
Die Präsenz von KI in der heutigen Gesellschaft wird immer allgegenwärtiger – vor allem, weil große Unternehmen wie Netflix, Amazon, Facebook, Spotify und viele andere kontinuierlich KI-bezogene Lösungen einsetzen, die täglich direkt (oft hinter den Kulissen) mit den Verbrauchern interagieren.
Wenn diese KI-bezogenen Lösungen richtig auf geschäftliche Probleme angewandt werden, können sie wirklich einzigartige Lösungen bieten, die im Laufe der Zeit skaliert und verbessert werden und sowohl für das Unternehmen als auch für den Benutzer erhebliche Auswirkungen haben. Aber was bedeutet es, eine KI-Lösung „richtig anzuwenden“? Bedeutet das, dass es einen falschen Weg gibt? Aus der Produktperspektive lautet die kurze Antwort: Ja. Warum das so ist, werden wir später in diesem Artikel näher erläutern.
Überblick: Zunächst werden wir 5 Anwendungsfälle für Data Science oder maschinelles Lernen bei Netflix skizzieren. Dann werden wir einige geschäftliche Anforderungen im Vergleich zu technischen Überlegungen erörtern, die ein Produktmanager anstellen würde. Dann werden wir etwas tiefer in den vielleicht interessantesten dieser 5 Anwendungsfälle eintauchen und herausfinden, welches geschäftliche Problem damit gelöst werden soll.
1. Bauen wir ein einfaches neuronales Netz!
2. Entscheidungsbäume im maschinellen Lernen
3. Eine intuitive Einführung in das maschinelle Lernen
4. Das Gleichgewicht von passiver vs. aktiver KI.
5 Anwendungsfälle von KI/Daten/Maschinellem Lernen bei Netflix
- Personalisierung von Filmempfehlungen – Nutzer, die A sehen, sehen wahrscheinlich auch B. Dies ist vielleicht die bekannteste Funktion von Netflix. Netflix nutzt den Filmverlauf anderer Nutzer mit ähnlichem Geschmack, um Ihnen zu empfehlen, was Sie sich als Nächstes ansehen könnten, damit Sie sich weiter mit dem Film beschäftigen und Ihr monatliches Abonnement fortsetzen.
- Automatische Erstellung und Personalisierung von Miniaturbildern / Artwork – Netflix verwendet Tausende von Videobildern aus einem bestehenden Film oder einer Serie als Ausgangspunkt für die Erstellung von Miniaturbildern, kommentiert diese Bilder und ordnet dann jedes Bild ein, um festzustellen, welche Miniaturbilder die höchste Wahrscheinlichkeit haben, dass Sie darauf klicken. Diese Berechnungen beruhen darauf, was andere, die Ihnen ähnlich sind, angeklickt haben. Ein Ergebnis könnte sein, dass Nutzer, die bestimmte Schauspieler/Filmgenres mögen, eher auf Thumbnails mit bestimmten Schauspielern/Bildattributen klicken.
- Location Scouting für die Filmproduktion (Pre-Production) – Verwendung von Daten, um zu entscheiden, wo und wann ein Filmset am besten gedreht werden kann – unter Berücksichtigung von Terminvorgaben (Verfügbarkeit von Schauspielern/Crews), Budget (Drehort, Flug-/Hotelkosten) und Anforderungen an die Produktionsszene (Dreharbeiten bei Tag oder Nacht, Wahrscheinlichkeit von Wetterrisiken an einem Drehort). Beachten Sie, dass es sich hierbei eher um ein datenwissenschaftliches Optimierungsproblem handelt als um ein Modell für maschinelles Lernen, das Vorhersagen auf der Grundlage von Vergangenheitsdaten trifft.
- Filmschnitt (Postproduktion) – Verwendung historischer Daten darüber, wann Qualitätskontrollen in der Vergangenheit fehlgeschlagen sind (wenn die Synchronisierung von Untertiteln mit Ton/Bewegungen in der Vergangenheit fehlerhaft war), um vorherzusagen, wann eine manuelle Prüfung am vorteilhaftesten ist, was ansonsten ein sehr zeit- und arbeitsintensiver Prozess sein könnte.
- Streaming-Qualität – Verwendung von Daten aus der Vergangenheit zur Vorhersage der Bandbreitennutzung, um Netflix bei der Entscheidung zu helfen, wann regionale Server für schnellere Ladezeiten bei (erwarteten) Nachfragespitzen zwischengespeichert werden sollen.
