De aanwezigheid van AI in de huidige samenleving wordt steeds algemener, vooral nu grote bedrijven als Netflix, Amazon, Facebook, Spotify en nog veel meer voortdurend AI-gerelateerde oplossingen inzetten die elke dag (vaak achter de schermen) direct in contact staan met consumenten.
Wanneer deze AI-gerelateerde oplossingen op de juiste manier worden toegepast op zakelijke problemen, kunnen ze werkelijk unieke oplossingen bieden die in de loop van de tijd worden geschaald en verbeterd, waardoor ze een aanzienlijke impact hebben voor zowel het bedrijf als de gebruiker. Maar wat betekent het om een AI-oplossing “goed toe te passen”? Betekent dit dat er een verkeerde manier is? Vanuit een productperspectief is het korte antwoord ja, en we zullen later in dit artikel dieper ingaan op waarom dat zo is.
Overzicht: Eerst zullen we 5 use cases van data science of machine learning bij Netflix schetsen. We zullen dan een aantal zakelijke behoeften versus technische overwegingen een Product Manager zou kijken naar bespreken. Dan zullen we een beetje dieper duiken in wat misschien wel de meest interessante van deze 5 use cases is als we identificeren welk bedrijfsprobleem het probeert op te lossen.
1. Laten we een eenvoudig neuraal net bouwen!
2. Beslissingsbomen in Machine Learning
3. Een intuïtieve inleiding tot Machine Learning
4. De balans tussen passieve vs. actieve A.I.
5 Use Cases van AI/Data/Machine Learning bij Netflix
- Personalisatie van filmaanbevelingen – Gebruikers die A kijken, zullen waarschijnlijk ook B kijken. Dit is misschien wel de bekendste functie van een Netflix. Netflix maakt gebruik van de kijkgeschiedenis van andere gebruikers met een vergelijkbare smaak om aan te bevelen wat u het meest geïnteresseerd bent in het volgende kijken, zodat u betrokken blijft en uw maandelijkse abonnement voortzet voor meer.
- Auto-Generation and Personalization of Thumbnails / Artwork – Met behulp van duizenden videoframes van een bestaande film of show als uitgangspunt voor het genereren van thumbnails, annoteert Netflix deze beelden en rangschikt vervolgens elk beeld in een poging om te identificeren welke thumbnails de hoogste waarschijnlijkheid hebben om in uw klik te resulteren. Deze berekeningen zijn gebaseerd op waar anderen die vergelijkbaar zijn met u op hebben geklikt. Een van de bevindingen zou kunnen zijn dat gebruikers die van bepaalde acteurs / filmgenres houden, meer kans hebben om op miniaturen met bepaalde acteurs / beeldkenmerken te klikken.
- Locatie scouting voor filmproductie (Pre-Productie) – Met behulp van gegevens om te helpen beslissen waar en wanneer een filmset het beste kan worden opgenomen – gezien de beperkingen van planning (beschikbaarheid van acteurs / crew), budget (locatie, vlucht / hotel kosten), en productie scène-eisen (dag- vs nachtopname, waarschijnlijkheid van weersomstandigheden risico’s in een locatie). Merk op dat dit meer een data science optimalisatie probleem is dan een machine learning model dat voorspellingen doet op basis van gegevens uit het verleden.
- Film Editing (Post-Production) -Gebruik maken van historische gegevens van wanneer kwaliteitscontroles in het verleden zijn mislukt (wanneer synchronisatie van ondertitels met geluid/bewegingen in het verleden niet goed waren) – om te voorspellen wanneer een handmatige controle het meest voordelig is in wat anders een zeer tijdrovend en moeizaam proces zou kunnen zijn.
- Streaming Quality – Met behulp van kijkgegevens uit het verleden om bandbreedtegebruik te voorspellen om Netflix te helpen beslissen wanneer regionale servers moeten worden gecached voor snellere laadtijden tijdens de (verwachte) piekvraag.
Deze 5 use cases / toepassingen van data science of machine learning alleen al in Netflix hebben zo’n schaalbare impact gehad dat ze het technologielandschap en de gebruikerservaring voor altijd hebben veranderd voor miljoenen en nog meer te komen. De adoptie van deze AI-gerelateerde oplossingen zal in de loop van de tijd alleen maar sterker worden.
