, a Netflix megjegyzéseket fűz ezekhez a képekhez, majd rangsorolja az egyes képeket annak érdekében, hogy azonosítsa, mely miniatűrökre a legnagyobb valószínűséggel kattint. Ezek a számítások azon alapulnak, hogy mások, akik hasonlóak Önhöz, mire kattintottak. Az egyik eredmény az lehet, hogy azok a felhasználók, akik kedvelnek bizonyos színészeket / filmműfajokat, nagyobb valószínűséggel kattintanak bizonyos színészeket / képjellemzőket tartalmazó miniatűrképekre.
- Location Scouting for Movie Production (Pre-Production) – Adatok felhasználása annak eldöntésére, hogy hol és mikor érdemes forgatni egy filmet – az ütemezési korlátok (színészek / stáb elérhetősége), a költségvetés (helyszín, repülési / szállodai költségek) és a gyártási helyszín követelményei (nappali vagy éjszakai forgatás, az időjárási események kockázatának valószínűsége a helyszínen) figyelembevételével. Vegyük észre, hogy ez inkább egy adattudományi optimalizálási probléma, mint egy gépi tanulási modell, amely a múltbeli adatok alapján készít előrejelzéseket.
- Filmvágás (utómunka) – A múltbeli adatok felhasználása arra vonatkozóan, hogy a minőségellenőrzés mikor nem sikerült a múltban (amikor a feliratok szinkronizálása a hanggal/mozgásokkal a múltban hibás volt) – annak előrejelzésére, hogy mikor a leghasznosabb a kézi ellenőrzés egy egyébként nagyon időigényes és fáradságos folyamat során.
- Streaming Quality – A múltbeli nézési adatok felhasználása a sávszélesség-használat előrejelzésére, hogy segítsen a Netflixnek eldönteni, mikor kell a regionális szervereket gyorsabb betöltési időre gyorsítani a (várható) csúcskereslet idején.
Csak a Netflixnél az adattudomány vagy a gépi tanulás ezen 5 felhasználási esete / alkalmazása olyan skálázható hatással volt, hogy örökre megváltoztatta a technológiai tájképet és a felhasználói élményt milliók számára és még sokak számára. Ezeknek a mesterséges intelligenciával kapcsolatos megoldásoknak az elfogadása idővel csak erősödni fog.
De mielőtt ezek a felhasználási esetek olyan általánosak lettek volna, mint ma, és olyan felhasználók használták volna őket, mint Ön és én, valaki vagy egy csoport a Netflixen belül megfelelően összekapcsolta ezeket a mesterséges intelligencia megoldásokat egy üzleti igénnyel. E nélkül az üzleti kapcsolat nélkül ezek a felhasználási esetek egyszerűen csak égbenyúló ötletek lennének, amelyek a sok más nagyszerű ötlethez hasonlóan a naptár alján ülnének. Csak a megfelelő pozicionálás és a Netflix alapvető üzleti problémájához való kapcsolódás révén váltak ezek az ötletek olyan valósággá, amilyenek ma.

- Mi az üzleti igény/probléma?
- Filmajánlások: A probléma azonosítása
- Személyre szabott képminiatűr / műalkotás: A probléma azonosítása
- OK, a miniatűr képek fontosak. De pontosan mit finomítsunk?
- Termékmegfontolások a személyre szabott képminiatűrökben
- Milyen adatokkal rendelkezünk?
- Hogyan használja a Netflix az adatokat a felhasználói profilok érdekeltségi univerzumának felépítésére
- A Netflix-felhasználók matematikai egymáshoz való viszonyának újragondolása
- Mit tanult a Netflix ebből a sok adatból?
- Végezetül: Netflix (többnyire) helyesen alkalmazta az AI-t. Tanuljunk a megközelítésükből.
Mi az üzleti igény/probléma?
Figyeljük meg, hogy a fentebb azonosított felhasználási esetek mindegyikéhez egy-egy konkrét üzleti igény, cél vagy hipotézis kapcsolódik.
Ez abszolút fontos minden termékmenedzser számára – hogy elkerülje a technikai rajongó kísértését, aki intellektuális okokból csodálkozik az adattudomány / vagy az ML részletein anélkül, hogy egyértelműen azonosítaná a problémát vagy az üzleti igényt – potenciálisan értékes technikai erőforrásokat használ fel üzleti hatás nélkül.