Diese 5 Anwendungsfälle/Anwendungen von Data Science oder maschinellem Lernen allein bei Netflix haben so große Auswirkungen, dass sie die Technologielandschaft und die Nutzererfahrung für Millionen von Menschen für immer verändert haben und noch verändern werden. Die Akzeptanz dieser KI-bezogenen Lösungen wird mit der Zeit nur noch zunehmen.
Aber bevor diese Anwendungsfälle so alltäglich waren wie heute und von Nutzern wie Ihnen und mir verwendet wurden, hat jemand oder eine Gruppe innerhalb von Netflix diese KI-Lösungen mit einem geschäftlichen Bedarf verbunden. Ohne diese geschäftliche Verknüpfung wären diese Anwendungsfälle einfach nur unausgegorene Ideen, die wie so viele andere großartige Ideen in der Schublade liegen. Nur durch die richtige Positionierung und die Verbindung mit dem Kernproblem von Netflix wurden diese Ideen zu der Realität, die sie heute sind.

- Was ist das geschäftliche Bedürfnis/Problem?
- Filmempfehlungen: Identifizierung des Problems
- Personalisierte Bildvorschaubilder / Kunstwerke: Identifizierung des Problems
- OK, Vorschaubilder sind wichtig. Aber was genau optimieren wir?
- Produktüberlegungen bei personalisierten Bildvorschaubildern
- Welche Daten haben wir?
- Wie Netflix Daten verwendet, um ein Universum von Nutzerprofilen zu erstellen
- Die Netflix-Nutzer in mathematischer Beziehung zueinander sehen
- Was hat Netflix aus all diesen Daten gelernt?
- Zusammenfassend: Netflix setzt KI (meistens) richtig ein. Lernen wir von ihrem Ansatz.
Was ist das geschäftliche Bedürfnis/Problem?
Beachten Sie, dass jeder der oben genannten Anwendungsfälle mit einem bestimmten Geschäftsbedarf, Ziel oder einer Hypothese verbunden ist.
Dies ist absolut wichtig für jeden Produktmanager – um der Versuchung des Technik-Enthusiasten zu entgehen, der sich aus intellektuellen Gründen in die Details der Datenwissenschaft / oder ML vertieft, ohne das Problem oder den geschäftlichen Bedarf klar zu identifizieren – was möglicherweise wertvolle technische Ressourcen ohne geschäftliche Auswirkungen verbraucht.
Am Ende des Tages müssen Produktmanager ein geschäftliches Problem mit einer Lösung für maschinelles Lernen richtig verbinden. Wir wollen vermeiden, dass wir eine Lösung haben, die einem Problem hinterherläuft, sonst verliert das Projekt innerhalb des Unternehmens an Schwung: Die Ingenieure sind sich nicht im Klaren darüber, was ihr „Nordstern“ ist, die Stakeholder im gesamten Unternehmen werden nicht mitziehen und nicht die notwendigen Ressourcen bereitstellen, um das Projekt zum Erfolg zu führen, usw.
Stellen Sie sicher, dass es ein Problem gibt, mit dem eine KI-Lösung direkt in Verbindung gebracht werden kann
Maschinelles Lernen (ML) ist eine potenzielle KI-Lösung – aber wir müssen zuerst das Problem definieren, bevor wir diese Lösung vorschreiben können.
Was ist das Geschäftsergebnis, das wir mit ML erreichen wollen? Denn von dieser zentralen Geschäftsanforderung hängen die Parameter der verwendeten ML-Modelle ab, welche Daten gesammelt und verarbeitet werden usw. Wir setzen ML nicht ein, um Personalisierung anzubieten, nur weil es eine interessante Technologie ist – wir müssen sie mit einem Geschäftsproblem verknüpfen. Datenwissenschaftler sind Spezialisten darin, Erkenntnisse aus den Daten zu gewinnen, aber es ist die Aufgabe des Produktmanagers, sie mit einem geschäftlichen Bedarf oder Problem zu verknüpfen und sie mit konkurrierenden Prioritäten zu vergleichen.
Ein Technikbegeisterter könnte zum Beispiel sagen:
Wäre es nicht cool, wenn Sie eine Episode mit Netflix per Sprache analysieren/debattieren könnten – und Netflix, mit Dateninput von Tausenden von anderen Nutzern zu dieser Episode, könnte intelligent auf Ihre Kommentare in einem hin- und hergehenden 2-Wege-Dialog reagieren?
Ja, das wäre ein ziemlich genialer Anwendungsfall, der die Verarbeitung natürlicher Sprache (NLP) nutzt, um Ihren Kommentar nach der Episode im Kontext zu verstehen. Zusätzlich zu NLP werden in diesem Anwendungsfall Text-zu-Stimme-Persönlichkeiten sowie Stimmungsanalysen darüber verwendet, wie Tausende von anderen über die Geschehnisse in dieser Folge oder über eine bestimmte Figur denken. Dies ist in der Tat eine wunderbare Verschmelzung mehrerer Spitzentechnologien in einem Anwendungsfall.
