Stellen we ons voor dat we een model voor machinaal leren ontwerpen. Men zegt dat een model een goed machine learning model is als het nieuwe invoergegevens uit het probleemdomein op de juiste manier generaliseert. Dit helpt ons om voorspellingen te doen in de toekomstige gegevens, die het datamodel nog nooit heeft gezien.
Nu, stel dat we willen controleren hoe goed ons machine learning model leert en generaliseert naar de nieuwe gegevens. Daarvoor hebben we overfitting en underfitting, die in belangrijke mate verantwoordelijk zijn voor de slechte prestaties van de machine learning algoritmen.
Voordat we verder duiken, laten we twee belangrijke termen begrijpen:
Bias – Aannames die door een model worden gemaakt om een functie gemakkelijker te leren te maken.
Variantie – Als u uw gegevens traint op trainingsgegevens en een zeer lage fout verkrijgt, wanneer u de gegevens wijzigt en vervolgens hetzelfde eerdere model traint, ondervindt u een hoge fout, dit is variantie.
Onderfitting:
Van een statistisch model of een machine-learningalgoritme wordt gezegd dat het een underfitting heeft wanneer het de onderliggende trend van de gegevens niet kan vastleggen. (Het is net alsof je een te kleine broek probeert te passen!) Underfitting vernietigt de nauwkeurigheid van ons model voor machinaal leren. Het betekent gewoon dat ons model of algoritme niet goed genoeg op de gegevens past. Het gebeurt meestal wanneer we minder gegevens hebben om een accuraat model te bouwen en ook wanneer we proberen een lineair model te bouwen met niet-lineaire gegevens. In dergelijke gevallen zijn de regels van het machine-leermodel te gemakkelijk en flexibel om op zulke minimale gegevens te worden toegepast en zal het model dus waarschijnlijk heel wat verkeerde voorspellingen doen. Underfitting kan worden vermeden door meer gegevens te gebruiken en ook de features te beperken door feature selectie.
In een notendop, Underfitting – Hoge bias en lage variantie
Technieken om underfitting te verminderen :
1. Verhoog de complexiteit van het model
2. Verhoog het aantal features, voer feature engineering uit
3. Verwijder ruis uit de gegevens.
4. Verhoog het aantal epochs of verhoog de duur van de training om betere resultaten te krijgen.
Overfitting:
Een statistisch model wordt overgefitted genoemd wanneer we het trainen met een heleboel gegevens (net alsof we onszelf een te grote broek aanmeten!). Wanneer een model met zoveel gegevens wordt getraind, begint het te leren van de ruis en de onnauwkeurige gegevens in onze gegevensverzameling. Dan categoriseert het model de gegevens niet correct, vanwege te veel details en ruis. De oorzaken van overfitting zijn de niet-parametrische en niet-lineaire methoden, omdat deze types van machine-learning algoritmen meer vrijheid hebben bij het bouwen van het model op basis van de dataset en daarom kunnen ze echt onrealistische modellen bouwen. Een oplossing om overfitting te voorkomen is het gebruik van een lineair algoritme als we lineaire gegevens hebben of het gebruik van de parameters zoals de maximale diepte als we beslisbomen gebruiken.
In een notendop, Overfitting – Hoge variantie en lage bias
Voorbeelden:
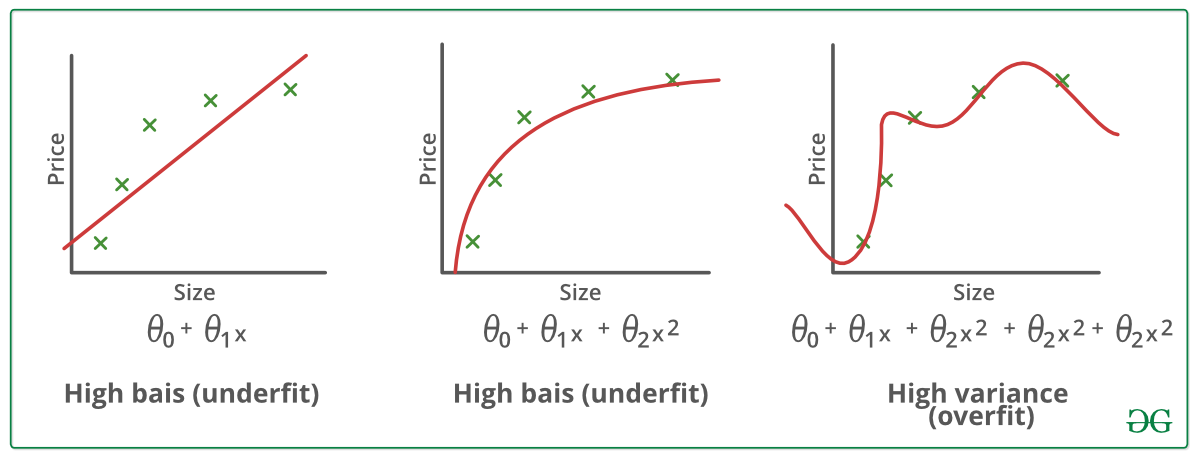

Technieken om overfitting te verminderen :
1. Vergroot het aantal trainingsgegevens.
2. Verminder de complexiteit van het model.
3. Stop vroegtijdig tijdens de trainingsfase (houd het verlies over de trainingsperiode in de gaten zodra het verlies begint toe te nemen, stop dan met trainen).
4. Ridge Regularization en Lasso Regularization
5. Gebruik dropout voor neurale netwerken om overfitting tegen te gaan.
Good Fit in een statistisch model:
In principe wordt het geval waarin het model voorspellingen doet met 0 fouten, een good fit op de gegevens genoemd. Deze situatie is te bereiken op een punt tussen overfitting en underfitting. Om dit te begrijpen, moeten we kijken naar de prestaties van ons model in de loop van de tijd, terwijl het leert van de trainingsdataset.
Naarmate de tijd verstrijkt, zal ons model blijven leren en dus zal de fout van het model op de training- en testdataset blijven afnemen. Als het te lang blijft leren, zal het model vatbaarder worden voor overfitting door de aanwezigheid van ruis en minder bruikbare details. Daardoor zal de prestatie van ons model afnemen. Om een goede fit te krijgen, zullen we stoppen op een punt net voor waar de fout begint toe te nemen. Op dit punt wordt gezegd dat het model goed kan werken op zowel de trainingsdatasets als onze ongeziene testdataset.