
La présence de l’IA dans la société d’aujourd’hui devient de plus en plus omniprésente – notamment parce que de grandes entreprises comme Netflix, Amazon, Facebook, Spotify et bien d’autres déploient continuellement des solutions liées à l’IA qui interagissent directement (souvent dans les coulisses) avec les consommateurs tous les jours.
Lorsqu’elles sont correctement appliquées aux problèmes de l’entreprise, ces solutions liées à l’IA peuvent fournir des solutions vraiment uniques qui évoluent et s’améliorent au fil du temps, créant un impact significatif pour l’entreprise et l’utilisateur. Mais que signifie » appliquer correctement » une solution d’IA ? Cela signifie-t-il qu’il existe une mauvaise façon de procéder ? Du point de vue du produit, la réponse courte est oui, et nous verrons pourquoi c’est plus tard dans cet article, alors que nous creusons plus profondément.
Overview : Tout d’abord, nous allons présenter 5 cas d’utilisation de la science des données ou de l’apprentissage automatique chez Netflix. Nous discuterons ensuite de certains besoins commerciaux par rapport aux considérations techniques qu’un chef de produit examinerait. Puis nous plongerons un peu plus profondément dans ce qui est peut-être le plus intéressant de ces 5 cas d’utilisation, car nous identifions quel problème commercial il cherche à résoudre.
1. Construisons un simple réseau neuronal !
2. Les arbres de décision dans l’apprentissage automatique
3. Une introduction intuitive à l’apprentissage automatique
4. L’équilibre entre l’IA passive et l’IA active.
5 Cas d’utilisation de l’IA/données/apprentissage automatique chez Netflix
- Personnalisation des recommandations de films – Les utilisateurs qui regardent A sont susceptibles de regarder B. C’est peut-être la caractéristique la plus connue d’un Netflix. Netflix utilise l’historique de visionnage d’autres utilisateurs ayant des goûts similaires pour vous recommander ce que vous pourriez être le plus intéressé à regarder ensuite afin que vous restiez engagé et que vous continuiez votre abonnement mensuel pour plus.
- Génération automatique et personnalisation des vignettes / œuvres d’art – En utilisant des milliers d’images vidéo d’un film ou d’une émission existante comme point de départ pour la génération de vignettes, Netflix annote ces images puis classe chaque image dans le but d’identifier les vignettes qui ont la plus grande probabilité d’entraîner votre clic. Ces calculs sont basés sur ce sur quoi d’autres personnes qui vous ressemblent ont cliqué. Une constatation pourrait être que les utilisateurs qui aiment certains acteurs / genres de films sont plus susceptibles de cliquer sur les vignettes avec certains acteurs / attributs d’image.
- Repérage de lieux pour la production de films (pré-production) – Utilisation de données pour aider à décider où et quand tourner au mieux un plateau de tournage – compte tenu des contraintes de calendrier (disponibilité des acteurs / de l’équipe), du budget(lieu, coûts des vols / hôtels), et des exigences de la scène de production (tournage de jour vs nuit, probabilité de risques d’événements météorologiques dans un lieu). Notez qu’il s’agit davantage d’un problème d’optimisation de science des données plutôt que d’un modèle d’apprentissage automatique qui fait des prédictions basées sur des données passées.
- Montage de films (post-production) -Utilisation de données historiques des moments où les contrôles de qualité ont échoué dans le passé (lorsque la synchronisation des sous-titres avec le son/mouvements a été désactivée dans le passé) – pour prédire quand une vérification manuelle est la plus bénéfique dans ce qui pourrait autrement être un processus très long et laborieux.
- Qualité du streaming – Utilisation des données de visionnage passées pour prédire l’utilisation de la bande passante afin d’aider Netflix à décider quand mettre en cache les serveurs régionaux pour des temps de chargement plus rapides pendant les pics de demande (prévus).
Ces 5 cas d’utilisation / applications de la science des données ou de l’apprentissage automatique rien que chez Netflix ont eu un tel impact évolutif qu’ils ont changé à jamais le paysage technologique et l’expérience des utilisateurs pour des millions de personnes et d’autres à venir. L’adoption de ces solutions liées à l’IA ne fera que se renforcer au fil du temps.