A nap végén a termékmenedzsereknek megfelelően össze kell kapcsolniuk egy üzleti problémát egy adatgépes tanulási megoldással. El akarjuk kerülni, hogy olyan megoldásunk legyen, amely egy problémát kerget, különben a projekt elveszíti a lendületét a vállalaton belül: a mérnökök nem lesznek tisztában azzal, hogy mi az ő északi csillaguk, az érdekelt felek a szervezeten belül nem fognak bevásárolni, és nem osztják el a szükséges erőforrásokat a projekt sikeréhez, stb.
Győződjünk meg arról, hogy van-e olyan probléma, amelyhez az AI-megoldás közvetlenül kapcsolható
A gépi tanulás (ML) egy lehetséges AI-megoldás – de először meg kell határoznunk a problémát, mielőtt előírnánk a megoldást.
Mi az az üzleti eredmény, amelyet az ML segítségével szeretnénk elérni? Mert ez az alapvető üzleti igény határozza meg az alkalmazott ML-modellek paramétereit, az összegyűjtött és feldolgozott adatokat stb. Nem azért csináljuk az ML-t, hogy személyre szabást biztosítsunk, csak azért, mert érdekes technológia – egy üzleti problémához kell kötnünk. Az adattudósok specialisták az adatokból származó meglátások feltárásában, de a termékmenedzser feladata, hogy megfelelően összekapcsolja azt egy üzleti igénnyel vagy problémával, és összehasonlítsa a konkurens prioritásokkal.
Egy tech-rajongó például azt mondhatja:
Nem lenne klassz, ha egy epizódot hang segítségével elemezhetne / vitathatna meg a Netflixszel – és a Netflix a több ezer más felhasználónak az adott epizódra adott reakcióiból származó adatok alapján intelligens módon válaszolhatna a megjegyzéseire egy oda-vissza kétirányú párbeszédben?
Igen, ez egy elég nagyszerű felhasználási eset lenne, amely kihasználná a természetes nyelvi feldolgozást (NLP), hogy megértse az epizód utáni hozzászólásodat a kontextusban. Az NLP mellett ez a felhasználási eset felhasználja a szöveg-hang személyiségeket, valamint a hangulatelemzést, hogy hogyan érezte magát több ezer másik ember az adott epizódban történtekkel kapcsolatban, vagy hogyan éreznek egy bizonyos karakterrel kapcsolatban. Valóban, ez több élvonalbeli technológia gyönyörű összeolvadása egyetlen felhasználási esetben.
Ha ennek egy kísérleti MVP változata azt mutatná, hogy azok a felhasználók, akik részt vettek az új funkciójával, tovább maradtak, vagy gyakrabban tértek vissza, vagy segítettek a Netflixről szóló szájpropaganda növelésében, akkor ez további erőforrásokat indokolhatna. Az MVP megépítésére vonatkozó kezdeti döntés az érdekeltek stratégiai döntésétől függne, és nem feltétlenül a mérőszámok alapján kellene prioritást adni. Ez a vállalati stratégiától függ.
De amilyen szép felhasználói forgatókönyv a fenti, milyen problémát old meg?
Hogyan kapcsolódik ez a Netflix fő problémájához, a felhasználók havi előfizetésének fenntartásához? Ha összefügg, milyen (minőségi vagy mennyiségi) bizonyítékokkal tudjuk alátámasztani ezt a kapcsolatot?
És ha ez egy legitim megoldás erre a problémára, van-e ennek a megoldásnak egy egyszerűbb változata, amely ugyanúgy megoldja ezt a problémát, de technikailag kevésbé bonyolult? Például a hangbevitel és a hangkimenet helyett hogyan befolyásolná a pusztán szövegbevitel és a szövegkimenet összetettsége az erőfeszítés szintjét és a felhasználói elkötelezettségre gyakorolt hatást?
Mi lenne, ha egy társalgási AI-interfész a hangos rész nélkül (csak szöveg) a kívánt felhasználói elkötelezettség 80%-át érné el, de a fejlesztési erőfeszítésnek csak 40%-át igényelné? Érdemes lenne megfontolni egy ilyen alternatív útvonalat?