Wenn sich in einer MVP-Pilotversion zeigen würde, dass die Nutzer, die sich mit dieser neuen Funktion beschäftigen, länger bleiben oder öfter wiederkommen oder dazu beitragen, dass mehr Mundpropaganda über Netflix gemacht wird, dann könnte dies weitere Ressourcen rechtfertigen. Die anfängliche Entscheidung, dieses MVP zu bauen, würde von einer strategischen Entscheidung der Stakeholder abhängen, die nicht notwendigerweise durch eine Metrik priorisiert wird.
Aber so schön das obige Szenario für den Nutzer auch ist, welches Problem löst es?
Wie hängt es mit dem Hauptproblem von Netflix zusammen, die Nutzer jeden Monat im Abonnement zu halten? Wenn es damit zusammenhängt, welche (qualitativen oder quantitativen) Beweise haben wir, um diese Beziehung zu untermauern?
Und wenn dies eine legitime Lösung für das Problem ist, gibt es eine einfachere Version dieser Lösung, die das Problem gleichermaßen lösen könnte, aber technisch weniger komplex ist? Wie würde sich zum Beispiel die Komplexität einer reinen Texteingabe und -ausgabe anstelle der Spracheingabe und -ausgabe auf den Aufwand und die Auswirkungen auf die Benutzeraktivität auswirken?
Was wäre, wenn eine dialogorientierte KI-Schnittstelle ohne den Sprachteil (nur Text) 80 % der angestrebten Benutzeraktivität erreichen würde, aber nur 40 % des Entwicklungsaufwands erfordern würde? Würde es sich lohnen, einen solchen alternativen Weg in Betracht zu ziehen?
Welche geschäftlichen Auswirkungen hätte eine solche Lösung im Vergleich zum Aufwand? Wie sieht dieses Verhältnis im Vergleich zu anderen konkurrierenden Aufgaben im Backlog aus?
Dies sind alles produktorientierte Fragen, die ein PM stellen sollte, um technologische Lösungen mit den geschäftlichen Anforderungen in Einklang zu bringen. Denn letztendlich sind es die geschäftlichen Anforderungen, die die Parameter eines ML-Modells bestimmen, nicht umgekehrt.
Werfen wir also noch einmal einen Blick auf die Filmempfehlungen und die personalisierten Miniaturansichten – was ist das Problem oder das Geschäftsziel?

Filmempfehlungen: Identifizierung des Problems
Das Problem besteht darin, dass Netflix über eine riesige Sammlung von Inhalten verfügt (laut Netflix über 100 Millionen verschiedene Produkte), die sich ständig ändern und für einen Nutzer überwältigend sein können. Die Nutzer wollen nicht frustriert sein, wenn sie Inhalte finden, die ihren Interessen entsprechen. Wie kann man also jedem Nutzer ermöglichen, diese Daten so zu nutzen, dass die Abonnementtreue maximiert wird?
Ziele des Produkts sind unter anderem:
- Steigerung / Beibehaltung der Zuschauerzahl in Bezug auf die Anzahl der konsumierten Minuten,
- Steigerung der Anzahl der erkundeten Titel, Häufigkeit des erneuten Einloggens
- Überschreiten der Mindestschwelle, die das Unternehmen als Erfolgskennzahl festlegt
- Gesamtanstieg der monatlichen Abonnementtreue / Rückgang der Abonnentenkündigungen
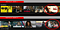
Personalisierte Bildvorschaubilder / Kunstwerke: Identifizierung des Problems
Dieser Anwendungsfall ist eine Teilmenge der Filmempfehlungen. Da dem Benutzer Filmempfehlungen zur Verfügung gestellt werden, haben wir nun ein weiteres Geschäfts-/Benutzerproblem.
Problem: Wie (und wann) präsentieren wir dem Benutzer diese Filmempfehlungen am besten auf eine Weise, die die Zuschauerzahlen und die monatliche Abonnententreue maximiert?
Nun, eine Möglichkeit, diese Empfehlung zu geben, ist ein Bild-Thumbnail – aber welche Art von Thumbnail stellen wir zur Verfügung? Und wie zuversichtlich sind wir, dass sich die Optimierung einer Bildminiatur positiv auf die Zuschauerzahlen oder die Abonnententreue auswirkt?
Und wie wichtig ist diese Miniaturansicht? Haben wir dafür Daten?