Mais avant que ces cas d’utilisation soient aussi courants qu’aujourd’hui et utilisés par des utilisateurs comme vous et moi, quelqu’un ou un groupe au sein de Netflix a correctement relié ces solutions d’IA à un besoin commercial. Sans ce lien commercial, ces cas d’utilisation n’auraient été que des idées fantaisistes au fond d’un carnet de commandes, comme tant d’autres bonnes idées. Ce n’est que par un positionnement et une connexion appropriés avec le problème commercial central de Netflix que ces idées sont devenues la réalité qu’elles sont aujourd’hui.

- Quel est le besoin/problème de l’entreprise ?
- Les recommandations de films : Identifier le problème
- Vignettes d’images personnalisées / œuvres d’art : Identification du problème
- OK, les vignettes sont importantes. Mais qu’est-ce qu’on modifie exactement ?
- Considérations de produit dans les vignettes d’image personnalisées
- Quelles sont les données dont nous disposons ?
- Comment Netflix utilise les données pour construire un univers d’intérêts de profils d’utilisateurs
- Réimaginer les utilisateurs de Netflix en relation mathématique les uns avec les autres
- Qu’a appris Netflix de toutes ces données ?
- En conclusion : Netflix a déployé l’IA (principalement) de la bonne manière. Apprenons de leur approche.
Quel est le besoin/problème de l’entreprise ?
Notez que dans chacun des cas d’utilisation que j’ai identifiés ci-dessus, chacun est associé à un besoin commercial, un objectif ou une hypothèse spécifique.
C’est absolument important pour tout gestionnaire de produit – pour éviter la tentation du passionné de technologie qui s’émerveille dans les détails de la science des données / ou du ML pour des raisons intellectuelles sans identifier clairement le problème ou le besoin commercial – utilisant potentiellement des ressources techniques précieuses sans impact commercial.
En fin de compte, les gestionnaires de produits doivent correctement connecter un problème commercial à une solution d’apprentissage automatique des données. Nous voulons éviter d’avoir une solution qui court après un problème, sinon le projet perdra son élan au sein de l’entreprise : les ingénieurs ne sauront pas clairement quelle est leur étoile du Nord, les parties prenantes de l’ensemble de l’organisation n’adhéreront pas et n’alloueront pas les ressources nécessaires à la réussite du projet, etc.
S’assurer qu’il existe un problème auquel une solution d’IA peut être directement reliée
L’apprentissage machine (ML) est une solution d’IA potentielle – mais nous devons d’abord définir le problème avant de prescrire cette solution.
Quel est le résultat commercial que nous essayons d’atteindre avec le ML ? Parce que ce besoin métier central est ce qui détermine les paramètres des modèles ML utilisés, quelles données sont collectées et traitées, etc. Nous ne faisons pas du ML pour fournir une personnalisation simplement parce que c’est une technologie intéressante – nous devons la relier à un problème commercial. Les scientifiques des données sont des spécialistes de la découverte d’idées à partir des données, mais c’est le rôle du chef de produit de les relier correctement à un besoin ou un problème commercial et de les comparer à des priorités concurrentes.
Par exemple, un passionné de technologie pourrait dire :
Ne serait-il pas cool si vous pouviez analyser/débattre d’un épisode en utilisant la voix avec Netflix – et Netflix, avec l’entrée de données provenant des réactions de milliers d’autres utilisateurs à cet épisode, pourrait répondre intelligemment à vos commentaires dans un dialogue bidirectionnel aller-retour ?
Oui, ce serait un cas d’utilisation assez génial exploitant le traitement du langage naturel (NLP) pour comprendre votre commentaire post-épisode dans son contexte. En plus du NLP, ce cas d’utilisation utilise des personnalités de type texte-voix ainsi que l’analyse des sentiments de milliers d’autres personnes sur ce qui s’est passé dans cet épisode, ou sur ce qu’elles pensent d’un certain personnage. En effet, il s’agit d’une belle fusion de plusieurs technologies de pointe dans un seul cas d’utilisation.
