機械学習モデルを設計していると考えてみましょう。 モデルは、問題領域からの任意の新しい入力データを適切な方法で汎化する場合、良い機械学習モデルであると言われます。 これは、モデルが見たことのない将来のデータを予測するのに役立ちます。
さて、機械学習モデルがどの程度新しいデータを学習し汎化できるかを確認したいとします。 これにはオーバーフィットとアンダーフィットがあり、機械学習アルゴリズムの性能低下の主な原因となっています。
さらに深く掘り下げる前に、2 つの重要な用語を理解しましょう。
分散 – 訓練データでデータを訓練し、非常に低い誤差を得た場合、データを変更し、同じ以前のモデルを訓練すると、高い誤差が発生します。
アンダーフィット:
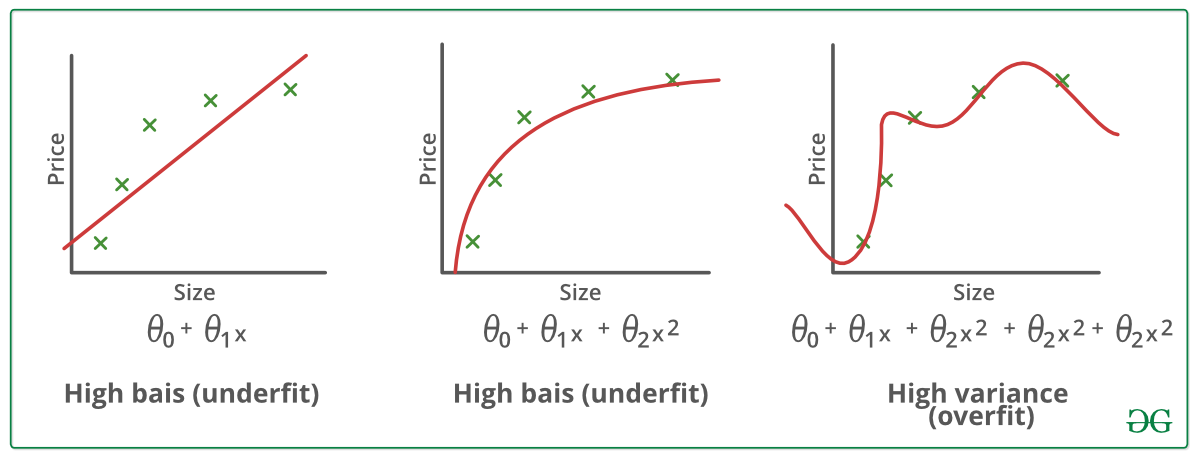
統計モデルまたは機械学習アルゴリズムは、データの基本傾向を捉えることができないと、アンダーフィットであると言われています。 (アンダーフィットは、機械学習モデルの精度を破壊します。 アンダーフィットの発生は、モデルやアルゴリズムがデータに十分にフィットしていないことを意味する。 通常、正確なモデルを構築するためのデータが少ない場合や、非線形なデータに対して線形モデルを構築しようとした場合に発生する。 このような場合、機械学習モデルのルールはこのような最小限のデータに適用するには簡単で柔軟すぎるため、モデルはおそらく多くの間違った予測をすることになる。 アンダーフィットは、より多くのデータを使用し、特徴選択により特徴を減らすことで回避できる。
一言で言えば、アンダーフィットとは、高いバイアスと低い分散のことである。 より良い結果を得るために、エポック数を増やしたり、学習時間を長くしたりする。 モデルが非常に多くのデータで学習されると、データ セット内のノイズや不正確なデータ エントリから学習するようになります。 そうすると、細部やノイズが多すぎるため、モデルはデータを正しく分類できなくなる。 オーバーフィッティングの原因は、ノンパラメトリック手法や非線形手法にある。これらの機械学習アルゴリズムは、データセットに基づくモデル構築の自由度が高いため、非現実的なモデルを構築してしまうことがあるからだ。 オーバーフィッティングを回避するための解決策は、線形データがある場合は線形アルゴリズムを使用し、決定木を使用している場合は最大深度のようなパラメーターを使用します。
一言で言うと、オーバーフィッティング – 高分散と低バイアス
例:

オーバーフィッティングを減らすテクニック:
1. 学習データを増やす
2.モデルの複雑さを減らす
3.学習段階での早期停止(学習期間中の損失に注目し、損失が増え始めたらすぐに学習を止める)
4.リッジ正規化、ラッソ正規化
5.学習期間中の損失を減らす(学習期間中の損失が増え始めたらすぐに学習を停止)
6.学習期間中の損失を減らす(学習期間中の損失を減らし始めたらすぐに学習を停止)
統計モデルにおける適合度:
理想的には、モデルが誤差0で予測する場合を、データに対する適合度が高いという。 この状況は、オーバーフィットとアンダーフィットの間のスポットで達成可能である。 それを理解するために、学習データセットから学習している間、時間の経過とともにモデルのパフォーマンスを見る必要があります。
時間の経過とともに、モデルは学習を続け、したがって、学習およびテスト データに対するモデルの誤差は減少し続けます。 もし学習時間が長すぎると、ノイズや有用でない詳細が存在するため、モデルはオーバーフィットになりやすくなる。 その結果、モデルの性能は低下する。 良いフィットを得るために、誤差が増加し始める直前のポイントで停止する。 この時点で、モデルは訓練データセットと未見のテストデータセットで良い能力を持つと言われています。