Maar voordat deze use cases zo gewoon waren als ze vandaag zijn en worden gebruikt door gebruikers zoals u en ik, heeft iemand of een bepaalde groep binnen Netflix deze AI-oplossingen op de juiste manier verbonden met een zakelijke behoefte. Zonder deze zakelijke link, zouden deze use cases gewoon pie-in-the-sky ideeën zijn die onderaan een backlog zitten zoals zo veel andere geweldige ideeën. Alleen door de juiste positionering en verbinding met het zakelijke kernprobleem van Netflix werden deze ideeën de realiteit die ze vandaag zijn.

- Wat is de bedrijfsbehoefte/het bedrijfsprobleem?
- Filmaanbevelingen: Identifying the Problem
- Personalized Image Thumbnail / Artwork: Identifying the Problem
- OK, Thumbnails zijn belangrijk.
- Product Considerations In Personalized Image Thumbnails
- Welke gegevens hebben we?
- Hoe Netflix gegevens gebruikt om een universum van interesses voor gebruikersprofielen samen te stellen
- Reimagining Netflix Users in Mathematical Relation To Each Other
- Wat heeft Netflix geleerd van al deze gegevens?
- In Conclusion: Netflix heeft AI (meestal) op de juiste manier ingezet. Laten we leren van hun aanpak.
Wat is de bedrijfsbehoefte/het bedrijfsprobleem?
Merk op dat in elk van de use cases die ik hierboven heb geïdentificeerd, elk is gekoppeld aan een specifieke bedrijfsbehoefte, -doelstelling of -hypothese.
Dit is absoluut belangrijk voor elke productmanager – om de verleiding van de tech-liefhebber te vermijden die zich om intellectuele redenen verwondert over de details van de datawetenschap / of ML zonder het probleem of de bedrijfsbehoefte duidelijk te identificeren – mogelijk kostbare technische middelen gebruiken zonder zakelijke impact.
Aan het einde van de dag moeten productmanagers een bedrijfsprobleem goed verbinden met een oplossing voor data machine learning. We willen voorkomen dat we een oplossing hebben die een probleem najaagt, anders verliest het project momentum binnen het bedrijf: ingenieurs zullen niet duidelijk zijn wat hun noordster is, belanghebbenden in de hele organisatie zullen niet buy-in zijn en de nodige middelen toewijzen om het project tot een succes te maken, enz.
Zorg ervoor dat er een probleem is waaraan een AI-oplossing direct kan worden gekoppeld
Machine learning (ML) is een potentiële AI-oplossing – maar we moeten eerst het probleem definiëren voordat we die oplossing voorschrijven.
Wat is het bedrijfsresultaat dat we met ML proberen te bereiken? Want deze kernbehoefte van het bedrijf is wat de parameters van de gebruikte ML-modellen aanstuurt, welke gegevens worden verzameld en verwerkt, enz. We doen geen ML om personalisatie te bieden alleen omdat het interessante tech is – we moeten het koppelen aan een bedrijfsprobleem. Data scientists zijn specialisten in het blootleggen van inzichten uit de gegevens, maar het is de rol van de productmanager om het op de juiste manier te koppelen aan een zakelijke behoefte of probleem en het te vergelijken met concurrerende prioriteiten.
Een tech-liefhebber zou bijvoorbeeld kunnen zeggen:
Zou het niet cool zijn als je een aflevering met behulp van spraak zou kunnen analyseren / debatteren met Netflix – en Netflix, met gegevensinvoer van duizenden reacties van andere gebruikers op die aflevering, intelligent zou kunnen reageren op jouw opmerkingen in een heen-en-weer 2-weg dialoog?
Ja, dat zou een behoorlijk geweldige use-case zijn waarbij gebruik wordt gemaakt van NLP (Natural Language Processing) om uw commentaar na de aflevering in de context te begrijpen. Naast NLP wordt in deze use-case ook gebruikgemaakt van tekst-naar-spraakpersonages en sentimentanalyse van wat duizenden anderen vonden van wat er in die aflevering is gebeurd, of wat ze van een bepaald personage vinden. Inderdaad, dit is een prachtige samensmelting van meerdere geavanceerde technologieën in één use case.