Si une version pilote MVP de ceci montrait que les utilisateurs qui se sont engagés avec sa nouvelle fonctionnalité sont restés plus longtemps ou sont revenus plus souvent ou ont aidé à stimuler plus de bouche à oreille sur Netflix, alors cela pourrait justifier des ressources supplémentaires. La décision initiale de construire ce MVP dépendrait de la décision stratégique prise par les parties prenantes, pas nécessairement priorisée par la métrique. Cela dépendra de la stratégie de l’entreprise.
Mais aussi beau scénario d’utilisateur que ce qui précède, quel problème cela résout-il ?
Comment est-il lié au problème principal de Netflix, qui est de garder les utilisateurs abonnés chaque mois ? Si c’est lié, quelles preuves (qualitatives ou quantitatives) avons-nous pour soutenir cette relation ?
Et si c’est une solution légitime à ce problème, existe-t-il une version plus simple de cette solution qui pourrait également accomplir ce problème mais être moins complexe techniquement ? Par exemple, au lieu d’une entrée et d’une sortie vocales, comment la complexité d’une simple entrée et sortie de texte pourrait-elle affecter le niveau d’effort et l’impact sur l’engagement de l’utilisateur ?
Et si une interface d’IA conversationnelle sans la partie vocale (juste du texte) atteignait 80 % de l’engagement prévu de l’utilisateur mais ne nécessitait que 40 % de l’effort de développement ? Cela vaudrait-il la peine d’envisager une telle voie alternative ?
Quel serait l’impact commercial d’une telle solution par rapport au niveau d’effort ? Comment ce ratio se compare-t-il à celui d’autres tâches concurrentes dans le backlog ?
Ce sont toutes des questions axées sur le produit qu’un PM devrait poser afin d’aligner les solutions technologiques sur les besoins de l’entreprise. Car en fin de compte, c’est le besoin métier qui détermine les paramètres d’un modèle ML, et non l’inverse.
Regardons donc une fois de plus les recommandations de films et ces vignettes personnalisées – quel est le problème ou l’objectif métier ?

Les recommandations de films : Identifier le problème
Ici le problème est que Netflix a une énorme collection de contenu (plus de 100 millions de produits différents, selon Netflix) qui change constamment et peut être écrasant pour un utilisateur à consommer. Les utilisateurs ne veulent pas être frustrés lorsqu’ils cherchent du contenu correspondant à leurs intérêts. Alors, quelle est la meilleure façon de permettre à chaque utilisateur de consommer ces données d’une manière qui, en fin de compte, maximise la fidélité de l’abonnement ?
Les objectifs du produit comprennent :
- Augmenter / maintenir l’audience en termes de # minutes consommées,
- Augmentation du # de titres explorés, fréquence de reconnexion
- Dépassement de tout seuil minimum que l’entreprise détermine comme étant une mesure de succès
- Augmentation globale de la fidélité de l’abonnement mensuel / diminution des résiliations d’abonnement
Vignettes d’images personnalisées / œuvres d’art : Identification du problème
Ce cas d’utilisation est un sous-ensemble des recommandations de films. Étant donné que les recommandations de films sont fournies à l’utilisateur, nous avons maintenant un autre problème d’entreprise / utilisateur.
Problème : comment (et quand) présenter au mieux cette recommandation de film à l’utilisateur d’une manière qui maximise le nombre de spectateurs et la fidélité des abonnés mensuels ?
Bien, une façon de fournir cette recommandation est par le biais d’une vignette d’image – mais quel type de vignette fournissons-nous ? Et dans quelle mesure sommes-nous convaincus que le fait de modifier une vignette d’image aura un effet positif sur l’audience ou la fidélité des abonnés ?
Et quelle est l’importance de cette vignette ? Avons-nous des données pour cela ?
