Deixe-nos considerar que estamos a desenhar um modelo de aprendizagem de máquinas. Diz-se que um modelo é um bom modelo de aprendizagem de máquina se ele generaliza quaisquer novos dados de entrada do domínio do problema de uma forma adequada. Isto nos ajuda a fazer previsões nos dados futuros, que o modelo de dados nunca viu.
Agora, suponhamos que queremos verificar quão bem o nosso modelo de aprendizagem de máquina aprende e generaliza para os novos dados. Para isso temos o sobreajuste e o subajuste, que são os principais responsáveis pelo mau desempenho dos algoritmos de aprendizagem da máquina.
Antes de mergulhar mais, vamos entender dois termos importantes:
Bias – Suposições feitas por um modelo para tornar uma função mais fácil de aprender.
Variância – Se você treinar seus dados de treinamento e obter um erro muito baixo, ao alterar os dados e depois treinar o mesmo modelo anterior você experimenta um erro alto, isto é variância.
Underfitting:
Diz-se que um modelo estatístico ou um algoritmo de aprendizagem de máquina tem underfitting quando ele não pode capturar a tendência subjacente dos dados. (É como tentar encaixar calças de tamanho inferior!) O underfitting destrói a precisão do nosso modelo de aprendizagem da máquina. Sua ocorrência significa simplesmente que nosso modelo ou o algoritmo não se encaixa suficientemente bem nos dados. Normalmente acontece quando temos menos dados para construir um modelo preciso e também quando tentamos construir um modelo linear com dados não lineares. Nesses casos as regras do modelo de aprendizagem da máquina são demasiado fáceis e flexíveis para serem aplicadas em dados tão mínimos e, portanto, o modelo provavelmente fará muitas previsões erradas. Underfitting pode ser evitado usando mais dados e também reduzindo as características por seleção de características.
Em resumo, Underfitting – Alta polarização e baixa variância
Técnicas para reduzir o underfitting :
1. Aumentar a complexidade do modelo
2. Aumentar o número de características, realizando engenharia de características
3. Remover ruído dos dados.
4. Aumentar o número de épocas ou aumentar a duração do treinamento para obter melhores resultados.
Overfitting:
Diz-se que um modelo estatístico é ajustado em excesso, quando o treinamos com muitos dados (assim como nos ajustamos em calças superdimensionadas!). Quando um modelo é treinado com tantos dados, ele começa a aprender com o ruído e entradas de dados imprecisas no nosso conjunto de dados. Então o modelo não categoriza os dados correctamente, por causa de demasiados detalhes e ruído. As causas do sobreajuste são os métodos não paramétricos e não lineares porque estes tipos de algoritmos de aprendizagem de máquinas têm mais liberdade na construção do modelo baseado no conjunto de dados e, portanto, podem realmente construir modelos não realistas. Uma solução para evitar overfitting é usar um algoritmo linear se tivermos dados lineares ou usar parâmetros como a profundidade máxima se estivermos usando árvores de decisão.
Em resumo, Overfitting – Alta variância e baixo viés
Exemplos:
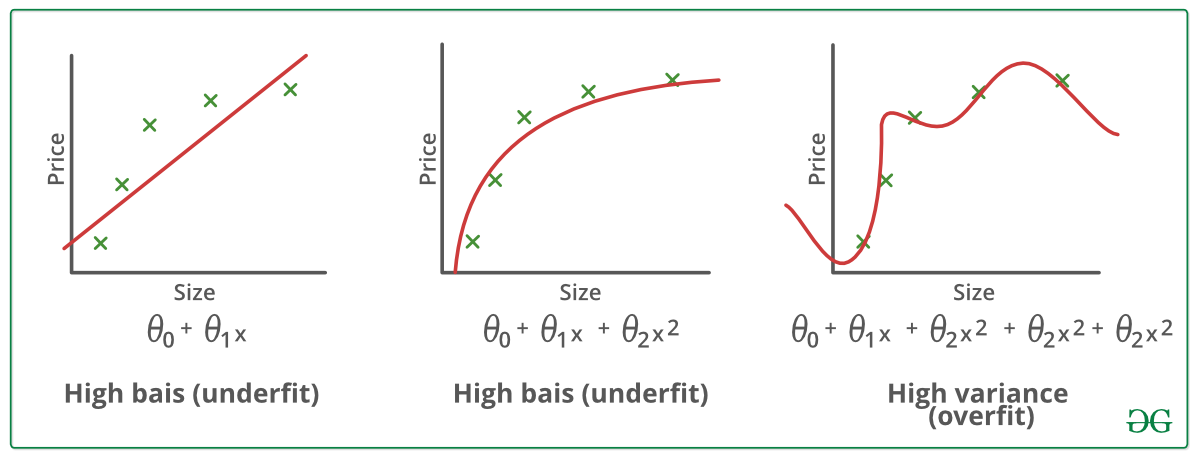

Técnicas para reduzir o overfitting :
1. Aumentar os dados de treinamento.
2. Reduzir a complexidade do modelo.
3. Parada precoce durante a fase de treinamento (ter um olho sobre a perda durante o período de treinamento assim que a perda começa a aumentar o treinamento de parada).
4. Regularização da crista e regularização da laçada
5. Use dropout para redes neurais para resolver o excesso de ajuste.
Bom Ajuste em um Modelo Estatístico:
Idealmente, o caso em que o modelo faz as previsões com erro 0, é dito ter um bom ajuste nos dados. Esta situação é atingível num ponto entre sobreajustamento e subajustamento. Para compreendê-la teremos que olhar para o desempenho do nosso modelo com a passagem do tempo, enquanto ele está aprendendo com o conjunto de dados de treinamento.
Com a passagem do tempo, nosso modelo continuará aprendendo e assim o erro do modelo nos dados de treinamento e teste continuará diminuindo. Se aprender por muito tempo, o modelo tornar-se-á mais propenso a sobreajustamento devido à presença de ruído e de detalhes menos úteis. Assim, o desempenho do nosso modelo irá diminuir. A fim de obter um bom ajuste, vamos parar em um ponto pouco antes de o erro começar a aumentar. Neste ponto diz-se que o modelo tem boas habilidades em conjuntos de dados de treinamento, assim como o nosso conjunto de dados de teste invisível.