Milyen üzleti hatása lenne egy ilyen megoldásnak az erőfeszítés szintjéhez képest? Hogyan viszonyul ez az arány a backlogban szereplő egyéb konkurens feladatokhoz?
Ezek mind termékközpontú kérdések, amelyeket a PM-nek fel kell tennie annak érdekében, hogy a technológiai megoldásokat összehangolja az üzleti igényekkel. Mert végső soron az üzleti igény határozza meg az ML-modell paramétereit, nem pedig fordítva.
Nézzük tehát még egyszer a filmajánlásokat és a személyre szabott miniatűröket – mi a probléma vagy az üzleti cél?

Filmajánlások: A probléma azonosítása
Itt a probléma az, hogy a Netflix hatalmas tartalomgyűjteménnyel rendelkezik (a Netflix szerint több mint 100 millió különböző termékkel), amely folyamatosan változik, és a felhasználó számára túlterhelő lehet a fogyasztása. A felhasználók nem akarják, hogy frusztráltan találják meg az érdeklődési körüknek megfelelő tartalmat. Akkor tehát mi a legjobb módja annak, hogy az egyes felhasználók úgy fogyaszthassák ezeket az adatokat, hogy végső soron maximalizálják az előfizetési hűséget?
A termék céljai a következők:
- A nézettség növelése / fenntartása a fogyasztott percek száma tekintetében,
- A felfedezett címek számának növelése, a visszalátogatások gyakorisága
- A vállalat által sikerességi mérőszámként meghatározott minimális küszöbérték túllépése
- A havi előfizetési hűség általános növekedése / az előfizetői lemondások csökkenése
Személyre szabott képminiatűr / műalkotás: A probléma azonosítása
Ez a felhasználási eset a Filmajánlások részhalmaza. Tekintettel arra, hogy a felhasználónak filmajánlásokat adunk, most egy újabb üzleti / felhasználói problémával állunk szemben.
Probléma: Hogyan (és mikor) mutatjuk be a legjobban ezt a filmajánlást a felhasználónak úgy, hogy maximalizáljuk a nézettséget és a havi előfizetői hűséget?
Nos, az ajánlás egyik módja egy képminiatűr – de milyen miniatűr képet adjunk? És mennyire vagyunk biztosak abban, hogy egy kép miniatűrjének beállítása pozitívan befolyásolja a nézettséget vagy az előfizetői hűséget?
És mennyire fontos ez a miniatűr? Vannak erre vonatkozó adataink?
Adatok gyűjtése a hipotézis alátámasztására
Nos, biztosak lehetünk benne, hogy a Netflix valamelyik termékközpontú személye – egy 2014 előtti időszakban – pontosan ugyanezeket a kérdéseket tette fel belsőleg. És ez a személy vagy csoport együtt dolgozott (valószínűleg az UX és a kapcsolódó érdekeltekkel), hogy felhasználói tanulmányokat vagy adatokat állítson össze máshol, hogy bebizonyítsa, hogy valóban erős kapcsolat van a kép miniatűrje és a nézettség között.
Ez volt a hipotézisük: hogy a kép miniatűrjének művészi tartalmának beállítása erős kapcsolatot mutathat a nézettséggel.
Nos, kiderült, hogy a Netflix már 2014-ben tanulmányokat végzett, amelyek megmutatták, mennyire fontos ez a miniatűrkép:
Nick Nelson, a Netflix kreatív szolgáltatásokért felelős globális menedzsere elmondta, hogy a vállalat 2014 elején végzett kutatást, amely szerint a művészeti alkotás “nemcsak a legnagyobb befolyásoló tényező” a felhasználó döntése szempontjából, hogy mit nézzen, hanem a Netflix böngészése közben a fókusz több mint 82 százalékát is ez tette ki.
“Azt is láttuk, hogy a felhasználók átlagosan 1,8 másodpercet töltöttek minden egyes bemutatott cím mérlegelésével, miközben a Netflixen voltak” – írta Nelson. “Meglepett minket, hogy egy képnek mekkora hatása van arra, hogy egy tag megtalálja a nagyszerű tartalmat, és hogy milyen kevés időnk volt arra, hogy felkeltsük az érdeklődésüket.”