Als een pilot MVP-versie hiervan zou laten zien dat gebruikers die zich bezighielden met zijn nieuwe functie langer bleven of vaker terugkwamen of hielpen meer mond-tot-mondreclame over Netflix te stimuleren, dan zou het verdere middelen kunnen rechtvaardigen. De initiële beslissing om die MVP te bouwen zou afhangen van een strategische beslissing van belanghebbenden, niet noodzakelijkerwijs geprioriteerd door metric. Dat zal afhangen van de bedrijfsstrategie.
Maar zo mooi van een gebruikersscenario het bovenstaande is, welk probleem lost dat op?
Hoe verhoudt het zich tot het hoofdprobleem van Netflix om gebruikers elke maand geabonneerd te houden? Als het verband houdt, welk bewijs (kwalitatief of kwantitatief) hebben we dan om die relatie te ondersteunen?
En als dit een legitieme oplossing voor dat probleem is, is er dan een eenvoudiger versie van deze oplossing die dat probleem net zo goed zou kunnen verwezenlijken maar technisch minder complex is? Bijvoorbeeld, in plaats van spraakinvoer en spraakuitvoer, hoe zou de complexiteit van alleen tekstinvoer en tekstuitvoer het inspanningsniveau en de impact op de betrokkenheid van de gebruiker kunnen beïnvloeden?
Wat als een conversationele AI-interface zonder het spraakgedeelte (alleen tekst) 80% van de beoogde betrokkenheid van de gebruiker zou bereiken, maar slechts 40% van de ontwikkelingsinspanning zou vereisen? Zou het de moeite waard zijn een dergelijke alternatieve route te overwegen?
Welke zakelijke impact zou een dergelijke oplossing hebben in vergelijking met het niveau van de inspanning? Hoe verhoudt deze verhouding zich tot die van andere concurrerende taken in de backlog?
Dit zijn allemaal productgerichte vragen die een PM zou moeten stellen om technologische oplossingen af te stemmen op de bedrijfsbehoeften. Want uiteindelijk is het de bedrijfsbehoefte die de parameters van een ML-model bepaalt, en niet andersom.
Dus laten we nog eens kijken naar filmaanbevelingen en die gepersonaliseerde miniaturen – wat is het probleem of het bedrijfsdoel?

Filmaanbevelingen: Identifying the Problem
Hier is het probleem dat Netflix een enorme verzameling content heeft (meer dan 100 miljoen verschillende producten, volgens Netflix) die voortdurend verandert en voor een gebruiker overweldigend kan zijn om te consumeren. Gebruikers willen niet gefrustreerd raken bij het vinden van inhoud die relevant is voor hun interesses. Dus wat is dan de beste manier om elke gebruiker in staat te stellen die gegevens te consumeren op een manier die uiteindelijk de loyaliteit van het abonnement maximaliseert?
Productdoelen omvatten:
- Vergroten / behouden van viewership in termen van # geconsumeerde minuten,
- Vergroten van # titels verkend, frequentie van opnieuw inloggen
- Overschrijden van de minimumdrempel die het bedrijf als succesfactor beschouwt
- Algehele toename van de maandelijkse abonnementsbinding / afname van het aantal opzeggingen
Personalized Image Thumbnail / Artwork: Identifying the Problem
Deze use-case is een subcategorie van filmaanbevelingen. Aangezien film aanbevelingen worden verstrekt aan de gebruiker, hebben we nu nog een ander bedrijf / gebruiker probleem.
Probleem: Hoe (en wanneer) we het beste presenteren die film aanbeveling aan de gebruiker op een manier die kijkers maximaliseert en maandelijkse abonnee loyaliteit?
Wel, een manier om die aanbeveling te bieden is door middel van een afbeelding thumbnail – maar wat voor thumbnail bieden wij? En hoe zeker zijn we dat het aanpassen van een thumbnail het kijkersaantal of de abonneetrouw positief zal beïnvloeden?
En hoe belangrijk is die thumbnail? Hebben we daar gegevens voor?
