
Närvaron av artificiell intelligens i dagens samhälle blir alltmer allestädes närvarande – särskilt eftersom stora företag som Netflix, Amazon, Facebook, Spotify och många fler kontinuerligt använder AI-relaterade lösningar som direkt interagerar (ofta bakom kulisserna) med konsumenter varje dag.
När dessa AI-relaterade lösningar tillämpas på rätt sätt på affärsproblem kan de ge riktigt unika lösningar som skalas och förbättras med tiden, vilket skapar en betydande inverkan för både företag och användare. Men vad innebär det att ”tillämpa en AI-lösning på rätt sätt”? Betyder det att det finns ett fel sätt? Ur ett produktperspektiv är det korta svaret ja, och vi kommer att få veta varför det är så senare i den här artikeln när vi gräver djupare.
Översikt: Först kommer vi att beskriva 5 användningsområden för datavetenskap eller maskininlärning på Netflix. Vi kommer sedan att diskutera några affärsbehov kontra tekniska överväganden som en produktchef skulle titta på. Sedan kommer vi att dyka lite djupare in i det kanske mest intressanta av dessa 5 användningsfall när vi identifierar vilket affärsproblem det försöker lösa.
1. Låt oss bygga ett enkelt neuralt nät!
2. Beslutsträd i maskininlärning
3. En intuitiv introduktion till maskininlärning
4. Balansen mellan passiv och aktiv artificiell intelligens.
5 användningsområden för AI/data/maskininlärning hos Netflix
- Personalisering av filmrekommendationer – Användare som tittar på A kommer troligen att titta på B. Detta är kanske den mest välkända funktionen hos Netflix. Netflix använder tittarhistoriken hos andra användare med liknande smak för att rekommendera vad du kan vara mest intresserad av att titta på härnäst, så att du håller dig engagerad och fortsätter ditt månadsabonnemang för mer.
- Automatisk generering och personalisering av miniatyrbilder/konstverk – Med hjälp av tusentals videoframer från en befintlig film eller show som utgångspunkt för generering av miniatyrbilder, kommenterar Netflix dessa bilder och rangordnar sedan varje bild i ett försök att identifiera vilka miniatyrbilder som har störst sannolikhet att leda till att du klickar. Dessa beräkningar baseras på vad andra som liknar dig har klickat på. Ett resultat skulle kunna vara att användare som gillar vissa skådespelare/filmsgenrer är mer benägna att klicka på miniatyrbilder med vissa skådespelare/bildattribut.
- Platsspaning för filmproduktion (förproduktion) – Användning av data för att hjälpa till att bestämma var och när det är bäst att spela in en film – med tanke på begränsningar i fråga om schemaläggning (skådespelare/besättningens tillgänglighet), budget (plats, flyg-/hotellkostnader), och krav på produktionsscenerna (dag- eller nattinspelning, sannolikhet för risker för väderhändelser på en plats). Observera att detta snarare är ett datavetenskapligt optimeringsproblem än en maskininlärningsmodell som gör förutsägelser baserade på tidigare data.
- Filmredigering (postproduktion) -Användning av historiska data om när kvalitetskontroller har misslyckats tidigare (när synkroniseringen av undertexter med ljud/rörelser inte fungerade tidigare) – för att förutsäga när en manuell kontroll är mest fördelaktig i vad som annars skulle kunna vara en mycket tidskrävande och arbetskrävande process.
- Streamingkvalitet – Användning av tidigare visningsdata för att förutsäga bandbreddsanvändning för att hjälpa Netflix att bestämma när regionala servrar ska cachas för snabbare laddningstider under toppar (förväntad) efterfrågan.
Dessa 5 användningsfall/tillämpningar av datavetenskap eller maskininlärning bara i Netflix har haft en sådan skalbar inverkan att de för alltid har förändrat det tekniska landskapet och användarupplevelsen för miljontals och fler framöver. Antagandet av dessa AI-relaterade lösningar kommer bara att bli starkare med tiden.
Men innan dessa användningsfall var så vanliga som de är idag och används av användare som du och jag, var det någon eller någon grupp inom Netflix som på ett korrekt sätt kopplade ihop dessa AI-lösningar med ett affärsbehov. Utan denna affärsmässiga koppling skulle dessa användningsfall helt enkelt vara idéer som ligger längst ner i en backlog som så många andra bra idéer. Endast genom korrekt positionering och koppling till Netflix centrala affärsproblem blev dessa idéer den verklighet som de är i dag.