Daten zur Untermauerung der Hypothese sammeln
Sie können sicher sein, dass eine produktorientierte Person bei Netflix – zu einem Zeitpunkt vor 2014 – intern genau dieselben Fragen gestellt hat. Und diese Person oder Gruppe arbeitete zusammen (wahrscheinlich mit UX und verwandten Interessengruppen), um Nutzerstudien oder Daten an anderer Stelle zusammenzustellen, um zu beweisen, dass es tatsächlich eine starke Verbindung zwischen einer Bildminiatur und der Zuschauerzahl gibt.
Das war ihre Hypothese: dass die Anpassung des künstlerischen Inhalts einer Bildminiatur eine starke Verbindung zur Zuschauerzahl haben könnte.
Wie sich herausstellte, hat Netflix bereits 2014 Studien durchgeführt, die zeigen, wie wichtig das Vorschaubild ist:
Nick Nelson, Netflix‘ Global Manager of Creative Services, erklärte, dass das Unternehmen Anfang 2014 Untersuchungen durchgeführt hat, die ergaben, dass die künstlerische Gestaltung nicht nur den größten Einfluss auf die Entscheidung eines Nutzers hat, was er sich ansehen möchte, sondern dass sie auch mehr als 82 % seiner Aufmerksamkeit beim Surfen auf Netflix ausmacht.
„Wir haben auch festgestellt, dass die Nutzer im Durchschnitt 1,8 Sekunden über jeden Titel nachdenken, der ihnen auf Netflix präsentiert wird“, schrieb Nelson. „Wir waren überrascht, wie viel Einfluss ein Bild darauf hat, dass ein Mitglied großartige Inhalte findet, und wie wenig Zeit wir hatten, um ihr Interesse zu wecken.“
Ein kleines, überzeugendes Vorschaubild kann den Unterschied ausmachen, ob man ein ganzes Wochenende damit verbringt, den neuesten Netflix-Hit zu sehen, oder ob man das Interesse verliert und zu einem konkurrierenden Dienst wie Hulu oder ähnlichen OTT-Streaming-Diensten wie ESPN / Disney / HBO Go wechselt.
Die obige Hypothese hat sich also aufgrund von Studien als sehr zutreffend erwiesen.
OK, Vorschaubilder sind wichtig. Aber was genau optimieren wir?
Und wie wird ein unstrukturierter Datensatz wie eine Reihe von Miniaturbildern in ein digitales/mathematisches maschinelles Lernmodell eingespeist? Wir werden diese zweite Frage weiter unten beantworten.
Erstens: Wenn man bedenkt, wie wichtig das Vorschaubild für die Entscheidung eines Nutzers war, sich etwas anzusehen, wie kann Netflix dann bessere Vorschaubilder für jeden Nutzer generieren, um die Wahrscheinlichkeit zu erhöhen, dass ein Nutzer sich ein Video ansieht?
Die Verwendung des Originalbildes des Films als einziges Vorschaubild für jede einzelne Person wird höchstwahrscheinlich nicht die höchsten Klickraten erzielen.
Was wäre, wenn Netflix für jeden Nutzer ein anderes Vorschaubild erstellen würde, das für höhere Klickraten optimiert ist?
Was kann Netflix an den Vorschaubildern ändern, um die Klickraten zu erhöhen?

Welche(r) Schauspieler/Charakter(e) sollte(n) auf diesem Thumbnail zu sehen sein, wenn überhaupt? Wie viele? Welcher automatisch generierte Rahmen oder welche Plakatvariante wäre für einen bestimmten Nutzer am verlockendsten, um darauf zu klicken? Welche Beleuchtung funktioniert am besten? Filter?
Welche Daten haben wir über das frühere Klickverhalten anderer Nutzer, aus denen wir Assoziationen ziehen können, um diese Miniaturbild-Entscheidung im großen Maßstab zu unterstützen?
- Steigerung der Klickraten (CTR) von Filmempfehlungen – ein Zeichen für Engagement
- Hypothese: Höhere Engagementraten führen zu höherer Abonnentenzufriedenheit und -treue
Das ist also ein wirklich interessantes Problem mit der Bildminiatur, das einen großen Einfluss auf die Wahrscheinlichkeit haben kann, dass jemand auf ein Video klickt und es sich ansieht.
Wenn das Ziel darin besteht, die Wahrscheinlichkeit des Betrachtens zu maximieren, indem das Vorschaubild optimiert wird – welche Produktentscheidungen sind dann zu berücksichtigen?