Gegevens verzamelen om die hypothese te ondersteunen
Wel, je kunt er zeker van zijn dat een of ander productgericht individu bij Netflix – op een moment vóór 2014 – intern precies dezelfde vragen stelde. En dat individu of die groep werkte samen (waarschijnlijk met UX en gerelateerde belanghebbenden) om gebruikersstudies of gegevens elders samen te stellen, om te bewijzen dat er inderdaad een sterk verband was tussen een afbeeldingsminiatuur en kijkersaantallen.
Dat was hun hypothese: dat het aanpassen van de artistieke inhoud van een afbeeldingsminiatuur een sterk verband kon hebben met kijkersaantallen.
Wel, blijkt, terug in 2014, Netflix voerde studies uit die aantonen hoe belangrijk die thumbnail is:
Nick Nelson, Netflix’s global manager of creative services, legde uit dat het bedrijf begin 2014 onderzoek uitvoerde waaruit bleek dat artwork “niet alleen de grootste beïnvloeder” was voor de beslissing van een gebruiker over wat te kijken, het vormde ook meer dan 82 procent van hun focus tijdens het browsen op Netflix.
“We zagen ook dat gebruikers gemiddeld 1,8 seconden besteedden aan het overwegen van elke titel die ze voorgeschoteld kregen terwijl ze op Netflix waren,” schreef Nelson. “We waren verrast door hoeveel impact een afbeelding had op een lid dat geweldige inhoud vond, en hoe weinig tijd we hadden om hun interesse te vangen.”
Een kleine, dwingende thumbnail kan het verschil betekenen tussen het krijgen van u om het hele weekend te kijken naar de nieuwste Originals-hit van Netflix of interesse te verliezen en over te stuiteren naar een concurrerende service zoals Hulu of soortgelijke OTT-streamingdiensten zoals ESPN / Disney / HBO Go.
Op basis van studies bleek de bovenstaande hypothese dus zeer waar te zijn.
OK, Thumbnails zijn belangrijk.
En hoe wordt een ongestructureerde dataset als een stel miniaturen van afbeeldingen ingevoerd in een digitaal/wiskundig model voor machinaal leren? We zullen deze tweede vraag hieronder verder beantwoorden.
Ten eerste, gezien hoe belangrijk de thumbnail was voor de beslissing van een gebruiker om iets te bekijken, hoe kan Netflix betere thumbnails genereren voor elke gebruiker om de kans te vergroten dat een gebruiker een video bekijkt?
Het gebruik van de originele art van de film als de enige thumbnail die voor elke afzonderlijke persoon wordt gebruikt, zal hoogstwaarschijnlijk niet de hoogste klikpercentages opleveren. Het bedrijf laat waarschijnlijk klikken (en streamtijd van de kijker) op de tafel liggen!
Wat als Netflix voor elke gebruiker een andere thumbnail op maat zou maken die is geoptimaliseerd om de klikfrequentie te verhogen?
Wat zijn dingen binnen een afbeeldings-thumbnail die binnen de controle van Netflix liggen en die ze kunnen aanpassen om de klikfrequentie te verhogen?

Welke acteur(s)/personage(s) moet(en) op die miniaturen staan, als die er zijn? Hoeveel? Welke automatisch gegenereerde frame- of postervariatie is voor een bepaalde gebruiker het meest verleidelijk om op te klikken? Welke belichting werkt het beste? Filters?
Welke gegevens hebben we over het klikgedrag van andere gebruikers in het verleden, waaruit we associaties kunnen putten om deze thumbnailbeslissing op schaal te helpen onderbouwen?
- Verhoog de click-thru-rates (CTR) van filmaanbevelingen – teken van betrokkenheid
- Hypothese dat hogere betrokkenheid leidt tot hogere tevredenheid en loyaliteit van abonnees
Dit is dus een echt interessant probleem met de beeldminiatuur dat een enorme impact kan hebben op de waarschijnlijkheid dat iemand op een video zal klikken en zal kijken.
Als het doel is om die waarschijnlijkheid van kijken te maximaliseren door de thumbnail te tweaken – wat zijn enkele productbeslissingen om te overwegen?