Egy kis, meggyőző miniatűr kép jelentheti a különbséget aközött, hogy valaki az egész hétvégét a Netflix legújabb Originals slágerének megtekintésével tölti, vagy elveszíti az érdeklődését, és átpattan egy konkurens szolgáltatásra, például a Hulu vagy hasonló OTT streaming szolgáltatásokhoz, mint az ESPN / Disney / HBO Go.”
A vizsgálatok alapján tehát a fenti hipotézis nagyon igaznak bizonyult.
OK, a miniatűr képek fontosak. De pontosan mit finomítsunk?
És hogyan kerül egy olyan strukturálatlan adathalmaz, mint egy csomó képminiatűr, egy digitális/matematikai gépi tanulási modellbe? Erre a második kérdésre a továbbiakban válaszolunk.
Először is, tekintve, hogy a miniatűrök mennyire fontosak voltak a felhasználó döntése szempontjából, hogy megnézzen valamit, hogyan tud a Netflix jobb miniatűröket generálni minden egyes felhasználó számára, hogy növelje annak esélyét, hogy a felhasználó megnézzen egy videót?
A film eredeti művészetét használva minden egyes ember számára egyedüli miniatűrként, valószínűleg nem a legmagasabb kattintási arányt fogja elérni. A vállalkozás valószínűleg az asztalon hagyja a kattintásokat (és a nézők streamelési idejét)!
Mi lenne, ha a Netflix minden egyes felhasználó számára egyedi, a kattintási arányok növelésére optimalizált miniatűrképet hozna létre?
Melyek azok a dolgok a kép miniatűrképén belül, amelyek a Netflix ellenőrzése alatt állnak, és amelyeket a kattintási arányok növelése érdekében módosíthatnak?

Melyik színész(ek)/karakter(ek) szerepeljen(ek) azon a miniatűrképen, ha van ilyen? Hányan? Melyik automatikusan generált képkocka vagy plakátvariáció lenne a legcsábítóbb egy adott felhasználó számára, hogy rákattintson rá? Milyen megvilágítás működik a legjobban? Szűrők?
Milyen adatokkal rendelkezünk más felhasználók korábbi kattintási szokásairól, amelyekből asszociációkat vonhatunk le, hogy segítsük ezt a méretarányos miniatűr-döntést?
- A filmajánlások kattintási arányának (CTR) növelése – elkötelezettséget jelez
- Hipotézis, hogy a magasabb elkötelezettségi arány magasabb előfizetői elégedettséghez és hűséghez vezet
Ez tehát egy igazán érdekes probléma a kép miniatűrjével, amely nagy hatással lehet annak valószínűségére, hogy valaki rákattint egy videóra és megnézi.
Ha a cél az, hogy a miniatűrök finomhangolásával maximalizáljuk a megtekintés valószínűségét – milyen termékdöntéseket kell figyelembe venni?
Termékmegfontolások a személyre szabott képminiatűrökben
A fenti felhasználási esetek mindegyikébe nem fogunk belemerülni, de a másodikba merüljünk bele egy kicsit részletesebben: Műalkotások / miniatűrök személyre szabása
Ez egy adatvezérelt személyre szabási funkció, amely a Filmajánló motor tetején helyezkedik el
Termékekkel kapcsolatos megfontolások
Az algoritmusok nagyszerűek, de vannak korlátaik. A termékmenedzsernek mindig előre kell gondolkodnia a lehetséges szélsőséges forgatókönyveken, amelyekben az algoritmus esetleg nem a legjobb eredményeket produkálja.
- Ideális esetben minden filmnek személyre szabott miniatűrképpel kell rendelkeznie, amely maximalizálja a kattintásokat. Mivel a Netflix rendelkezik adatokkal más, hasonló érdeklődésű emberek kattintási viselkedéséről, ésszerű feltételezés, hogy ha más, hasonló érdeklődésű és nézési előzményekkel rendelkező emberek magas kattintási arányt értek el egy bizonyos miniatűrnél, akkor valószínű, hogy ez a képminiatűr egy új személynél, akinek még nem ajánlották ezt a filmet/miniatűrt, jobban fog teljesíteni.