- Vad är affärsbehovet/problemet?
- Filmrekommendationer: Problemet är att Netflix har en enorm samling innehåll (över 100 miljoner olika produkter, enligt Netflix) som ständigt förändras och som kan vara överväldigande för en användare att konsumera. Användarna vill inte vara frustrerade när det gäller att hitta innehåll som är relevant för deras intressen. Så vad är då det bästa sättet att låta varje användare konsumera denna data på ett sätt som i slutändan maximerar prenumerationslojaliteten?
- Personaliserad miniatyrbild/konstverk: Identifiera problemet
- OK, miniatyrbilder är viktiga. Men vad exakt ska vi justera?
- Produktöverväganden för personliga miniatyrbilder
- Vilka data har vi?
- Hur Netflix använder data för att konstruera ett universum av användarprofilens intressen
- Reimagining Netflix Users in Mathematical Relation To Each Other
- Vad har Netflix lärt sig av alla dessa data?
- In Conclusion: Netflix använde AI (mestadels) på rätt sätt. Låt oss lära oss av deras tillvägagångssätt.
Vad är affärsbehovet/problemet?
Märk att i vart och ett av de användningsfall som jag har identifierat ovan är vart och ett förknippat med ett specifikt affärsbehov, mål eller hypotes.
Detta är absolut viktigt för alla produktchefer – för att undvika frestelsen hos teknikentusiasten som förundras över datavetenskapens / eller ML:s detaljer av intellektuella skäl utan att tydligt identifiera problemet eller affärsbehovet – och som potentiellt kan använda värdefulla tekniska resurser utan någon affärsmässig påverkan.
I slutändan av dagen måste produktcheferna på rätt sätt koppla ihop ett affärsproblem med en lösning för maskininlärning av data. Vi vill undvika att ha en lösning som jagar efter ett problem, annars kommer projektet att tappa fart inom företaget: ingenjörer kommer inte att vara tydliga med vad deras nordliga stjärna är, intressenter i hela organisationen kommer inte att köpa in och allokera de nödvändiga resurserna för att göra projektet till en framgång osv.
Säkerställ att det finns ett problem som en AI-lösning kan kopplas direkt till
Maskininlärning (ML) är en potentiell AI-lösning – men vi måste först definiera problemet innan vi föreskriver den lösningen.
Vilket affärsresultat försöker vi uppnå med ML? Eftersom detta centrala affärsbehov är det som styr parametrarna för de ML-modeller som används, vilka data som samlas in och bearbetas osv. Vi gör inte ML för att tillhandahålla personalisering bara för att det är intressant teknik – vi måste koppla det till ett affärsproblem. Datavetare är specialister på att avslöja insikter från data, men det är produktchefens roll att korrekt koppla det till ett affärsbehov eller problem och jämföra det med konkurrerande prioriteringar.
En teknikentusiast kan till exempel säga:
Vore det inte häftigt om du kunde analysera/diskutera ett avsnitt med hjälp av röst med Netflix – och Netflix, med datainmatning från tusentals andra användares reaktioner på det avsnittet, skulle kunna svara intelligent på dina kommentarer i en dubbelriktad dialog fram och tillbaka?
Ja, det skulle vara ett ganska häftigt användningsområde som utnyttjar naturlig språkbehandling (NLP) för att förstå din kommentar efter avsnittet i sitt sammanhang. Förutom NLP använder det här användningsfallet text-till-röst-personligheter samt sentimentanalys av hur tusentals andra tyckte om vad som hände i det avsnittet, eller vad de tycker om en viss karaktär. Detta är verkligen en vacker sammanslagning av flera banbrytande tekniker i ett enda användningsfall.
Om en pilot MVP-version av detta visar att användare som engagerar sig i hans nya funktion stannar längre eller återvänder oftare eller hjälper till att driva mer word-of-mouth om Netflix, så kan det motivera ytterligare resurser. Det första beslutet att bygga denna MVP skulle bero på ett strategiskt beslut som fattas av intressenterna och som inte nödvändigtvis prioriteras av mätvärdena. Det beror på företagets strategi.
Men hur vackert användarscenario ovanstående än är, vilket problem löser det?