Product Considerations In Personalized Image Thumbnails
We zullen niet in elk van de bovenstaande use-cases duiken, maar laten we een beetje verder duiken in de tweede: Artwork / Thumbnail Personalization
Dit is een data-gedreven personalisatiefunctie die bovenop de Movie recommendation engine zit
Product Considerations
Algoritmen zijn geweldig, maar ze hebben wel beperkingen. Een productmanager moet altijd vooruit denken aan mogelijke edge case-scenario’s waarin het algoritme mogelijk niet de beste resultaten oplevert.
- Elke film zou idealiter een gepersonaliseerde thumbnail moeten hebben die het aantal klikken maximaliseert. Aangezien Netflix gegevens heeft over klikgedrag van andere mensen met vergelijkbare interesses, is het een redelijke hypothese om te raden dat als andere mensen met vergelijkbare interesses en kijkgeschiedenis een hoge click thru rate hadden op een bepaalde thumbnail, dan is het waarschijnlijk dat deze beeld thumbnail zal presteren op een nieuwe persoon die deze film / thumbnail nog niet is aanbevolen.
- De gepersonaliseerde thumbnail moet rekening houden met andere films die er op hetzelfde moment worden aanbevolen – en wat die beeldaanbevelingen zijn. Laten we zeggen dat Netflix 2 verschillende Spiderman films aanbeveelt aan een gebruiker naast elkaar – en ze hebben allebei Spiderman met het masker van de camera af. De ene is Tobey Maguire en de andere is Andrew Garfield. Zou het niet vreemd zijn voor de gebruiker om beide portretten van Maguire en Garfield als Spiderman met hun maskers af – naast elkaar te zien? Iets om rekening mee te houden als dat ooit zou gebeuren.
Een thumbnail van een afbeelding kan op zichzelf goed werken, maar dat is misschien niet goed genoeg als er een pagina met een dozijn thumbnails verschijnt. Als ze allemaal geoptimaliseerd zijn om er op dezelfde manier uit te zien, dan kunnen ze als groep minder aantrekkelijk lijken. Het is dus belangrijk om elke thumbnail te bekijken in combinatie met wat er nog meer wordt gepresenteerd. - Gegevens zijn geweldig, maar pas op voor algoritmen die hun werk te goed doen, wat leidt tot onbedoelde gevolgen / valse positieven!
In de statistiek noemen ze dit een Type I-fout – ten onrechte (of onjuist) een afbeeldingsminiatuur suggereren die niet zou moeten worden voorgesteld.
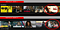
Case in point: Kijk maar naar het voorbeeld hieronder van Like Father, een film met Kristen Bell in de hoofdrol. Toch deed het algoritme van Netflix (aantoonbaar) valse aanbevelingen voor de thumbnail van ondersteunende zwarte acteurs/actrices die niet echt representatief waren voor waar de film over ging, maar wel een hogere klikfrequentie onder bepaalde etnische doelgroepen kregen.

Wees u er dus van bewust dat een te geoptimaliseerde / gepersonaliseerde ervaring kan leiden tot een eentonige gebruikerservaring die in sommige gevallen misleidend kan zijn voor de gebruiker. We willen een gezonde mix bieden van het bekende met het onverwachte, maar ook de inhoud nauwkeurig weergeven aan de gebruiker zodat deze niet ten onrechte wordt misleid.
Hier is nog een voorbeeld:
Gebaseerd op een hoge waarschijnlijkheid van click-thru-rates (CTR’s), Netflix eindigde met het presenteren van thumbnails aan gebruikers die overeenkwamen met de etniciteit van een gebruiker – – zelfs wanneer die (meestal) ondersteunende acteur/actrice zeer weinig screentime had in die film.
Hoewel dit een door gegevens ondersteund initiatief is, is het voor de gebruiker heel duidelijk dat er een gevoel van onoprechtheid bestaat dat misleidend kan zijn in de zin dat een thumbnail de film in kwestie correct weergeeft (type I fout-positieve fout).
Natuurlijk zal dit algoritme in de loop van de tijd waarschijnlijk worden verfijnd, maar de les hier is dat je niet moet overdrijven wanneer je gegevens gebruikt – gebruik wat gezond verstand om het in balans te brengen.
We willen gebruikers niet ten onrechte misleiden of hen laten weten dat ze anders worden behandeld vanwege hun ras, bijvoorbeeld.