Produktüberlegungen bei personalisierten Bildvorschaubildern
Wir werden nicht auf jeden der oben genannten Anwendungsfälle eingehen, aber lassen Sie uns den zweiten etwas näher betrachten: Artwork / Thumbnail Personalization
Dies ist eine datengesteuerte Personalisierungsfunktion, die auf die Filmempfehlungsmaschine aufgesetzt wird
Produktüberlegungen
Algorithmen sind großartig, aber sie haben auch Grenzen. Ein Produktmanager sollte sich immer Gedanken über mögliche Szenarien machen, in denen der Algorithmus nicht die besten Ergebnisse liefert.
- Jeder Film sollte idealerweise ein personalisiertes Vorschaubild haben, das die Anzahl der Klicks maximiert. Da Netflix über Daten zum Klickverhalten anderer Personen mit ähnlichen Interessen verfügt, ist es eine vernünftige Hypothese zu vermuten, dass, wenn andere Personen mit ähnlichen Interessen und ähnlichem Sehverhalten eine hohe Klickrate auf ein bestimmtes Thumbnail hatten, es wahrscheinlich ist, dass dieses Thumbnail bei einer neuen Person, der dieser Film / dieses Thumbnail noch nicht empfohlen wurde, funktionieren wird.
- Das personalisierte Thumbnail sollte andere Filme berücksichtigen, die zur gleichen Zeit empfohlen werden – und was diese Bildempfehlungen sind. Nehmen wir an, Netflix empfiehlt einem Nutzer zwei verschiedene Spiderman-Filme nebeneinander – und beide zeigen Spiderman mit ausgeschalteter Kameramaske. Einer ist Tobey Maguire und der andere Andrew Garfield. Wäre es nicht seltsam, wenn der Benutzer beide Porträts von Maguire und Garfield als Spiderman ohne Maske nebeneinander sehen würde? Das sollte man bedenken, falls das jemals vorkommen sollte.
Ein einzelnes Thumbnail könnte gut funktionieren, aber das ist vielleicht nicht gut genug, wenn eine Seite mit einem Dutzend Thumbnails angezeigt wird. Wenn alle Thumbnails auf das gleiche Aussehen hin optimiert sind, kann es sein, dass die einzelnen Thumbnails in ihrer Gesamtheit weniger überzeugend wirken. Daher ist es wichtig, die einzelnen Thumbnails zusammen mit den anderen Inhalten zu betrachten. - Daten sind großartig, aber Vorsicht vor Algorithmen, die ihre Arbeit zu gut machen und zu unbeabsichtigten Folgen / falsch positiven Ergebnissen führen!
In der Statistik nennt man dies einen Fehler vom Typ I – ein fälschlicherweise (oder unsachgemäß) vorgeschlagenes Bild-Thumbnail, das nicht vorgeschlagen werden sollte.
Ein Beispiel dafür: Sehen Sie sich das folgende Beispiel von Like Father an, einem Film mit Kristen Bell in der Hauptrolle. Der Algorithmus von Netflix hat (wohl) falsche Thumbnail-Empfehlungen für schwarze Hauptdarsteller ausgesprochen, die nicht wirklich das Thema des Films repräsentieren, aber eine höhere Klickrate bei bestimmten ethnischen Zielgruppen aufweisen.

Seien Sie sich also bewusst, dass ein übermäßig optimiertes/personalisiertes Erlebnis zu einer monotonen Nutzererfahrung führen kann, die in einigen Fällen für den Nutzer irreführend sein kann. Wir wollen eine gesunde Mischung aus Vertrautem und Unerwartetem bieten, aber auch den Inhalt für den Nutzer genau darstellen, damit er nicht in die Irre geführt wird.
Hier ein weiteres Beispiel:
Aufgrund der hohen Wahrscheinlichkeit von Klickraten (CTRs) hat Netflix den Nutzern Miniaturansichten präsentiert, die mit der ethnischen Zugehörigkeit eines Nutzers übereinstimmten – auch wenn der (normalerweise) Nebendarsteller/die Schauspielerin in dem Film nur eine sehr geringe Filmzeit hatte.
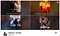
Auch wenn es sich hierbei um eine datengestützte Initiative handelt, ist es für den Nutzer ziemlich offensichtlich, dass es ein Gefühl der Unaufrichtigkeit gibt, das irreführend sein kann, wenn ein Vorschaubild den Film genau repräsentiert (falsch positiver Fehler des Typs I).
Natürlich wird dieser Algorithmus im Laufe der Zeit wahrscheinlich feiner abgestimmt werden, aber die Lektion hier ist, dass man es nicht übertreiben sollte, wenn man aus Daten Kapital schlägt – man sollte etwas gesunden Menschenverstand anwenden, um es auszugleichen.
Wir wollen die Nutzer nicht in die Irre führen oder sie wissen lassen, dass sie beispielsweise aufgrund ihrer Rasse anders behandelt werden.