Hur förhåller det sig till Netflix huvudproblem att hålla användarna abonnerade varje månad? Om det är relaterat, vilka bevis (kvalitativa eller kvantitativa) har vi för att stödja detta förhållande?
Och om detta är en legitim lösning på problemet, finns det då en enklare version av denna lösning som på samma sätt skulle kunna lösa problemet men som är mindre tekniskt komplicerad? Till exempel, i stället för röstinmatning och röstutmatning, hur skulle komplexiteten hos textinmatning och textutmatning kunna påverka ansträngningsnivån och inverkan på användarnas engagemang?
Hur skulle det vara om ett AI-gränssnitt utan röstdel (bara text) uppnådde 80 % av det avsedda användarengagemanget, men endast krävde 40 % av utvecklingsinsatsen? Skulle det vara värt att överväga en sådan alternativ väg?
Vilken affärseffekt skulle en sådan lösning ha i förhållande till ansträngningsnivån? Hur förhållandet är i förhållande till andra konkurrerande uppgifter i backloggen?
Detta är alla produktfokuserade frågor som en PM bör ställa för att anpassa de tekniska lösningarna till verksamhetens behov. För i slutändan är det affärsbehovet som styr parametrarna i en ML-modell, inte tvärtom.
Så låt oss återigen titta på filmrekommendationer och de personliga miniatyrbilderna – vad är problemet eller affärsmålet?

Filmrekommendationer: Problemet är att Netflix har en enorm samling innehåll (över 100 miljoner olika produkter, enligt Netflix) som ständigt förändras och som kan vara överväldigande för en användare att konsumera. Användarna vill inte vara frustrerade när det gäller att hitta innehåll som är relevant för deras intressen. Så vad är då det bästa sättet att låta varje användare konsumera denna data på ett sätt som i slutändan maximerar prenumerationslojaliteten?
Produktmålen omfattar:
- Öka/behålla tittarantalet i termer av antal konsumerade minuter,
- Öka antalet titlar som utforskas, frekvens av att logga in igen
- Överträffar vilket lägsta tröskelvärde som företaget bestämmer är ett framgångsmått
- Överlagd ökning av månadsabonnemangets lojalitet / minskning av antalet uppsägningar av abonnenter
Personaliserad miniatyrbild/konstverk: Identifiera problemet
Detta användningsfall är en delmängd av filmrekommendationer. Med tanke på att filmrekommendationer ges till användaren har vi nu ännu ett affärs- och användarproblem.
Problem: Hur (och när) presenterar vi bäst den filmrekommendationen för användaren på ett sätt som maximerar antalet tittare och månadsabonnenter?
Ett sätt att ge rekommendationen är genom en miniatyrbild – men vilken typ av miniatyrbild ska vi ge? Och hur säkra är vi på att en justering av en miniatyrbild kommer att påverka tittandet eller prenumerantlojaliteten på ett positivt sätt?
Och hur viktig är miniatyrbilden? Har vi data för det?
Samla in data för att stödja hypotesen
Du kan vara säker på att någon produktfokuserad person på Netflix – vid en tidpunkt före 2014 – ställde exakt samma frågor internt. Och den personen eller gruppen arbetade tillsammans (förmodligen med UX och relaterade intressenter) för att sammanställa användarstudier eller data någon annanstans för att bevisa att det verkligen fanns en stark koppling mellan en miniatyrbild och tittarsiffror.
Det var deras hypotes: att justeringen av det konstnärliga innehållet i en miniatyrbild kunde ha en stark koppling till tittarsiffrorna.
Det visade sig att Netflix redan 2014 genomförde studier som visade hur viktig miniatyrbilden är:
Nick Nelson, Netflix globala chef för kreativa tjänster, förklarade att företaget i början av 2014 genomförde en undersökning som visade att konstverk ”inte bara var den största faktorn” för en användares beslut om vad han eller hon ska titta på, utan att det också utgjorde mer än 82 procent av deras fokus när de surfade på Netflix.
”Vi såg också att användarna tillbringade i genomsnitt 1,8 sekunder med att fundera över varje titel de presenterades för när de surfade på Netflix”, skrev Nelson. ”Vi blev förvånade över hur stor inverkan en bild hade på att en medlem skulle hitta bra innehåll, och hur lite tid vi hade på oss att fånga deras intresse.”