4. Ten slotte moet het algoritme rekening houden met welke miniatuurafbeeldingen de gebruiker eerder heeft gezien in verband met deze film en streven naar een consistente, niet-verwarrende gebruikerservaring.
We willen voorkomen dat de gebruiker verschillende miniatuurafbeeldingen ziet telkens wanneer die film aan de gebruiker verschijnt. Niet alleen zou dit de gebruiker verwarren, maar het zou het ook moeilijk maken voor een Product Manager om attributie aan een klik toe te wijzen – welk beeld resulteerde in een hogere click-thru-rate (CTR) wanneer het steeds verandert? PM’s moeten in staat zijn om elk nieuw resultaat goed toe te schrijven aan een specifieke verandering – dus het handhaven van een consistente gegevenstoewijzing is belangrijk.
Dit zijn dus enkele dingen die een productmanager zou overwegen bij het ontwerpen van edge case-scenario’s en wat extreme gevallen van gegevensgebruik tot gevolg kunnen hebben. Over gegevens gesproken, waar werkt Netflix specifiek van af?
Welke gegevens hebben we?
Er zijn 2 delen:
- Welke gegevens gebruikt Netflix om deze gepersonaliseerde miniaturen / illustraties te maken?
- Welke gegevens gebruikt Netflix om deze op maat gemaakte miniaturen te richten op de juiste persoon?
Voor de eerste vraag, bedenk dat
- Een aflevering van 1 uur van Stranger Things heeft >86.000 statische videoframes
- Deze videoframes kunnen elk afzonderlijk bepaalde kenmerken krijgen die later worden gebruikt om te filteren tot de beste thumbnail-kandidaten via een set hulpmiddelen en algoritmen genaamd Aesthetic Visual Analysis (AVA). Dit is ontworpen om de beste aangepaste thumbnail-afbeelding te vinden uit elk statisch frame van de video
- Netflix Annotatie – Netflix creëert meta-gegevens voor elk frame, waaronder helderheid (.67), # van gezichten (3) , huidtinten (.2), waarschijnlijkheid van naaktheid (.03), niveau van bewegingsonscherpte (4), symmetrie (.4)
- Netflix Image Ranking – Netflix gebruikt de metagegevens van hierboven om specifieke afbeeldingen eruit te pikken die van de hoogste kwaliteit zijn (goede belichting, geen bewegingsonscherpte, bevat waarschijnlijk een gezichtsopname van belangrijke personages vanuit een fatsoenlijke hoek, bevat geen ongeoorloofde merkinhoud, enz.) en het meest klikbaar
Voor de tweede vraag welke gegevens Netflix gebruikt om te identificeren op wie deze op maat gemaakte miniaturen moeten worden gericht, bedenk dat Netflix bijhoudt:
- # bekeken films, # minuten van elke show bekeken
- % van voltooiing voor elke video/serie
- # upvotes, welke films werden gefavoriet, enz
- % van de totale kijkinhoud die is toe te schrijven aan een specifieke show (en dus niveau van affiniteit die gebruiker heeft met een specifieke show of gerelateerde castleden)
- alle seizoensgebonden of wekelijkse trends met betrekking tot het niveau van betrokkenheid van een gebruiker, enz.
Interessant om op te merken is dat Netflix medio 2018 is gestopt met het accepteren van gebruikersrecensies als een datapunt, dat het eerder alleen op hun website had gevraagd. Waarom? Omdat deze “functie” in feite het kijkerspubliek vermindert, omdat negatieve recensies gebruikers ontmoedigen om een video uit te proberen. Dit is het zoveelste voorbeeld van hoe een bedrijfsbehoefte een populaire gebruikersbehoefte verdringt!
Netflix heeft dus een TON aan gegevens over al zijn klanten – van bekeken video’s tot aangeklikte beelden. Wat doen ze met al die gegevens?
Hoe Netflix gegevens gebruikt om een universum van interesses voor gebruikersprofielen samen te stellen
Wel, ze gebruiken het om een 360-profiel van elke gebruiker samen te stellen en elke gebruiker wiskundig te indexeren op basis van honderden, mogelijk duizenden verschillende attributen.
Ze doen dit om te proberen mensen met vergelijkbare interesses te groeperen, zodat ze gegevens van één gebruiker kunnen gebruiken om waarschijnlijk gedrag van andere vergelijkbare gebruikers te helpen voorspellen.