4. Schließlich sollte der Algorithmus berücksichtigen, welche Miniaturbilder der Nutzer zuvor im Zusammenhang mit diesem Film gesehen hat, und darauf abzielen, eine konsistente, nicht verwirrende Nutzererfahrung zu bieten.
Wir wollen vermeiden, dass der Nutzer jedes Mal, wenn er den Film sieht, andere Miniaturbilder sieht. Dies würde nicht nur den Benutzer verwirren, sondern es würde auch einem Produktmanager die Zuordnung eines Klicks erschweren – welches Bild führte zu einer höheren Klickrate (CTR), wenn es sich ständig ändert? PMs müssen in der Lage sein, jedes neue Ergebnis einer bestimmten Änderung zuzuordnen – daher ist die Aufrechterhaltung einer konsistenten Datenattribution wichtig.
Das sind also einige Dinge, die ein Produktmanager bei der Entwicklung von Edge-Case-Szenarien berücksichtigen würde und zu welchen Extremfällen der Datennutzung es kommen kann. Apropos Daten, worauf stützt sich Netflix konkret?
Welche Daten haben wir?
Das hat zwei Teile:
- Welche Daten verwendet Netflix, um diese personalisierten Miniaturansichten/Grafiken zu erstellen?
- Welche Daten verwendet Netflix, um diese individuell erstellten Miniaturansichten der entsprechenden Person zuzuordnen?
Bei der ersten Frage ist zu bedenken, dass
- eine einstündige Episode von „Stranger Things“ >86.000 statische Videoframes
- Diesen Videoframes können einzeln bestimmte Attribute zugewiesen werden, die später verwendet werden, um die besten Thumbnail-Kandidaten durch eine Reihe von Tools und Algorithmen namens Aesthetic Visual Analysis (AVA) herauszufiltern. Damit soll aus jedem statischen Bild des Videos das beste benutzerdefinierte Miniaturbild gefunden werden
- Netflix Annotation – Netflix erstellt Metadaten für jedes Bild, einschließlich Helligkeit (.67), Anzahl der Gesichter (3), Hauttöne (.2), Wahrscheinlichkeit von Nacktheit (.03), Grad der Bewegungsunschärfe (4), Symmetrie (.4)
- Netflix Image Ranking – Netflix verwendet die oben genannten Metadaten, um bestimmte Bilder herauszufiltern, die von höchster Qualität (gute Beleuchtung, keine Bewegungsunschärfe, enthält wahrscheinlich eine Gesichtsaufnahme der Hauptfiguren aus einem angemessenen Winkel, enthält keine nicht autorisierten Markeninhalte usw.) und am besten anklickbar sind
Für die zweite Frage, welche Daten Netflix verwendet, um zu ermitteln, an wen sich diese benutzerdefinierten Vorschaubilder richten sollen, ist zu bedenken, dass Netflix verfolgt:
- Anzahl der angesehenen Filme, Anzahl der Minuten jeder angesehenen Sendung
- Anteil der Fertigstellung für jedes Video/jede Serie
- Anzahl der Bewertungen, welche Filme favorisiert wurden usw.
- Anteil der insgesamt angesehenen Inhalte, die einer bestimmten Sendung zuzuordnen sind (und daher der Grad der Affinität des Nutzers zu einer bestimmten Sendung oder den dazugehörigen Darstellern)
- alle saisonalen oder wöchentlichen Trends in Bezug auf das Engagement eines Nutzers usw.
Interessanterweise hat Netflix Mitte 2018 aufgehört, Nutzerbewertungen als Datenpunkt zu akzeptieren, die zuvor nur auf der Website abgefragt wurden. Why? Weil diese „Funktion“ tatsächlich die Zuschauerzahlen verringert, da negative Bewertungen die Nutzer davon abhalten, ein Video auszuprobieren. Dies ist nur ein weiteres Beispiel dafür, wie ein Geschäftsbedürfnis ein beliebtes Nutzerbedürfnis überlagert!
Netflix hat also eine TONNE von Daten über jeden seiner Kunden – von angesehenen Videos bis zu angeklickten Bildern. Was macht Netflix mit all diesen Daten?
Wie Netflix Daten verwendet, um ein Universum von Nutzerprofilen zu erstellen
Nun, sie verwenden sie, um ein 360-Profil jedes Nutzers zu erstellen und jeden Nutzer anhand von Hunderten, möglicherweise Tausenden von verschiedenen Attributen mathematisch zu indizieren.
Sie tun dies, um zu versuchen, Menschen mit ähnlichen Interessen zu gruppieren, damit sie die Daten eines Nutzers verwenden können, um das wahrscheinliche Verhalten anderer ähnlicher Nutzer vorherzusagen.