En liten, övertygande miniatyrbild kan innebära skillnaden mellan att få dig att tillbringa hela helgen med att titta på Netflix senaste Originals-hit eller att förlora intresset och hoppa över till en konkurrerande tjänst som Hulu eller liknande OTT-streamingtjänster som ESPN/Disney/HBO Go.”
Så baserat på studier visade sig hypotesen ovan vara mycket sann.”
OK, miniatyrbilder är viktiga. Men vad exakt ska vi justera?
Och hur matas en ostrukturerad datamängd som ett gäng miniatyrbilder in i en digital/matematisk maskininlärningsmodell? Vi besvarar den andra frågan längre ner.
För det första, med tanke på hur viktig miniatyrbilden var för en användares beslut att titta på något, hur kan Netflix generera bättre miniatyrbilder för varje användare för att öka chansen att en användare tittar på en video?
Att använda filmens originalkonst som den enda miniatyrbild som används för varje enskild person kommer sannolikt inte att ge de högsta klickfrekvenserna. Företaget lämnar sannolikt klick (och tittarnas strömningstid) på bordet!
Vad händer om Netflix anpassade skapade en annan miniatyrbild för varje användare som är optimerad för att öka klickfrekvensen?
Vad finns det för saker i en miniatyrbild som ligger inom Netflix kontroll som de kan justera för att öka klickfrekvensen?

Vilken skådespelare/figur(er) bör finnas med på den miniatyrbilden, om någon? Hur många? Vilken automatiskt genererad ram eller affischvariant skulle vara mest lockande för en viss användare att klicka på? Vilken belysning fungerar bäst? Filter?
Vilka uppgifter har vi om andra användares tidigare klickbeteende som vi kan dra associationer från för att hjälpa till att informera om detta miniatyrbildsbeslut i stor skala?
- Öka klickfrekvensen (CTR) för filmrekommendationer – vilket innebär engagemang
- Hypotes att högre engagemang kommer att leda till högre abonnenttillfredsställelse och lojalitet
Det här är alltså ett riktigt intressant problem med miniatyrbilden, som kan ha en enorm inverkan på sannolikheten att någon klickar på en video och tittar.
Om målet är att maximera sannolikheten för att titta genom att justera miniatyrbilden – vilka produktbeslut bör man då ta hänsyn till?
Produktöverväganden för personliga miniatyrbilder
Vi kommer inte att gå in på varje användningsfall ovan, men låt oss gå in lite mer på det andra: Artwork / Thumbnail Personalization
Detta är en datadriven personaliseringsfunktion som sitter ovanpå Movie recommendation engine
Produktöverväganden
Algoritmer är bra, men de har begränsningar. En produktansvarig bör alltid tänka framåt på möjliga edge case-scenarier där algoritmen kan misslyckas med att producera de bästa resultaten.
- Varje film bör helst ha en personlig miniatyrbild som maximerar klick. Eftersom Netflix har data om klickbeteende hos andra personer med liknande intressen är det en rimlig hypotes att gissa att om andra personer med liknande intressen och tittarhistorik hade en hög klickfrekvens på en viss miniatyrbild, så är det troligt att denna bildminiatyrbild kommer att prestera kommer att prestera på en ny person som ännu inte rekommenderats den här filmen/miniatyrbilden.
- Den personaliserade miniatyrbilden bör ta hänsyn till andra filmer som det finns rekommenderade samtidigt – och vad dessa bildrekommendationer är. Låt oss säga att Netflix rekommenderar 2 olika Spiderman-filmer till en användare sida vid sida – och båda har Spiderman med ansiktet mot kameran utan mask. Den ena är Tobey Maguire och den andra är Andrew Garfield. Skulle det inte vara konstigt för användaren att se båda porträtten av Maguire och Garfield som Spiderman med masken av – sida vid sida? Något att ta hänsyn till om det någonsin skulle inträffa.
En miniatyrbild kan fungera bra isolerat, men det kanske inte är tillräckligt bra när en sida med ett dussintal miniatyrbilder visas. Om alla är optimerade för att se likadana ut, kan de som grupp verka mindre övertygande. Det är alltså viktigt att titta på varje miniatyrbild tillsammans med vad som i övrigt presenteras. - Data är bra, men se upp för algoritmer som gör sitt jobb för bra, vilket leder till oavsiktliga konsekvenser/felaktigt positiva resultat!