Recueillir des données pour soutenir cette hypothèse
Bien, vous pouvez être assuré qu’une personne axée sur le produit chez Netflix – à un moment avant 2014 – se posait exactement ces mêmes questions en interne. Et cette personne ou ce groupe a travaillé ensemble (probablement avec UX et des parties prenantes connexes) pour mettre en place des études d’utilisateurs ou des données ailleurs, afin de prouver qu’il y avait effectivement un lien fort entre une vignette d’image et le nombre de spectateurs.
C’était leur hypothèse : que l’ajustement du contenu artistique d’une vignette d’image pouvait avoir un lien fort avec le nombre de spectateurs.
Bien, il s’avère qu’en 2014, Netflix a mené des études montrant à quel point cette vignette est importante :
Nick Nelson, directeur mondial des services créatifs de Netflix, a expliqué que l’entreprise a mené des recherches au début de 2014 qui ont révélé que l’œuvre d’art était « non seulement le plus grand influenceur » pour la décision d’un utilisateur sur ce qu’il veut regarder, mais qu’elle constituait également plus de 82% de leur attention lors de la navigation sur Netflix.
« Nous avons également constaté que les utilisateurs passaient en moyenne 1,8 seconde à considérer chaque titre qui leur était présenté lorsqu’ils étaient sur Netflix », écrit Nelson. « Nous avons été surpris par l’impact d’une image sur un membre qui trouve du bon contenu, et par le peu de temps que nous avions pour capter leur intérêt. »
Une petite vignette convaincante pourrait faire la différence entre vous faire passer tout le week-end à regarder le dernier succès Originals de Netflix ou perdre votre intérêt et rebondir vers un service concurrent comme Hulu ou des services de streaming OTT similaires comme ESPN / Disney / HBO Go.
Donc, sur la base d’études, l’hypothèse ci-dessus s’est avérée très vraie.
OK, les vignettes sont importantes. Mais qu’est-ce qu’on modifie exactement ?
Et comment un ensemble de données non structurées comme un tas de vignettes d’images est introduit dans un modèle numérique/mathématique d’apprentissage automatique ? Nous répondrons à cette deuxième question plus loin.
Premièrement, étant donné l’importance de la vignette dans la décision d’un utilisateur de regarder quelque chose, comment Netflix peut-il générer de meilleures vignettes pour chaque utilisateur afin d’augmenter les chances qu’un utilisateur regarde une vidéo ?
L’utilisation de l’art original du film comme seule vignette utilisée pour chaque personne ne produira très probablement pas les taux de clics les plus élevés. L’entreprise laisse probablement des clics (et du temps de visionnage) sur la table !
Et si Netflix créait sur mesure une vignette différente pour chaque utilisateur, optimisée pour augmenter les taux de clics ?
Quels sont les éléments d’une vignette d’image qui sont sous le contrôle de Netflix et qu’ils peuvent modifier pour augmenter ces taux de clics ?

Quel(s) acteur(s)/personnage(s) devrait figurer sur cette vignette, le cas échéant ? Combien ? Quelle variante de cadre ou d’affiche générée automatiquement serait la plus incitative pour qu’un utilisateur particulier clique dessus ? Quel éclairage fonctionne le mieux ? Filtres ?
Quelles données avons-nous sur le comportement passé des autres utilisateurs en matière de clics pouvons-nous tirer des associations pour aider à informer cette décision de vignette à l’échelle ?
- Augmenter les taux de clics (CTR) des recommandations de films – signifiant l’engagement
- Hypothèse selon laquelle des taux d’engagement plus élevés entraîneront une plus grande satisfaction et une plus grande fidélité des abonnés
C’est donc un problème vraiment intéressant avec la vignette d’image qui peut avoir un impact énorme sur la probabilité que quelqu’un clique sur une vidéo et la regarde.
Si l’objectif est de maximiser cette probabilité de regarder en peaufinant la vignette – quelles sont les décisions de produit à prendre en compte ?