Wie funktioniert diese Gruppierung ähnlicher Nutzerprofile und wie kann ein Produktmanager die Daten sinnvoll nutzen?
Nachdem ich mich mit der komplexen Mathematik und den Algorithmen im Zusammenhang mit Matrizen, Vektoren und der n-dimensionalen Merkmalsanalyse befasst habe, fand ich, dass der einfachste Weg, um zu verstehen, wie dies funktioniert, eine räumliche 3D-Darstellung mit mehr als 10 Dimensionen ist.
Hier ist ein Screenshot, den ich gemacht habe, als ich Googles TensorBoard für die mNIST-Datenbank mit handgeschriebenen Ziffern verwendet habe. Es handelt sich um eine ausgefallene Darstellung, die t-SNE-Darstellung genannt wird – effektiv eine 3D-Darstellung von viel mehr Dimensionen als nur 3. In diesem Fall zeigen wir 10 Dimensionen (eine für jede Ziffer von 1 bis 10) auf einem kugelähnlichen 3D-Koordinatensystem.
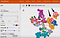
Die Position jeder handgeschriebenen Ziffer in dieser räumlichen Darstellung kann durch einen Vektor beschrieben werden – eine koordinatenähnliche Reihe von Zahlen über beliebig viele Merkmalsdimensionen.
Auch bei Netflix-Nutzern könnte die Position jedes Nutzerprofils im obigen Diagramm durch numerische Werte beschrieben werden, die jeweils eine individuelle Dimension des Interesses dieses Nutzers darstellen – einschließlich Filmgenre, Lieblingsschauspieler, Filmthema usw.
Die Netflix-Nutzer in mathematischer Beziehung zueinander sehen
Lassen Sie uns im obigen Zahlendiagramm so tun, als ob:
- „6“ = romantische Komödie
- „4“ = Thriller
Wenn ein Nutzer von Netflix als „6“ bezeichnet wird, dann wird er/sie in der obigen räumlichen Darstellung in der Nähe aller anderen türkisfarbenen 6er platziert (in der Nähe des Bodens).
Wenn ein Nutzer von Netflix als „4“ bezeichnet wird, wird er/sie in die allgemeine Nähe aller anderen magentafarbenen 4er in der obigen räumlichen Darstellung (oben) platziert.

Beachten Sie, wie sich die türkisfarbene „6“-Region (romantische Komödie) etwas mit der grauen „5“-Region überlappt. Dies könnte analog dazu sein, dass Nutzer, die romantische Komödien mögen, auch Parodie- oder Satire-Filme mögen, weil sie beide mit Lachen zu tun haben.
Gleichermaßen, da die magentafarbene „4“-Region (Thriller) etwas nahe an der rosafarbenen „9“-Region liegt – könnte diese rosafarbene „9“-Region diejenigen repräsentieren, die Action-Filme mögen – mathematisch gesehen näher an der Thriller-„4“-Region als an der romantischen Komödien-„6“-Region.
Hat das einen Sinn? In der räumlichen Darstellung zeigt der Abstand zwischen zwei Nutzerprofilen also an, wie ähnlich/unterschiedlich ihre Vorlieben sind. Natürlich kann dies unendlich komplexer werden, wenn jemand, der romantische Komödien mag, auch Thriller mag – aber der Zweck dieser Analogie ist es, die allgemeine Idee der mathematischen / räumlichen Beziehungen zwischen verschiedenen Kategorien zu zeigen.
Interessengruppen, die miteinander verwandt sind, erscheinen näher beieinander und können gute Prädiktoren dafür sein, was ein Nutzer mögen wird, wenn er etwas anderes in der Nähe mag.
Auf diese Weise schafft Netflix, oder wirklich jedes Unternehmen, das ML-Modelle einsetzt, Beziehungen zwischen scheinbar unstrukturierten Daten und verwandelt diese Daten in Zahlen. Diese Zahlen machen für sich genommen nicht viel Sinn, aber zusammen in Relation zueinander ergeben sie einen Sinn.
Für den gleichen Film Good Will Hunting würde einem Nutzer, der als Komödienfan identifiziert wurde, ein Robin Williams (Komiker) Thumbnail angezeigt, während einem anderen Nutzer, der als Fan romantischer Komödien identifiziert wurde, ein küssendes Thumbnail mit Matt Damon und Minnie Driver angezeigt würde. Die Algorithmen von Netflix sind zwar nicht perfekt, lassen aber vermuten, dass ein solches Maß an Personalisierung auf der Grundlage von Nutzerprofilen die Wahrscheinlichkeit von Klickraten erhöht.