Hoe werkt dit groeperen van vergelijkbare gebruikersprofielen en hoe maakt een productmanager zinvol gebruik van de gegevens?
Na het doornemen van de complexe wiskunde en algoritmen geassocieerd met matrices, vectoren, en n-dimensionale feature analyse, vond ik de gemakkelijkste manier om te begrijpen hoe dit werkt is door middel van een 3D-ruimtelijke weergave van 10 + dimensies.
Hier is een screenshot die ik nam bij het gebruik van Google’s TensorBoard op de mNIST-database van handgeschreven cijfers. Het is een fancy plot genaamd de t-SNE plot – effectief een 3D-weergave van een veel meer dimensies dan slechts 3. In dit geval tonen we 10 dimensies (een voor elk cijfer van 1 tot 10) op een 3D bol-achtig coördinatenstelsel.
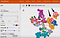
De positie van elk handgeschreven cijfer in deze ruimtelijke weergave kan worden beschreven door een vector – een coördinaatachtige reeks getallen over hoeveel kenmerkdimensies dan ook.
Ook bij Netflix-gebruikers kan de positie van elk gebruikersprofiel in de bovenstaande grafiek worden beschreven door numerieke waarden die elk een individuele dimensie van de interesse van die gebruiker vertegenwoordigen – inclusief filmgenre, favoriete acteurs/actrices, filmonderwerp, enzovoort.
Reimagining Netflix Users in Mathematical Relation To Each Other
Laten we in het bovenstaande cijferdiagram doen alsof:
- “6” = romantische komedie
- “4” = thriller
Als een gebruiker door Netflix wordt gelabeld als een “6”, dan wordt hij/zij geplaatst in de algemene nabijheid van waar alle andere turquoise 6’s zich in de bovenstaande ruimtelijke weergave bevinden (in de buurt van de bodem).
Ook als een gebruiker door Netflix als een “4” wordt bestempeld, wordt hij/zij in de algemene nabijheid geplaatst van waar alle andere magenta 4’s zich in de bovenstaande ruimtelijke voorstelling bevinden (dichtbij de bovenkant).

Merk op hoe de turquoise “6”-regio (romantische komedies) enigszins overlapt met de grijze “5”-regio. Dit zou analoog kunnen zijn aan de manier waarop gebruikers die van romantische komedies houden, ook van parodie- of satirefilms kunnen houden, omdat er in beide gevallen om gelachen moet worden.
Zo ook, omdat het magenta “4”-gebied (thriller) enigszins dicht bij het roze “9”-gebied ligt – dit roze “9”-gebied zou degenen kunnen vertegenwoordigen die van actiefilms houden – wiskundig gezien dichter bij het “4”-gebied van de thriller dan bij het “6”-gebied van de romantische komedie.
Blijkt dat logisch? Dus wanneer ruimtelijk weergegeven, de afstand tussen twee gebruikers profielen geeft aan hoe gelijk / verschillend hun smaak zijn. Natuurlijk kan dit oneindig veel complexer worden als iemand die van romantische komedies houdt ook van thrillers houdt – maar het doel van deze analogie is om het algemene idee van wiskundige / ruimtelijke relaties tussen verschillende categorieën te laten zien.
Interestgroepen die aan elkaar gerelateerd zijn, zouden dichter bij elkaar verschijnen en goede voorspellers kunnen zijn van wat een gebruiker leuk zal vinden, gegeven dat de gebruiker iets anders in de buurt leuk vindt.
Dit is hoe Netflix, of echt elk bedrijf dat ML-modellen gebruikt, relaties creëert tussen schijnbaar ongestructureerde gegevens en die gegevens omzet in getallen. Deze nummers op zichzelf hebben niet veel zin, maar samen in relatie tot elkaar, beginnen ze zin te krijgen.
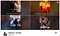
Voor dezelfde Good Will Hunting-film hieronder, zou een gebruiker die is geïdentificeerd als een komediefan een Robin Williams (komiek) thumbnail te zien krijgen, terwijl een andere gebruiker die is geïdentificeerd als een romantische komediefan een kussende thumbnail te zien zou krijgen met Matt Damon en Minnie Driver. Hoewel niet perfect, suggereren de algoritmes van Netflix dat een dergelijke mate van personalisering op basis van gebruikersprofielkenmerken de waarschijnlijkheid van doorklikpercentages verhoogt.