Considérations de produit dans les vignettes d’image personnalisées
Nous n’allons pas plonger dans chacun des cas d’utilisation ci-dessus, mais plongeons un peu plus dans le second : Personnalisation des œuvres d’art / vignettes
Il s’agit d’une fonctionnalité de personnalisation basée sur les données qui se trouve au-dessus du moteur de recommandation de films
Considérations sur le produit
Les algorithmes sont formidables, mais ils ont des limites. Un gestionnaire de produit devrait toujours penser à l’avance à des scénarios de cas limite possibles dans lesquels l’algorithme pourrait ne pas produire les meilleurs résultats.
- Chaque film devrait idéalement avoir une vignette personnalisée qui maximise les clics. Puisque Netflix a des données sur le comportement de clics d’autres personnes ayant des intérêts similaires, c’est une hypothèse raisonnable pour deviner que si d’autres personnes ayant des intérêts et un historique de visionnage similaires ont eu un taux de clics élevé sur une certaine vignette, alors il est probable que cette vignette d’image sera performante sur une nouvelle personne qui n’a pas encore été recommandée ce film / vignette.
- La vignette personnalisée devrait prendre en considération d’autres films là sont recommandés en même temps – et ce que sont ces recommandations d’images. Disons que Netflix recommande 2 films différents de Spiderman à un utilisateur côte à côte – et ils ont tous deux Spiderman face au masque de la caméra. L’un est de Tobey Maguire et l’autre d’Andrew Garfield. Ne serait-il pas étrange pour l’utilisateur de voir les deux portraits de Maguire et Garfield dans le rôle de Spiderman, sans masque, côte à côte ? Quelque chose à prendre en compte si cela devait se produire un jour.
Une vignette d’image pourrait bien fonctionner de manière isolée, mais cela peut ne pas être suffisant lorsqu’une page d’une douzaine de vignettes s’affiche. Si elles sont toutes optimisées pour avoir le même aspect, alors en tant que groupe, chacune d’entre elles peut sembler moins convaincante. Il sera donc important de regarder chaque vignette en même temps que ce qui est présenté par ailleurs. - Les données, c’est bien, mais attention aux algorithmes qui font trop bien leur travail, ce qui entraîne des conséquences involontaires / des faux positifs !
En statistiques, on appelle cela une erreur de type I – suggérer faussement (ou incorrectement) une vignette d’image qui ne devrait pas être suggérée.
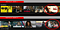
Cas concret : Il suffit de regarder l’exemple ci-dessous de Like Father, un film mettant en vedette Kristen Bell. Pourtant, l’algorithme de Netflix a (sans doute) fait de fausses recommandations de vignettes de soutien aux acteurs/actrices noirs qui ne représentent pas vraiment ce dont parlait le film, mais a connu un taux de clics plus élevé parmi certains publics ethniques.

Soyez donc conscient qu’une expérience trop optimisée / personnalisée pourrait créer une expérience utilisateur monotone qui, dans certains cas, peut être trompeuse pour l’utilisateur. Nous voulons fournir un mélange sain du familier avec l’inattendu, mais aussi dépeindre avec précision le contenu à l’utilisateur afin qu’il ne soit pas induit en erreur de manière inappropriée.
Voici un autre exemple :
Sur la base d’une probabilité élevée de taux de clics (CTR), Netflix a fini par présenter des vignettes aux utilisateurs qui correspondaient à l’ethnicité d’un utilisateur – – même lorsque cet acteur/actrice de soutien (habituellement) avait très peu de temps d’antenne dans ce film.
Bien qu’il s’agisse d’une initiative soutenue par des données, il est assez évident pour l’utilisateur qu’il y a un sentiment de manque de sincérité qui peut être trompeur en termes de vignette représentant précisément ce film (erreur de faux positif de type I).
Bien sûr, cet algorithme sera probablement affiné au fil du temps, mais la leçon ici est de ne pas en faire trop lorsqu’on capitalise sur les données – appliquez un peu de bon sens pour l’équilibrer.
Nous ne voulons pas induire indûment les utilisateurs en erreur ou leur faire savoir qu’ils sont traités différemment en raison de leur race, par exemple.