I statistiken kallar man detta för ett typ I-fel – att felaktigt (eller felaktigt) föreslå en miniatyrbild som inte borde föreslås.
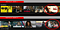
Ett exempel: Titta på exemplet nedan om Like Father, en film med Kristen Bell i huvudrollen. Ändå gjorde Netflix algoritm (tveklöst) falska miniatyrbildsrekommendationer av stödjande svarta skådespelare/skådespelerskor som egentligen inte representerar vad filmen handlade om, men som upplevde en högre klickfrekvens bland vissa etniska målgrupper.

Du bör alltså vara medveten om att en alltför optimerad/personaliserad upplevelse kan skapa en monoton användarupplevelse som i vissa fall kan vara missvisande för användaren. Vi vill tillhandahålla en hälsosam blandning av det välbekanta med det oväntade men också korrekt skildra innehållet för användaren så att de inte felaktigt vilseleds.
Här är ett annat exempel:
Baserat på hög sannolikhet för klickfrekvenser (CTR) slutade Netflix med att presentera miniatyrbilder för användarna som matchade en användares etnicitet – – – även när den (vanligtvis) birollsskådespelaren/skådespelerskan hade mycket lite speltid i den filmen.
Men även om detta är ett initiativ med stöd av data är det ganska uppenbart för användaren att det finns en känsla av ointresse som kan vara vilseledande när det gäller att en miniatyrbild representerar filmen på ett korrekt sätt (falskt positivt fel av typ I).
Självklart kommer den här algoritmen troligen att finjusteras med tiden, men läxan här är att man inte ska överdriva när man drar nytta av data – använd lite sunt förnuft för att balansera det hela.
Vi vill inte felaktigt vilseleda användarna eller låta dem veta att de behandlas annorlunda på grund av sin ras, till exempel.
4. Slutligen bör algoritmen ta hänsyn till vilka miniatyrbilder användaren tidigare sett i samband med den här filmen och sträva efter att ge en enhetlig, icke-förvirrande användarupplevelse.
Vi vill undvika att användaren får se olika miniatyrbilder varje gång den där filmen visas för användaren. Det skulle inte bara förvirra användaren, utan det skulle också göra det svårt för en produktchef att tilldela ett klick en tilldelning – vilken bild resulterade i en högre klickfrekvens (CTR) när den hela tiden ändras? PM:s måste kunna tilldela varje nytt resultat till en specifik förändring – så det är viktigt att upprätthålla en konsekvent datatilldelning.
Så detta är några saker som en produktchef kan tänka på när han eller hon utformar scenarier för edge case och vad extrema fall av dataanvändning kan leda till. På tal om data, vad arbetar Netflix specifikt utifrån?
Vilka data har vi?
Det finns två delar till detta:
- Vilka data använder Netflix för att skapa dessa personliga miniatyrbilder/konstverk?
- Vilka data använder Netflix för att rikta dessa skräddarsydda miniatyrbilder till rätt person?
För den första frågan kan man tänka sig att
- Ett 1 timmes avsnitt av Stranger Things har >86 000 statiska videoframes
- Dessa videoframes kan var och en individuellt tilldelas vissa attribut som senare används för att filtrera ner till de bästa miniatyrbilderna genom en uppsättning verktyg och algoritmer som kallas Aesthetic Visual Analysis (AVA). Detta är utformat för att hitta den bästa anpassade miniatyrbilden från varje statisk bild i videon
- Netflix Annotation – Netflix skapar metadata för varje bildruta, inklusive ljusstyrka (.67), antal ansikten (3), hudtoner (.2), sannolikhet för nakenhet (.03), grad av rörelseglädje (4), symmetri (.4)
- Netflix Image Ranking – Netflix använder metadata från ovan för att välja ut specifika bilder som är av högsta kvalitet (bra belysning, ingen rörelseoskärpa, innehåller troligen någon ansiktsbild av huvudkaraktärerna från en anständig vinkel, innehåller inte otillåtet varumärkesinnehåll etc.) och som är mest klickbara
För den andra frågan om vilka data Netflix använder för att identifiera vem man ska rikta de här specialgenererade miniatyrbilderna mot, tänk på att Netflix spårar:
- antal filmer som tittats på, antal minuter av varje program som tittats på
- % fullbordat för varje video/serie
- antal upvotes, vilka filmer som favoriserats, etc
- % av det totala tittinnehållet som kan hänföras till ett specifikt program (och därmed den grad av affinitet som användaren har till ett specifikt program eller relaterade skådespelare)
- någon säsongs- eller veckotrend som är relaterad till användarens nivå av engagemang, etc.
