Consideriamo di progettare un modello di apprendimento automatico. Si dice che un modello è un buon modello di apprendimento automatico se generalizza qualsiasi nuovo dato di input dal dominio del problema in modo adeguato. Questo ci aiuta a fare previsioni nei dati futuri, che il modello di dati non ha mai visto.
Ora, supponiamo di voler controllare quanto bene il nostro modello di apprendimento automatico impara e generalizza ai nuovi dati. Per questo abbiamo overfitting e underfitting, che sono i principali responsabili delle scarse prestazioni degli algoritmi di apprendimento automatico.
Prima di immergerci ulteriormente cerchiamo di capire due termini importanti:
Bias – Assunzioni fatte da un modello per rendere una funzione più facile da imparare.
Varianza – Se addestri i tuoi dati su dati di allenamento e ottieni un errore molto basso, cambiando i dati e poi addestrando lo stesso modello precedente sperimenti un errore elevato, questa è la varianza.
Underfitting:
Si dice che un modello statistico o un algoritmo di apprendimento automatico ha un underfitting quando non può catturare la tendenza sottostante dei dati. (È proprio come cercare di adattare dei pantaloni sottodimensionati!) L’underfitting distrugge l’accuratezza del nostro modello di apprendimento automatico. Il suo verificarsi significa semplicemente che il nostro modello o l’algoritmo non si adatta abbastanza bene ai dati. Di solito accade quando abbiamo meno dati per costruire un modello accurato e anche quando cerchiamo di costruire un modello lineare con dati non lineari. In questi casi le regole del modello di apprendimento automatico sono troppo facili e flessibili per essere applicate su dati così minimi e quindi il modello probabilmente farà molte previsioni sbagliate. L’underfitting può essere evitato usando più dati e riducendo le caratteristiche attraverso la selezione delle caratteristiche.
In poche parole, Underfitting – Alto bias e bassa varianza
Tecniche per ridurre l’underfitting :
1. Aumentare la complessità del modello
2. Aumentare il numero di caratteristiche, eseguendo l’ingegneria delle caratteristiche
3. Rimuovere il rumore dai dati.
4. Aumentare il numero di epoche o aumentare la durata dell’addestramento per ottenere risultati migliori.
Overfitting:
Si dice che un modello statistico è overfitted, quando lo si addestra con un sacco di dati (proprio come adattarci in pantaloni troppo grandi!). Quando un modello viene addestrato con così tanti dati, inizia ad imparare dal rumore e dalle voci di dati imprecisi nel nostro set di dati. Allora il modello non categorizza i dati correttamente, a causa dei troppi dettagli e del rumore. Le cause dell’overfitting sono i metodi non parametrici e non lineari perché questi tipi di algoritmi di apprendimento automatico hanno più libertà nel costruire il modello basato sul set di dati e quindi possono davvero costruire modelli non realistici. Una soluzione per evitare l’overfitting è usare un algoritmo lineare se abbiamo dati lineari o usare i parametri come la profondità massima se stiamo usando alberi decisionali.
In breve, Overfitting – Alta varianza e basso bias
Esempi:
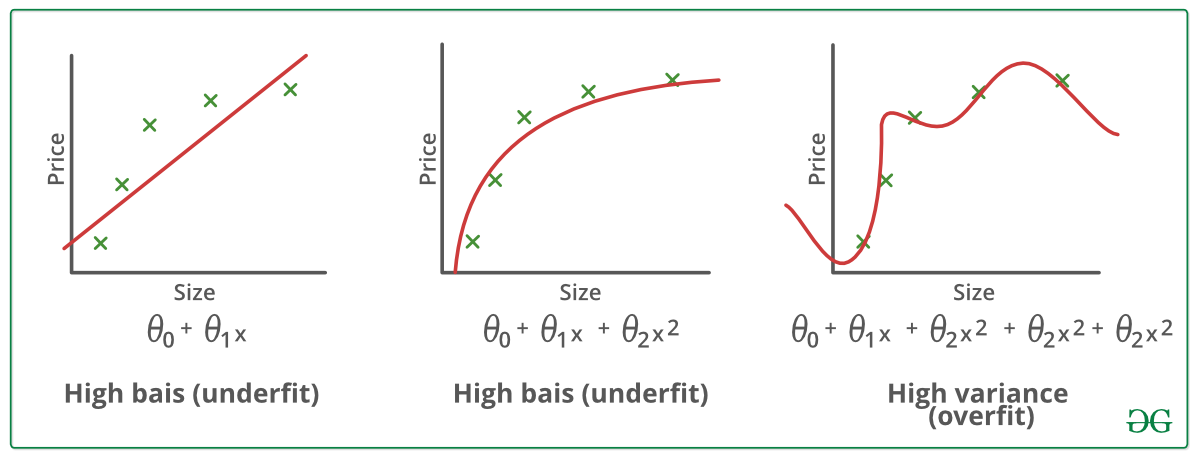

Tecniche per ridurre l’overfitting :
1. Aumentare i dati di formazione.
2. Ridurre la complessità del modello.
3. Arresto precoce durante la fase di formazione (avere un occhio sulla perdita durante il periodo di formazione, non appena la perdita inizia ad aumentare fermare la formazione).
4. Regolarizzazione Ridge e regolarizzazione Lasso
5. Utilizzare il dropout per le reti neurali per affrontare l’overfitting.
Buon adattamento in un modello statistico:
Idealmente, il caso in cui il modello fa le previsioni con 0 errori, si dice che ha un buon adattamento sui dati. Questa situazione è ottenibile in un punto tra l’overfitting e l’underfitting. Per capirlo dovremo guardare la performance del nostro modello con il passare del tempo, mentre sta imparando dal dataset di training.
Con il passare del tempo, il nostro modello continuerà ad imparare e quindi l’errore del modello sui dati di training e di test continuerà a diminuire. Se apprende troppo a lungo, il modello diventerà più incline all’overfitting a causa della presenza di rumore e di dettagli meno utili. Quindi la performance del nostro modello diminuirà. Al fine di ottenere un buon adattamento, ci fermeremo in un punto appena prima che l’errore inizi ad aumentare. A questo punto si dice che il modello ha buone capacità sui set di dati di addestramento e sul nostro set di dati di test non visto.