- A személyre szabott miniatűrnek figyelembe kell vennie más filmeket, amelyeket ugyanabban az időben ajánlanak – és azt, hogy ezek a képajánlások milyenek. Tegyük fel, hogy a Netflix 2 különböző Pókember-filmet ajánl egy felhasználónak egymás mellett – és mindkettőnél Pókember a kamera maszkjával lefelé néz. Az egyikben Tobey Maguire, a másikban Andrew Garfield látható. Nem lenne furcsa, ha a felhasználó egymás mellett látná Maguire és Garfield portréját Pókemberként, levett maszkkal? Valamit figyelembe kell venni, ha ez valaha is előfordulna.
Egy kép miniatűrje önmagában jól működhet, de ez nem biztos, hogy elég jó, amikor egy tucatnyi miniatűrből álló oldal jelenik meg. Ha mindegyiket úgy optimalizálják, hogy ugyanúgy nézzenek ki, akkor csoportként mindegyik kevésbé tűnik meggyőzőnek. Ezért fontos, hogy az egyes miniatűröket a többi megjelenített képpel együtt vizsgáljuk meg. - Az adatok nagyszerűek, de vigyázzunk az algoritmusokkal, amelyek túl jól végzik a munkájukat, ami nem szándékolt következményekhez / hamis pozitív eredményekhez vezet!
A statisztikában ezt I. típusú hibának nevezik – tévesen (vagy helytelenül) olyan képminiatűröket javasolnak, amelyeket nem kellene javasolnia.
Elképzelés: Nézzük csak meg az alábbi példát a Kristen Bell főszereplésével készült Like Father című filmről. Mégis, a Netflix algoritmusa (vitathatóan) hamis miniatűr ajánlásokat tett a fekete színészeket/színésznőket támogató képekről, amelyek nem igazán képviselik azt, amiről a film szólt, de mégis magasabb kattintási arányt tapasztaltak bizonyos etnikai közönség körében.

Azt kell tehát tudni, hogy a túlzottan optimalizált/személyre szabott élmény monoton felhasználói élményt hozhat létre, ami bizonyos esetekben félrevezető lehet a felhasználó számára. Az ismerős és a váratlan egészséges keverékét szeretnénk nyújtani, de ugyanakkor pontosan ábrázolni a tartalmat a felhasználó számára, hogy ne legyenek helytelenül félrevezetve.
Itt egy másik példa:
A Netflix a nagy valószínűségű kattintási arányok (CTR) alapján végül olyan miniatűröket mutatott be a felhasználóknak, amelyek megfeleltek a felhasználó etnikai hovatartozásának – – még akkor is, ha az adott (általában) mellékszereplő/színésznő nagyon kevés szereplési időt kapott az adott filmben.
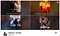
Míg ez egy adatokkal alátámasztott kezdeményezés, a felhasználó számára eléggé nyilvánvaló, hogy van egy olyan érzés, hogy az őszintétlenség félrevezető lehet a tekintetben, hogy a miniatűrkép pontosan képviseli az adott filmet (I. típusú hamis pozitív hiba).
Az algoritmust persze idővel valószínűleg finomhangolják majd, de a tanulság az, hogy ne vigyük túlzásba az adatok kihasználását – alkalmazzunk némi józan észt az egyensúly érdekében.
Nem akarjuk helytelenül félrevezetni a felhasználókat, vagy tudatosítani velük, hogy például faji hovatartozásuk miatt más elbánásban részesülnek.
4. Végül az algoritmusnak figyelembe kell vennie, hogy a felhasználó milyen miniatűr képeket látott korábban az adott filmhez kapcsolódóan, és arra kell törekednie, hogy következetes, nem zavaró felhasználói élményt nyújtson.
El akarjuk kerülni, hogy a felhasználó minden alkalommal más miniatűr képeket lásson, amikor az adott film megjelenik a felhasználó számára. Ez nem csak összezavarná a felhasználót, de a termékmenedzser számára is megnehezítené a kattintáshoz való hozzárendelést – melyik kép eredményezett magasabb kattintási arányt (CTR), ha folyamatosan változik? A PM-eknek képesnek kell lenniük arra, hogy minden új eredményt megfelelően hozzárendeljenek egy adott változáshoz – ezért fontos az adatok következetes hozzárendelésének fenntartása.