Interessant att notera är att Netflix i mitten av 2018 slutade att acceptera användarrecensioner som en datapunkt, vilket de tidigare endast hade begärt på sin webbplats. Varför? Därför att denna ”funktion” faktiskt minskar tittandet, eftersom negativa recensioner avskräcker användare från att prova en video. Detta är ännu ett exempel på hur ett affärsbehov ersätter ett populärt användarbehov!
Så Netflix har ett TON av data om var och en av sina kunder – från videor som tittats på till bilder som klickats. Vad gör de med alla dessa data?
Hur Netflix använder data för att konstruera ett universum av användarprofilens intressen
Ja, de använder dem för att sammanställa en 360-profil av varje användare och matematiskt indexera varje användare enligt hundratals, möjligen tusentals olika attribut.
Det gör de för att försöka gruppera människor med liknande intressen så att de kan använda data från en användare för att förutsäga andra liknande användares sannolika beteende.
Hur fungerar denna gruppering av liknande användarprofiler och hur gör en produktchef för att förstå uppgifterna?
Efter att ha gått igenom den komplexa matematiken och algoritmerna i samband med matriser, vektorer och n-dimensionell funktionsanalys fann jag att det enklaste sättet att förstå hur detta fungerar är genom en 3D-rumslig representation av 10+ dimensioner.
Här är en skärmdump som jag tog när jag använde Googles TensorBoard på mNIST-databasen med handskrivna siffror. Det är en finare plott som kallas t-SNE-plott – i praktiken en 3D-representation av många fler dimensioner än bara 3. I det här fallet visar vi 10 dimensioner (en för varje siffra från 1 till 10) på ett 3D-sfärliknande koordinatsystem.
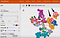
Varje handskriven siffras position i denna rumsliga representation kan beskrivas av en vektor – en koordinatliknande serie siffror över hur många funktionsdimensioner som helst.
På samma sätt, med Netflix-användare, skulle varje användarprofils position i diagrammet ovan kunna beskrivas av numeriska värden som var och en representerar en enskild dimension av användarens intresse – inklusive filmgenre, favoritskådespelare/skådespelerskor, filmämne, osv.
Reimagining Netflix Users in Mathematical Relation To Each Other
Låt oss låtsas i diagrammet med siffror ovan att:
- ”6” = romantisk komedi
- ”4” = thriller
Om en användare betecknas som en ”6” av Netflix kommer han/hon att placeras i den allmänna närheten av där alla andra turkosa 6:or befinner sig i ovanstående rumsliga representation (nära botten).
På samma sätt, om en användare märks som en ”4” av Netflix, kommer han/hon att placeras i den allmänna närheten av där alla andra magenta 4:or finns i ovanstående rumsliga representation (nära toppen).

Bemärk hur det turkosa ”6”-området (romantisk komedi) i viss mån överlappar det grå ”5”-området. Detta skulle kunna vara analogt med hur användare som gillar romantiska komedier också skulle kunna gilla parodi- eller satirfilmer eftersom båda involverar skratt.
Då den magenta ”4”-regionen (thriller) ligger något nära den rosa ”9”-regionen – denna rosa 9-region skulle kunna representera de som gillar actionfilmer – matematiskt sett närmare ”4”-regionen (thriller) än ”6”-regionen (romantisk komedi).
Genomförstår du det? När avståndet mellan två användarprofiler representeras rumsligt representerar avståndet alltså hur lika/olika deras smak är. Naturligtvis kan detta bli oändligt mycket mer komplext när någon som gillar romantiska komedier också gillar thrillers – men syftet med denna analogi är att visa den allmänna idén om matematiska / rumsliga relationer mellan olika kategorier.
Intressegrupper som är relaterade till varandra skulle synas närmare varandra och skulle kunna vara bra förutsägelser av vad en användare kommer att gilla, givet att användaren gillar något annat i närheten.
Detta är hur Netflix, eller egentligen alla företag som utnyttjar ML-modeller, skapar relationer mellan till synes ostrukturerade data och omvandlar dessa data till siffror. Dessa siffror i sig själva är inte särskilt meningsfulla, men tillsammans i förhållande till varandra börjar de bli meningsfulla.