Dus laten we het even samenvatten. Een stel miniaturen van Netflix-afbeeldingen is een stel ongestructureerde gegevens.
Maar zodra Netflix elke miniatuur annoteert en metadata aan elke thumbnail toewijst om te beschrijven wat er in die thumbnail zit – nu hebben we een numerieke weergave van die ongestructureerde gegevens.
Plot die numerieke weergave in de vorm van vectoren over een 3D-bol zoals we hierboven deden – en nu begint Netflix relaties te vormen tussen datapunten.
Netflix vindt dan datapunten die relatief dicht bij elkaar liggen en gebruikt ze om toekomstig doorklikgedrag te helpen voorspellen. Als voorspellingen slecht of goed uitpakken, passen ze de wiskundige positionering van deze kenmerken dienovereenkomstig aan totdat het model in de loop van de tijd steeds beter wordt.
Dus zo zet Netflix ongestructureerde gegevens om in wiskundige representaties. Het gebruikt de relationele afstand tussen datapunten als basis voor het maken en verbeteren van aanbevelingen voor beeldminiaturen.
Wat heeft Netflix geleerd van al deze gegevens?
Nu we weten hoe Netflix afbeeldingen omzet in getallen in een machine learning-model, wat zijn enkele inzichten die Netflix heeft gevonden uit alle gegevensverwerking en A / B-tests die ze al zoveel jaren hebben uitgevoerd?
Wel, naast het leren van de miljoenen individuele thumbnails die gebruikers in de loop van de tijd hebben omgezet in loyale abonnees, zijn hier een paar extra dingen die Netflix heeft geleerd voor wat werkt in termen van thumbnails:
- Show close-ups van emotioneel expressieve gezichten
- Show people villains instead of heroes
- Don’t show more than three characters
In Conclusion: Netflix heeft AI (meestal) op de juiste manier ingezet. Laten we leren van hun aanpak.
Netflix heeft fenomenaal werk verricht door AI, data science en machine learning op de “juiste manier” toe te passen – met behulp van een productgebaseerde aanpak die zich eerst richt op de bedrijfsbehoefte en vervolgens op de AI-oplossing, in plaats van andersom.
Wanneer goed toegepast, kan AI wonderen doen.
We hebben gezien hoe effectief AI-oplossingen kunnen zijn bij het personaliseren van de ervaring ten gunste van zowel Netflix in termen van abonnementen als gebruikers in termen van algehele tevredenheid.
We hebben ook beperkingen gezien van algoritmen die “overdrijven” en specifieke voorbeelden besproken waarin het Netflix-algoritme misleidende miniaturen presenteerde aan mensen van kleur omdat het algoritme optimaliseerde voor klikken, waardoor de gebruikers effectief werden “getrickt” om op lokaas te klikken. Dit gebeurde zelfs wanneer die thumbnail die video niet nauwkeurig weergaf.
Geen algoritme zal perfect zijn in het rekening houden met alle nuances van een menselijke ervaring. In feite zullen algoritmen die zijn ontworpen om metriek te exploiteren, precies dat doen – het is dus de rol van de productmanager om met ontwerp- of andere teamleden samen te werken om manieren te vinden om deze tekortkomingen in algoritmen aan te pakken.
In de toekomst zal de integratie van AI in de samenleving en in de bedrijfsruimte steeds meer voorkomen.
Technologen hebben misschien de neiging om bestaande AI-oplossingen voor te schrijven, maar echt de meest effectieve manier om AI te adopteren is de manier waarop Netflix dat heeft gedaan – eerst vanuit een bedrijfsgedreven perspectief.
Diep diep en je zult zien dat Netflix ondersteunende gegevens genereerde voordat de strategische stap vooruit werd gezet.
Terwijl de wereld van AI, data science en machine learning blijft groeien, kunnen wij productmanagers allemaal een les of twee uit het Netflix-playbook nemen als het gaat om het op de juiste manier inzetten van AI-oplossingen.