Ez tehát néhány dolog, amit egy termékmenedzser figyelembe vehet, amikor szélsőséges forgatókönyveket tervez, és amit az adatfelhasználás szélsőséges esetei eredményezhetnek. Ha már az adatoknál tartunk, konkrétan mi alapján dolgozik a Netflix?
Milyen adatokkal rendelkezünk?
Ennek 2 része van:
- Milyen adatokat használ a Netflix a személyre szabott miniatűrök/művek létrehozásához?
- Milyen adatokat használ a Netflix, hogy ezeket az egyedi miniatűröket a megfelelő személyre célozza?
Az első kérdéshez vegyük figyelembe, hogy
- A Stranger Things 1 órás epizódja >86 000 statikus videóképkockát tartalmaz
- Ezekhez a videóképkockákhoz egyenként hozzárendelhetők bizonyos attribútumok, amelyeket később az Aesthetic Visual Analysis (AVA) nevű eszközkészlet és algoritmusok segítségével kiszűrik a legjobb miniatűr-jelölteket. Ennek célja, hogy a videó minden statikus képkockájából megtalálja a legjobb egyéni miniatűr képet
- Netflix Annotation – A Netflix metaadatokat hoz létre minden egyes képkockához, beleértve a fényerőt (.67), az arcok számát (3) , a bőrszínt (.2), a meztelenség valószínűségét (.03), a mozgási elmosódás szintjét (4), a szimmetriát (.4)
- Netflix Image Ranking – A Netflix a fenti metaadatok alapján választja ki azokat a képeket, amelyek a legjobb minőségűek (jó megvilágítás, nincs mozgásbeli elmosódás, valószínűleg tartalmaznak néhány arcképet a főszereplőkről egy megfelelő szögből, nem tartalmaznak engedély nélküli márkás tartalmat stb.) és a leginkább kattinthatóak
A második kérdésre, hogy milyen adatokat használ a Netflix annak azonosítására, hogy kiket céloz meg ezekkel az egyedi generált miniatűr képekkel, vegyük figyelembe, hogy a Netflix nyomon követi:
- a megnézett filmek száma, az egyes műsorok megtekintett perceinek száma
- az egyes videók/sorozatok befejezési aránya
- az upvote-ok száma, mely filmeket kedvelték, stb
- a teljes megtekintett tartalom bármely konkrét műsorhoz köthető aránya (és így a felhasználó affinitásának szintje egy adott műsor vagy a kapcsolódó szereplők iránt)
- minden szezonális vagy heti trend, amely a felhasználó elkötelezettségi szintjéhez kapcsolódik, stb.
Érdekes megjegyezni, hogy 2018 közepén a Netflix megszüntette a felhasználói vélemények adatpontként való elfogadását, amelyeket korábban csak a weboldalán kért. Hogy miért? Mert ez a “funkció” valójában csökkenti a nézettséget, mivel a negatív vélemények elriasztják a felhasználókat egy-egy videó kipróbálásától. Ez csak egy újabb példa arra, hogy az üzleti igény felülírja a népszerű felhasználói igényt!
A Netflix tehát TONNÁNYI adattal rendelkezik minden egyes ügyfeléről – a megnézett videóktól a kattintott képekig. Mit kezdenek ezekkel az adatokkal?
Hogyan használja a Netflix az adatokat a felhasználói profilok érdekeltségi univerzumának felépítésére
Nos, arra használják, hogy összeállítsák minden egyes felhasználó 360 profilját, és matematikailag indexeljenek minden felhasználót több száz, esetleg több ezer különböző attribútum alapján.
Azért teszik ezt, hogy megpróbálják a hasonló érdeklődésű embereket csoportosítani, hogy az egyik felhasználó adatait felhasználva meg tudják jósolni a többi hasonló felhasználó valószínű viselkedését.
Hogyan működik ez a hasonló felhasználói profilok csoportosítása, és hogyan tudja egy termékmenedzser értelmezni az adatokat?
