Uvažujme, že navrhujeme model strojového učení. O modelu se říká, že je dobrým modelem strojového učení, pokud správně zobecňuje jakákoli nová vstupní data z problémové oblasti. To nám pomáhá předpovídat budoucí data, která model nikdy neviděl.
Předpokládejme nyní, že chceme ověřit, jak dobře se náš model strojového učení učí a zobecňuje na nová data. K tomu nám slouží overfitting a underfitting, které jsou z velké části zodpovědné za špatné výkony algoritmů strojového učení.
Než se ponoříme dále, porozumíme dvěma důležitým pojmům:
Bias – Předpoklady, které model činí, aby se funkce snáze učila.
Variance – Pokud trénujete data na tréninkových datech a získáte velmi nízkou chybu, po změně dat a následném trénování stejného předchozího modelu dojde k vysoké chybě, jedná se o variance.
Nedostatečné přizpůsobení:
O statistickém modelu nebo algoritmu strojového učení se hovoří jako o nedostatečně přizpůsobeném, pokud nedokáže zachytit základní trend dat. (Je to stejné, jako když se snažíme přizpůsobit nedostatečně velké kalhoty!) Nedostatečné přizpůsobení ničí přesnost našeho modelu strojového učení. Jeho výskyt jednoduše znamená, že náš model nebo algoritmus nesedí na data dostatečně dobře. Obvykle k němu dochází, když máme k dispozici méně dat pro sestavení přesného modelu a také když se snažíme sestavit lineární model s nelineárními daty. V takových případech jsou pravidla modelu strojového učení příliš jednoduchá a pružná na to, aby se dala aplikovat na takové minimum dat, a proto model pravděpodobně provede mnoho chybných předpovědí. Nedostatečnému přizpůsobení se lze vyhnout použitím většího množství dat a také omezením rysů výběrem rysů.
Krátce řečeno, nedostatečné přizpůsobení se – vysoké zkreslení a nízký rozptyl
Techniky pro snížení nedostatečného přizpůsobení se :
1. Nedostatečné přizpůsobení se datům. Zvyšte složitost modelu
2. Zvyšte počet rysů, provádějte feature engineering
3. Odstraňte z dat šum.
4. Zvyšte počet epoch nebo prodlužte dobu trénování, abyste dosáhli lepších výsledků.
Overfitting:
O statistickém modelu se říká, že je overfitted, když ho trénujeme s velkým množstvím dat (stejně jako když se pasujeme do příliš velkých kalhot!). Když se model natrénuje s takovým množstvím dat, začne se učit ze šumu a nepřesných datových položek v našem souboru dat. Model pak kvůli příliš velkému množství detailů a šumu nekategorizuje data správně. Příčinou overfittingu jsou neparametrické a nelineární metody, protože tyto typy algoritmů strojového učení mají větší volnost při sestavování modelu na základě souboru dat, a proto mohou sestavovat opravdu nereálné modely. Řešením, jak se vyhnout overfittingu, je použití lineárního algoritmu, pokud máme lineární data, nebo použití parametrů, jako je maximální hloubka, pokud používáme rozhodovací stromy.
V kostce: Overfitting – vysoký rozptyl a nízké zkreslení
Příklady:
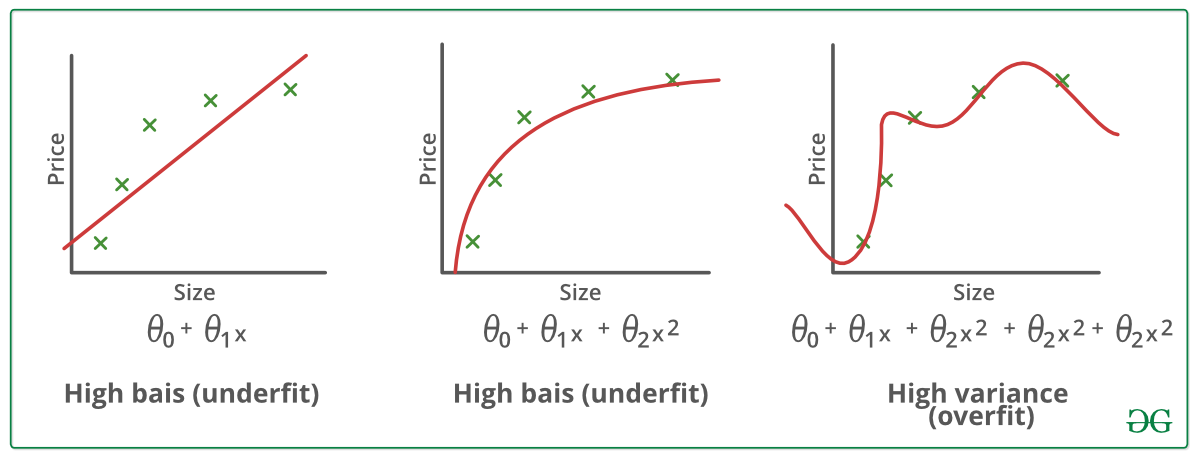

Techniky pro snížení overfittingu :
1. Příklady:
Techniky pro snížení overfittingu. Zvyšte počet trénovacích dat.
2. Snižte složitost modelu.
3. Včasné zastavení během fáze trénování (mějte přehled o ztrátě za dobu trénování, jakmile se ztráta začne zvyšovat, zastavte trénování).
4. Regularizace Ridge a regularizace Lasso
5. Včasné zastavení trénování. Použití dropoutu pro neuronové sítě k řešení problému overfittingu.
Dobrá shoda u statistického modelu:
V podstatě se říká, že případ, kdy model provádí předpovědi s chybou 0, má dobrou shodu s daty. Tato situace je dosažitelná na místě mezi overfittingem a underfittingem. Abychom ji pochopili, budeme se muset podívat na výkonnost našeho modelu s postupem času, zatímco se učí z trénovací sady dat.
S postupem času se náš model bude stále učit, a tak se bude chyba modelu na trénovacích a testovacích datech stále snižovat. Pokud se bude model učit příliš dlouho, bude náchylnější k nadměrnému přizpůsobení v důsledku přítomnosti šumu a méně užitečných detailů. Proto bude výkonnost našeho modelu klesat. Abychom dosáhli dobrého přizpůsobení, zastavíme se v bodě těsně před tím, kde se chyba začne zvyšovat. V tomto bodě se říká, že model má dobré schopnosti na trénovacích souborech dat i na našem neviděném testovacím souboru dat.
.