Fassen wir also zusammen. Ein Haufen Netflix-Bild-Thumbnails ist ein Haufen unstrukturierter Daten.
Aber sobald Netflix jedes Thumbnail mit Anmerkungen versieht und jedem Metadaten zuweist, um zu beschreiben, was in diesem Thumbnail enthalten ist – haben wir jetzt eine numerische Darstellung dieser unstrukturierten Daten.
Geben Sie diese numerische Darstellung in Form von Vektoren auf einer 3D-Kugel an, wie wir es oben getan haben, und Netflix beginnt, Beziehungen zwischen Datenpunkten herzustellen.
Netflix findet dann Datenpunkte, die relativ nahe beieinander liegen, und verwendet sie, um das zukünftige Klickverhalten vorherzusagen. Wenn die Vorhersagen schlecht oder gut ausfallen, wird die mathematische Positionierung dieser Merkmale entsprechend angepasst, bis das Modell im Laufe der Zeit immer besser wird.
So verwandelt Netflix also unstrukturierte Daten in mathematische Darstellungen. Es nutzt den relationalen Abstand zwischen Datenpunkten als Grundlage für die Erstellung und Verbesserung von Empfehlungen für Bildminiaturen.
Was hat Netflix aus all diesen Daten gelernt?
Nachdem wir nun wissen, wie Netflix Bilder in einem Modell für maschinelles Lernen in Zahlen umwandelt, welche Erkenntnisse hat Netflix aus all der Datenverarbeitung und den A/B-Tests gewonnen, die das Unternehmen über so viele Jahre hinweg durchgeführt hat?
Abgesehen von den Millionen einzelner Vorschaubilder, die die Nutzer im Laufe der Zeit in treue Abonnenten verwandelt haben, hat Netflix noch ein paar zusätzliche Erkenntnisse darüber gewonnen, was in Bezug auf Vorschaubilder funktioniert:
- Nahaufnahmen von emotional ausdrucksstarken Gesichtern zeigen
- Bösewichte statt Helden zeigen
- Nicht mehr als drei Charaktere zeigen
Zusammenfassend: Netflix setzt KI (meistens) richtig ein. Lernen wir von ihrem Ansatz.
Netflix hat phänomenale Arbeit bei der Anwendung von KI, Data Science und maschinellem Lernen auf die „richtige Art“ geleistet – mit einem produktbasierten Ansatz, der sich zuerst auf die geschäftlichen Anforderungen und dann auf die KI-Lösung konzentriert, und nicht umgekehrt.
Wenn sie richtig angewendet wird, kann KI Wunder bewirken.
Wir haben gesehen, wie effektiv KI-Lösungen bei der Personalisierung des Erlebnisses sein können, was sowohl Netflix in Bezug auf die Abonnements als auch den Nutzern in Bezug auf die Gesamtzufriedenheit zugute kommt.
Wir haben auch die Grenzen von Algorithmen gesehen, die es „übertreiben“, und haben spezifische Beispiele diskutiert, in denen der Netflix-Algorithmus irreführende Vorschaubilder für farbige Menschen anzeigte, weil der Algorithmus für Klicks optimiert war und die Nutzer effektiv dazu verleitete, auf Köder zu klicken. Dies geschah selbst dann, wenn das Thumbnail das Video nicht korrekt darstellte.
Kein Algorithmus ist perfekt, wenn es darum geht, alle Nuancen der menschlichen Erfahrung zu berücksichtigen. Tatsächlich werden Algorithmen, die darauf ausgelegt sind, Metriken auszunutzen, genau das tun – daher ist es die Aufgabe des Produktmanagers, mit Designern oder anderen Teammitgliedern zusammenzuarbeiten, um Wege zu finden, diese Unzulänglichkeiten in Algorithmen zu beheben.
In Zukunft wird die Integration von KI in der Gesellschaft und im Unternehmensbereich immer mehr zunehmen.
Technologen neigen vielleicht dazu, bestehende KI-Lösungen vorzuschreiben, aber der effektivste Weg, KI einzuführen, ist die Art und Weise, wie Netflix es getan hat – zunächst aus einer geschäftsorientierten Perspektive.
Gehen Sie in die Tiefe und Sie werden sehen, dass Netflix unterstützende Daten generiert hat, bevor es den strategischen Schritt nach vorne gemacht hat.
Während die Welt der KI, der Datenwissenschaft und des maschinellen Lernens weiter wächst, können wir Produktmanager alle ein oder zwei Lektionen aus dem Netflix-Drehbuch nehmen, wenn es darum geht, KI-Lösungen richtig einzusetzen.