A mátrixokkal, vektorokkal és n-dimenziós jellemzőelemzéssel kapcsolatos összetett matematikát és algoritmusokat végigjárva úgy találtam, hogy a legkönnyebben egy több mint 10 dimenziós 3D-s térbeli ábrázoláson keresztül érthető meg, hogyan működik mindez.
Itt egy képernyőkép, amelyet a Google TensorBoard használatával készítettem a kézzel írt számjegyek mNIST adatbázisán. Ez egy fancy plot, az úgynevezett t-SNE plot – gyakorlatilag egy 3D-s ábrázolás sokkal több dimenzióról, mint csak 3. Ebben az esetben 10 dimenziót mutatunk (egyet minden számjegyhez 1-től 10-ig) egy 3D-s gömbszerű koordinátarendszerben.
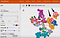
Minden kézzel írt számjegy pozíciója ebben a térbeli ábrázolásban egy vektorral írható le – számok koordinátaszerű sorozata, akárhány jellemző dimenzióban is.
A Netflix-felhasználók esetében hasonlóképpen, minden egyes felhasználói profil pozíciója a fenti ábrán számértékekkel írható le, amelyek mindegyike az adott felhasználó érdeklődésének egy-egy dimenzióját képviseli – beleértve a film műfaját, kedvenc színészeit/színésznőit, a film témáját stb.
A Netflix-felhasználók matematikai egymáshoz való viszonyának újragondolása
Tegyük fel a fenti számjegyes diagramban, hogy:
- “6” = romantikus vígjáték
- “4” = thriller
Ha egy felhasználót a Netflix “6”-osnak jelöl, akkor a fenti térbeli ábrázolásban (az alsó rész közelében) az összes többi türkizkék 6-os általános környezetébe kerül.
Hasonlóképpen, ha egy felhasználót a Netflix “4”-nek címkéz, akkor a fenti térbeli reprezentációban (a felső rész közelében) az összes többi magenta 4-es általános környezetébe kerül.

Figyeljük meg, hogy a türkizkék “6” régió (romantikus vígjáték) némileg átfedésben van a szürke “5” régióval. Ez analóg lehet azzal, hogy a romantikus vígjátékokat kedvelő felhasználók a paródia- vagy szatírafilmeket is kedvelhetik, mivel mindkettő nevetéssel jár.
Hasonlóképpen, mivel a magenta “4” régió (thriller) kissé közel van a rózsaszín “9” régióhoz – ez a rózsaszín 9-es régió azokat képviselheti, akik szeretik az akciófilmeket – matematikailag közelebb áll a thriller “4” régióhoz, mint a romantikus vígjáték “6” régióhoz.
Van ennek értelme? Tehát térbeli ábrázolás esetén a két felhasználói profil közötti távolság azt jelzi, hogy mennyire hasonló/különböző az ízlésük. Természetesen ez végtelenül bonyolulttá válhat, ha valaki, aki a romantikus vígjátékokat szereti, a thrillereket is szereti – de ennek az analógiának az a célja, hogy bemutassa a különböző kategóriák közötti matematikai/térbeli kapcsolatok általános elképzelését.
Az egymással rokon érdekcsoportok közelebb jelennek meg egymáshoz, és jó előrejelzői lehetnek annak, hogy mit fog szeretni egy felhasználó, feltéve, hogy a felhasználó valami mást is szeret a közelben.
A Netflix, vagy igazából bármelyik ML-modelleket kihasználó vállalat így hoz létre kapcsolatokat a látszólag strukturálatlan adatok között, és alakítja ezeket az adatokat számokká. Ezeknek a számoknak önmagukban nincs sok értelmük, de egymáshoz viszonyítva kezdenek értelmet nyerni.
Az alábbi Good Will Hunting film esetében egy vígjátékrajongóként azonosított felhasználónak egy Robin Williams (komikus) miniatűr képet mutatnának, míg egy másik, romantikus vígjátékrajongóként azonosított felhasználónak egy Matt Damon és Minnie Driver csókolózó miniatűr képet. Bár nem tökéletes, a Netflix algoritmusai szerint a felhasználói profil jellemzőin alapuló ilyen szintű személyre szabás növeli a kattintási arányok valószínűségét.

Foglaljuk tehát össze. Egy csomó Netflix képminiatűr egy csomó strukturálatlan adat.