4. Enfin, l’algorithme devrait prendre en considération les vignettes que l’utilisateur a vues précédemment en association avec ce film et viser à fournir une expérience utilisateur cohérente et non confuse.
Nous voulons éviter que l’utilisateur voie différentes vignettes chaque fois que ce film apparaît à l’utilisateur. Non seulement cela rendrait l’utilisateur confus, mais il serait également difficile pour un gestionnaire de produit d’attribuer une attribution à un clic – quelle image a entraîné un taux de clics (CTR) plus élevé lorsqu’elle change constamment ? Les PM doivent être en mesure d’attribuer correctement chaque nouveau résultat à un changement spécifique – il est donc important de maintenir une attribution cohérente des données.
Ce sont donc des éléments qu’un chef de produit prendrait en compte lors de la conception de scénarios de cas limite et de ce que les cas extrêmes d’utilisation des données peuvent entraîner. En parlant de données, sur quoi Netflix travaille-t-il spécifiquement ?
Quelles sont les données dont nous disposons ?
Il y a 2 parties à cela :
- Quelles sont les données utilisées par Netflix pour créer ces vignettes / œuvres d’art personnalisées ?
- Quelles sont les données utilisées par Netflix pour cibler ces vignettes créées sur mesure vers la personne appropriée ?
Pour la première question, considérez que
- Un épisode d’une heure de Stranger Things comporte >86 000 images vidéo statiques
- Ces images vidéo peuvent chacune se voir attribuer individuellement certains attributs qui sont ensuite utilisés pour filtrer les meilleurs candidats aux vignettes grâce à un ensemble d’outils et d’algorithmes appelés Analyse visuelle esthétique (AVA). Celle-ci est conçue pour trouver la meilleure image de vignette personnalisée parmi chaque image statique de la vidéo
- Annotation Netflix – Netflix crée des métadonnées pour chaque image, notamment la luminosité (,67), le nombre de visages (3) , les tons de peau (,2), la probabilité de nudité (,03), le niveau de flou de mouvement (4), la symétrie (.4)
- Rapport d’images Netflix – Netflix utilise les métadonnées de ce qui précède pour choisir les images spécifiques qui sont de la plus haute qualité (bon éclairage, pas de flou de mouvement, contient probablement un certain plan de visage des personnages principaux sous un angle décent, ne contient pas de contenu de marque non autorisé, etc.) et les plus cliquables
Pour la deuxième question de savoir quelles données Netflix utilise pour identifier vers qui cibler ces vignettes générées sur mesure, considérez que Netflix suit :
- # de films regardés, # de minutes de chaque émission regardée
- % d’achèvement pour chaque vidéo/série
- # de upvotes, quels films ont été favorisés, etc
- % du contenu global regardé qui est attribuable à une émission spécifique (et donc le niveau d’affinité que l’utilisateur a avec une émission spécifique ou les membres du casting associés)
- toutes les tendances saisonnières ou hebdomadaires liées au niveau d’engagement d’un utilisateur, etc.
Intéressant de noter qu’à la mi 2018, Netflix a cessé d’accepter les avis des utilisateurs comme point de données, qu’il sollicitait auparavant uniquement sur son site web. Pourquoi ? Parce que cette « fonctionnalité » réduit en réalité le nombre de spectateurs, car les avis négatifs découragent les utilisateurs d’essayer une vidéo. Ce n’est qu’un autre exemple de la façon dont un besoin commercial supplante un besoin populaire des utilisateurs !
Donc Netflix a une TONNE de données sur chacun de ses clients – des vidéos regardées aux images cliquées. Que font-ils avec toutes ces données ?
Comment Netflix utilise les données pour construire un univers d’intérêts de profils d’utilisateurs
Eh bien, ils les utilisent pour établir un profil à 360° de chaque utilisateur et indexer mathématiquement chaque utilisateur selon des centaines, voire des milliers d’attributs différents.
Ils font cela pour essayer de regrouper les personnes ayant des intérêts similaires afin de pouvoir utiliser les données d’un utilisateur pour aider à prédire le comportement probable d’autres utilisateurs similaires.