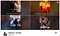
För samma Good Will Hunting-film nedan skulle en användare som identifierats som en komedifantast få se en miniatyrbild av Robin Williams (komiker), medan en annan användare som identifierats som en romantiskt komedifantast skulle få se en miniatyrbild av en kyss med Matt Damon och Minnie Driver. Även om det inte är perfekt, tyder Netflix algoritmer på att en sådan nivå av personalisering baserad på användarprofilens egenskaper ökar sannolikheten för klickfrekvens.

Så låt oss sammanfatta. Ett gäng miniatyrbilder från Netflix är ett gäng ostrukturerade data.
Men när Netflix väl kommenterar varje miniatyrbild och tilldelar metadata till varje miniatyrbild för att beskriva vad som finns i den miniatyrbilden – nu har vi en numerisk representation av dessa ostrukturerade data.
Plotta den numeriska representationen i form av vektorer över en 3D-sfär som vi gjorde ovan – och nu börjar Netflix skapa relationer mellan datapunkterna.
Netflix hittar sedan datapunkter som ligger relativt nära varandra och använder dem för att förutsäga framtida klickbeteenden. Om förutsägelserna visar sig vara dåliga eller bra justerar de den matematiska placeringen av dessa egenskaper i enlighet med detta tills modellen blir bättre och bättre med tiden.
Så det är så Netflix förvandlar ostrukturerade data till matematiska representationer. De använder det relationella avståndet mellan datapunkterna som grund för att göra och förbättra rekommendationer för miniatyrbilder.
Vad har Netflix lärt sig av alla dessa data?
När vi nu vet hur Netflix förvandlar bilder till siffror i en modell för maskininlärning, vad är det då för insikter som Netflix har kommit fram till från all databearbetning och alla A/B-tester som de har utfört i så många år?
Och, förutom att lära sig de miljontals enskilda miniatyrbilder som konverterade användare till lojala prenumeranter över tid, så finns här några ytterligare saker som Netflix har lärt sig om vad som fungerar när det gäller miniatyrbilder:
- Visa närbilder av känslomässigt uttrycksfulla ansikten
- Visa skurkar i stället för hjältar
- Visa inte fler än tre karaktärer
In Conclusion: Netflix använde AI (mestadels) på rätt sätt. Låt oss lära oss av deras tillvägagångssätt.
Netflix har gjort ett fenomenalt jobb med att tillämpa AI, datavetenskap och maskininlärning på ”rätt sätt” – genom att använda ett produktbaserat tillvägagångssätt som fokuserar på affärsbehovet först och sedan AI-lösningen därefter, snarare än tvärtom.
När AI tillämpas på rätt sätt kan den göra underverk.
Vi har sett hur effektiva AI-lösningar kan vara när det gäller att anpassa upplevelsen till förmån för både Netflix när det gäller prenumerationer och användarna när det gäller övergripande tillfredsställelse.
Vi har också sett begränsningar hos algoritmer som ”överdriver” och diskuterat specifika exempel där Netflix-algoritmen presenterade vilseledande miniatyrbilder för färgade personer eftersom algoritmen optimerade för klick, vilket i praktiken ”lurade” användarna till att klicka på beten. Detta hände även när miniatyrbilden inte representerade videon korrekt.
Ingen algoritm kommer att vara perfekt när det gäller att ta hänsyn till alla nyanser i en mänsklig upplevelse. Faktum är att algoritmer som är utformade för att utnyttja mätvärden kommer att göra just det – så det är produktchefens roll att samarbeta med konstruktörer eller andra teammedlemmar för att hitta sätt att åtgärda dessa brister i algoritmerna.
I framtiden kommer integrationen av AI i samhället såväl som i företagsverksamheten att fortsätta att bli alltmer utbredd.
Teknologer kan ha en tendens att föreskriva befintliga AI-lösningar, men det mest effektiva sättet att införa AI är egentligen det sätt som Netflix gjorde – först och främst ur ett affärsdrivet perspektiv.
Grav djupt och du kommer att se att Netflix genererade stödjande data innan de tog det strategiska steget framåt.
I takt med att världen av AI, datavetenskap och maskininlärning fortsätter att växa kan vi produktchefer alla ta en lektion eller två från Netflix playbook när det gäller att implementera AI-lösningar på rätt sätt.