De amint a Netflix minden egyes miniatűrhöz megjegyzést fűz, és metaadatokat rendel mindegyikhez, hogy leírja, mi van az adott miniatűrben – most már numerikus reprezentációval rendelkezünk a strukturálatlan adatokról.
Ezt a numerikus reprezentációt vektorok formájában ábrázoljuk egy 3D-s gömbön, ahogy fentebb tettük – és most a Netflix elkezd kapcsolatokat kialakítani az adatpontok között.
A Netflix ezután megtalálja azokat az adatpontokat, amelyek viszonylag közel vannak egymáshoz, és felhasználja őket a jövőbeli kattintási viselkedés előrejelzéséhez. Ha a jóslatok rossznak vagy jónak bizonyulnak, akkor ennek megfelelően módosítják ezeknek a jellemzőknek a matematikai elhelyezését, amíg a modell idővel egyre jobbá és jobbá nem válik.
Így alakítja tehát a Netflix a strukturálatlan adatokat matematikai ábrázolásokká. Az adatpontok közötti relációs távolságot használja alapul a képminiatűr ajánlások elkészítéséhez és javításához.
Mit tanult a Netflix ebből a sok adatból?
Most, hogy már tudjuk, hogyan alakítja a Netflix a képeket számokká egy gépi tanulási modellben, milyen felismerésekre jutott a Netflix a sok év alatt elvégzett adatfeldolgozás és A/B tesztek alapján?
Nos, amellett, hogy megtanulták azt a több millió egyedi miniatűr képet, amelyek a felhasználókat idővel hűséges előfizetőkké alakították át, íme néhány további dolog, amit a Netflix megtanult arra vonatkozóan, hogy mi működik a miniatűr képek tekintetében:
- Mutass közelképeket érzelmileg kifejező arcokról
- Mutass az embereknek gonosztevőket a hősök helyett
- Ne mutass háromnál több szereplőt
Végezetül: Netflix (többnyire) helyesen alkalmazta az AI-t. Tanuljunk a megközelítésükből.
A Netflix fenomenális munkát végzett az AI, az adattudomány és a gépi tanulás “helyes” alkalmazásában – olyan termékalapú megközelítést alkalmaz, amely először az üzleti igényre, majd az AI-megoldásra összpontosít, nem pedig fordítva.
A megfelelő alkalmazás esetén az AI csodákra képes.
Láttuk, hogy a mesterséges intelligencia megoldások mennyire hatékonyak lehetnek az élmény személyre szabásában, ami mind a Netflix számára előnyös az előfizetések, mind a felhasználók számára az általános elégedettség szempontjából.
A “túlzásba vitt” algoritmusok korlátait is láttuk, és konkrét példákat tárgyaltunk, amikor a Netflix algoritmusa félrevezető miniatűröket mutatott a színes bőrűeknek, mert az algoritmus a kattintásokra optimalizált, gyakorlatilag “becsapva” a felhasználókat a csalik kattintására. Ez még akkor is megtörtént, amikor ez a miniatűrkép nem reprezentálta pontosan az adott videót.
Egyetlen algoritmus sem lesz tökéletes az emberi élmény minden árnyalatának figyelembevételében. Valójában a mérőszámok kihasználására tervezett algoritmusok pontosan ezt teszik – ezért a termékmenedzser feladata, hogy a tervezéssel vagy a csapat más tagjaival együttműködve megtalálja a módját az algoritmusok ezen hiányosságainak kiküszöbölésének.
A jövőben az AI integrációja a társadalomban, valamint a vállalati vállalati térben is egyre jobban fog terjedni.
A technológusok hajlamosak lehetnek arra, hogy előírják a meglévő AI-megoldásokat, de valójában a leghatékonyabb módja az AI bevezetésének az, ahogyan a Netflix tette – először az üzleti szempontok alapján.
Mélyebbre ásva láthatja, hogy a Netflix támogató adatokat generált, mielőtt a stratégiai lépést megtette volna.
Amint az AI, az adattudomány és a gépi tanulás világa tovább növekszik, mi termékmenedzserek mindannyian leckét vagy kettőt vehetünk a Netflix játékkönyvéből, amikor az AI megoldások megfelelő alkalmazásáról van szó.