Comment ce regroupement de profils d’utilisateurs similaires fonctionne-t-il et comment un chef de produit donne-t-il du sens à ces données ?
Après avoir parcouru les mathématiques et les algorithmes complexes associés aux matrices, aux vecteurs et à l’analyse des caractéristiques à n dimensions, j’ai trouvé que la façon la plus simple de comprendre comment cela fonctionne est à travers une représentation spatiale en 3D de 10+ dimensions.
Voici une capture d’écran que j’ai prise en utilisant le TensorBoard de Google sur la base de données mNIST de chiffres manuscrits. C’est un tracé fantaisiste appelé le tracé t-SNE – effectivement une représentation 3D de beaucoup plus de dimensions que 3. Dans ce cas, nous montrons 10 dimensions (une pour chaque chiffre de 1 à 10) sur un système de coordonnées 3D de type sphère.
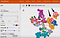
La position de chaque chiffre écrit à la main dans cette représentation spatiale peut être décrite par un vecteur – une série de nombres ressemblant à des coordonnées sur un nombre quelconque de dimensions de caractéristiques.
De même, avec les utilisateurs de Netflix, la position de chaque profil d’utilisateur dans le graphique ci-dessus pourrait être décrite par des valeurs numériques représentant chacune une dimension individuelle de l’intérêt de cet utilisateur – notamment le genre de film, les acteurs/actrices préférés, le sujet du film, etc.
Réimaginer les utilisateurs de Netflix en relation mathématique les uns avec les autres
Faisons comme si dans le diagramme de chiffres ci-dessus :
- « 6 » = comédie romantique
- « 4 » = thriller
Si un utilisateur est étiqueté « 6 » par Netflix, il sera placé à proximité générale de l’endroit où se trouvent tous les autres 6 turquoise dans la représentation spatiale ci-dessus (près du bas).
De même, si un utilisateur est étiqueté « 4 » par Netflix, il sera placé dans le voisinage général où se trouvent tous les autres 4 magenta dans la représentation spatiale ci-dessus (près du haut).

Notez comment la région turquoise « 6 » (comédie romantique) chevauche quelque peu la région grise « 5 ». Cela pourrait être analogue à la façon dont les utilisateurs qui aiment les comédies romantiques pourraient également aimer les films de parodie ou de satire parce qu’ils impliquent tous deux le rire.
De même, puisque la région magenta « 4 » (thriller) est quelque peu proche de la région rose « 9 » – cette région rose « 9 » pourrait représenter ceux qui aiment les films d’action – mathématiquement plus proche de la région « 4 » (thriller) que de la région « 6 » (comédie romantique).
Cela a du sens ? Ainsi, lorsqu’elle est représentée dans l’espace, la distance entre deux profils d’utilisateurs représente la similitude / différence de leurs goûts. Bien sûr, cela peut devenir infiniment plus complexe lorsque quelqu’un qui aime les comédies romantiques aime aussi les thrillers – mais le but de cette analogie est de montrer l’idée générale des relations mathématiques / spatiales entre différentes catégories.
Les groupes d’intérêt qui sont liés les uns aux autres apparaîtraient plus proches les uns des autres et pourraient être de bons prédicteurs de ce qu’un utilisateur aimera, étant donné que l’utilisateur aime quelque chose d’autre à proximité.
C’est ainsi que Netflix, ou vraiment toute entreprise tirant parti des modèles ML, crée des relations entre des données apparemment non structurées et transforme ces données en chiffres. Ces chiffres en eux-mêmes n’ont pas beaucoup de sens, mais ensemble, en relation les uns avec les autres, ils commencent à avoir du sens.
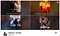
Pour le même film Good Will Hunting ci-dessous, un utilisateur identifié comme un fan de comédie se verrait montrer une vignette de Robin Williams (comédien), tandis qu’un autre utilisateur identifié comme un fan de comédie romantique se verrait montrer une vignette de baiser mettant en scène Matt Damon et Minnie Driver. Bien qu’il ne soit pas parfait, les algorithmes de Netflix suggèrent qu’un tel niveau de personnalisation basé sur les caractéristiques du profil de l’utilisateur augmente la probabilité des taux de clics.

