Zastanówmy się, że projektujemy model uczenia maszynowego. Model mówi się, że jest dobrym modelem uczenia maszynowego, jeśli generalizuje nowe dane wejściowe z domeny problemu w odpowiedni sposób. To pomaga nam dokonać przewidywań w przyszłych danych, że model danych nigdy nie widział.
Teraz, załóżmy, że chcemy sprawdzić, jak dobrze nasz model uczenia maszynowego uczy się i generalizuje do nowych danych. W tym celu mamy przepasowanie i niedopasowanie, które są głównie odpowiedzialne za słabe wyniki algorytmów uczenia maszynowego.
Przed dalszym nurkowaniem zrozummy dwa ważne terminy:
Bias – Założenia przyjęte przez model, aby funkcja była łatwiejsza do nauczenia.
Dostosowanie:
Model statystyczny lub algorytm uczenia maszynowego ma niedostosowanie, gdy nie może uchwycić podstawowego trendu danych. (To tak jak próba dopasowania niewymiarowych spodni!) Underfitting niszczy dokładność naszego modelu uczenia maszynowego. Jego wystąpienie oznacza po prostu, że nasz model lub algorytm nie jest wystarczająco dobrze dopasowany do danych. Zdarza się to zazwyczaj, gdy mamy mniej danych do zbudowania dokładnego modelu, a także gdy próbujemy zbudować model liniowy z nieliniowymi danymi. W takich przypadkach reguły modelu uczenia maszynowego są zbyt łatwe i elastyczne do zastosowania na tak minimalnych danych i dlatego model będzie prawdopodobnie dokonywał wielu błędnych przewidywań. Underfitting może być uniknięty poprzez użycie większej ilości danych, a także redukcję cech poprzez selekcję cech.
W skrócie, Underfitting – High bias and low variance
Techniki redukcji underfitting :
1. Zwiększ złożoność modelu
2. Zwiększ liczbę cech, wykonując inżynierię cech
3. Usuń szum z danych.
4. Zwiększ liczbę epok lub wydłuż czas trwania treningu, aby uzyskać lepsze wyniki.
Overfitting:
Model statystyczny jest uważany za przepasowany, gdy trenujemy go z dużą ilością danych (tak jak dopasowujemy się do zbyt dużych spodni!). Kiedy model jest trenowany z tak dużą ilością danych, zaczyna uczyć się z szumu i niedokładnych wpisów danych w naszym zestawie danych. Wtedy model nie kategoryzuje danych poprawnie, z powodu zbyt wielu szczegółów i szumu. Przyczyną nadmiernego dopasowania są metody nieparametryczne i nieliniowe, ponieważ tego typu algorytmy uczenia maszynowego mają większą swobodę w budowaniu modelu na podstawie zbioru danych i dlatego mogą naprawdę budować nierealistyczne modele. Rozwiązaniem pozwalającym uniknąć overfitting’u jest użycie algorytmu liniowego, jeśli mamy liniowe dane lub użycie parametrów takich jak maksymalna głębokość, jeśli używamy drzew decyzyjnych.
W skrócie, Overfitting – High variance and low bias
Przykłady:
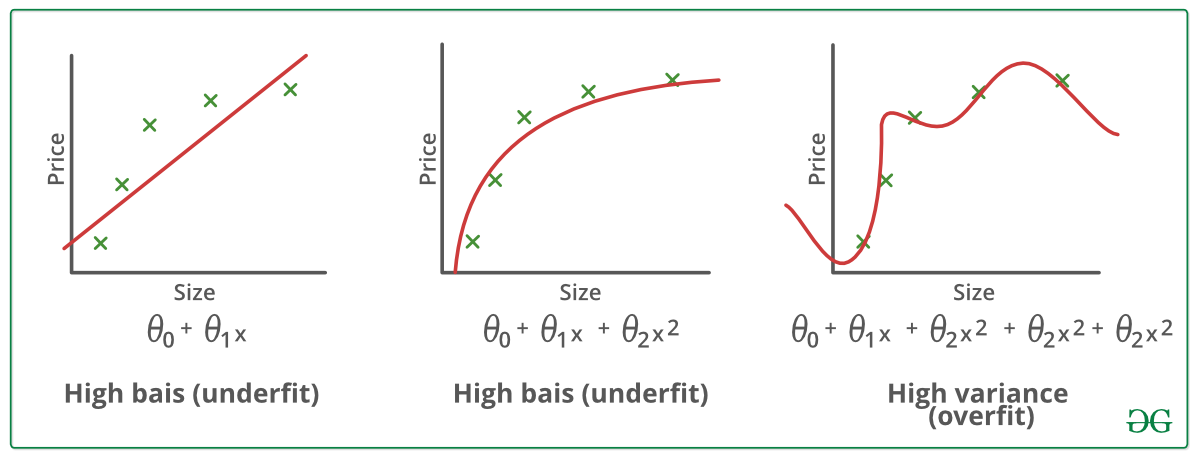

Techniki zmniejszania overfitting’u :
1. Zwiększ ilość danych treningowych.
2. Zmniejsz złożoność modelu.
3. Wczesne zatrzymanie w fazie treningu (miej oko na straty w okresie treningowym, jak tylko straty zaczną rosnąć zatrzymaj trening).
4. Ridge Regularization i Lasso Regularization
5. Użyj dropout dla sieci neuronowych, aby rozwiązać overfitting.
Dobre dopasowanie w modelu statystycznym:
Dobrze dopasowany jest przypadek, gdy model dokonuje przewidywań z błędem 0, mówi się, że ma dobre dopasowanie do danych. Ta sytuacja jest osiągalna w miejscu pomiędzy overfitting i underfitting. Aby to zrozumieć, będziemy musieli spojrzeć na wydajność naszego modelu z upływem czasu, podczas gdy uczy się on ze zbioru danych treningowych.
Z upływem czasu, nasz model będzie się uczył, a zatem błąd modelu na danych treningowych i testowych będzie malał. Jeśli model będzie się uczył zbyt długo, stanie się bardziej podatny na przepasowanie z powodu obecności szumu i mniej użytecznych szczegółów. W związku z tym wydajność naszego modelu będzie spadać. Aby uzyskać dobre dopasowanie, zatrzymamy się w punkcie tuż przed miejscem, w którym błąd zaczyna rosnąć. W tym momencie mówi się, że model ma dobre umiejętności na treningowych zbiorach danych, jak również na naszym niewidzialnym zbiorze danych testowych.