Donc, résumons. Un tas de vignettes d’images Netflix est un tas de données non structurées.
Mais une fois que Netflix annote chaque vignette et lui attribue des métadonnées pour décrire ce qu’elle contient – nous avons maintenant une représentation numérique de ces données non structurées.
Placer cette représentation numérique sous forme de vecteurs sur une sphère 3D comme nous l’avons fait ci-dessus – et maintenant Netflix commence à former des relations entre les points de données.
Netflix trouve alors des points de données qui sont relativement proches les uns des autres et les utilise pour aider à prédire le comportement futur des clics. Si les prédictions s’avèrent mauvaises ou bonnes, ils ajustent le positionnement mathématique de ces caractéristiques en conséquence jusqu’à ce que le modèle devienne de mieux en mieux au fil du temps.
Voilà donc comment Netflix transforme des données non structurées en représentations mathématiques. Il utilise la distance relationnelle entre les points de données comme base pour faire et améliorer les recommandations de vignettes d’images.
Qu’a appris Netflix de toutes ces données ?
Maintenant que nous savons comment Netflix transforme les images en chiffres dans un modèle d’apprentissage automatique, quelles sont les connaissances que Netflix a trouvées à partir de tout le traitement des données et des tests A/B qu’ils ont effectués pendant tant d’années ?
Eh bien, outre l’apprentissage des millions de vignettes individuelles qui ont converti les utilisateurs en abonnés fidèles au fil du temps, voici quelques éléments supplémentaires que Netflix a appris pour ce qui fonctionne en termes de vignettes :
- Présenter des gros plans de visages émotionnellement expressifs
- Présenter des méchants plutôt que des héros
- Ne pas montrer plus de trois personnages
En conclusion : Netflix a déployé l’IA (principalement) de la bonne manière. Apprenons de leur approche.
Netflix a fait un travail phénoménal d’application de l’IA, de la science des données et de l’apprentissage automatique de la « bonne façon » – en utilisant une approche basée sur le produit qui se concentre sur le besoin commercial d’abord, puis sur la solution d’IA ensuite, plutôt que l’inverse.
Lorsqu’elle est appliquée correctement, l’IA peut faire des merveilles.
Nous avons vu à quel point les solutions d’IA peuvent être efficaces pour personnaliser l’expérience au profit à la fois de Netflix en termes d’abonnements et des utilisateurs en termes de satisfaction globale.
Nous avons également vu les limites des algorithmes qui « en font trop » et avons discuté d’exemples spécifiques dans lesquels l’algorithme de Netflix a présenté des vignettes trompeuses aux personnes de couleur parce que l’algorithme a optimisé les clics, « trompant » effectivement les utilisateurs pour qu’ils cliquent sur l’appât. Cela s’est produit même lorsque cette vignette ne représentait pas précisément cette vidéo.
Aucun algorithme ne sera parfait pour rendre compte de toutes les nuances d’une expérience humaine. En fait, les algorithmes conçus pour exploiter les métriques ne feront que cela – c’est donc le rôle du chef de produit de travailler avec la conception ou d’autres membres de l’équipe pour trouver des moyens de combler ces lacunes dans les algorithmes.
A l’avenir, l’intégration de l’IA dans la société ainsi que dans l’espace des entreprises continuera à devenir de plus en plus prévalente.
Les technologues peuvent avoir tendance à prescrire des solutions d’IA existantes, mais en réalité, la façon la plus efficace d’adopter l’IA est la façon dont Netflix l’a fait – d’abord d’un point de vue axé sur les affaires.
Diguez profondément et vous verrez que Netflix a généré des données de soutien avant de faire le pas stratégique en avant.
Alors que le monde de l’IA, de la science des données et de l’apprentissage automatique continue de croître, nous, les gestionnaires de produits, pouvons tous prendre une leçon ou deux du playbook de Netflix quand il s’agit de déployer correctement des solutions d’IA.
.