Asettakaamme, että suunnittelemme koneoppimismallia. Mallia sanotaan hyväksi koneoppimismalliksi, jos se yleistää minkä tahansa uuden syötetiedon ongelma-alueelta oikealla tavalla. Tämä auttaa meitä tekemään ennusteita tulevasta datasta, jota malli ei ole koskaan nähnyt.
Asettakaamme nyt, että haluamme tarkistaa, kuinka hyvin koneoppimismallimme oppii ja yleistää uuteen dataan. Sitä varten meillä on overfitting ja underfitting, jotka ovat suurimmaksi osaksi vastuussa koneoppimisalgoritmien huonosta suorituskyvystä.
Valmistetaan ennen syvemmälle sukeltamista kaksi tärkeää termiä:
Bias – Mallin tekemät oletukset, joiden avulla funktio on helpompi oppia.
Varianssi – Jos harjoittelet dataa harjoitteluaineistolla ja saat hyvin alhaisen virheen, dataa muutettaessa ja sen jälkeen harjoittelemalla samaa aiempaa mallia saat korkean virheen, kyseessä on varianssi.
Alisovittaminen:
Tilastollisella mallilla tai koneoppimisalgoritmilla sanotaan olevan alisovittamista, kun se ei kykene vangitsemaan datan perimmäistä trendiä. (Se on aivan kuin yrittäisi sovittaa alamittaisia housuja!) Alisovittaminen tuhoaa koneoppimismallimme tarkkuuden. Sen esiintyminen tarkoittaa yksinkertaisesti sitä, että mallimme tai algoritmimme ei sovi dataan riittävän hyvin. Sitä tapahtuu yleensä silloin, kun meillä on vähemmän dataa tarkan mallin rakentamiseen ja myös silloin, kun yritämme rakentaa lineaarisen mallin epälineaariselle datalle. Tällaisissa tapauksissa koneoppimismallin säännöt ovat liian helppoja ja joustavia sovellettaviksi tällaiseen minimaaliseen dataan, ja siksi malli tekee todennäköisesti paljon vääriä ennusteita. Alisovittamista voidaan välttää käyttämällä enemmän dataa ja myös vähentämällä piirteitä piirteiden valinnalla.
Lyhyesti sanottuna, alisovittaminen – Korkea harha ja pieni varianssi
Tekniikoita alisovittamisen vähentämiseksi :
1. Lisää mallin monimutkaisuutta
2. Lisää piirteiden määrää, suorittamalla piirteiden suunnittelua
3. Poista datasta kohinaa.
4. Lisää epookkien määrää tai lisää harjoittelun kestoa parempien tulosten saamiseksi.
Ylisovittaminen:
Tilastollisen mallin sanotaan olevan ylisovittunut, kun harjoittelemme sitä suurella määrällä dataa (aivan kuin sovittaisimme itsellemme ylisuuret housut!). Kun mallia koulutetaan niin suurella määrällä dataa, se alkaa oppia kohinasta ja epätarkoista tietomerkinnöistä datajoukossamme. Silloin malli ei luokittele dataa oikein, koska siinä on liikaa yksityiskohtia ja kohinaa. Ylisovittamisen syitä ovat ei-parametriset ja epälineaariset menetelmät, koska tämäntyyppisillä koneoppimisalgoritmeilla on enemmän vapautta mallin rakentamisessa datasetin perusteella, ja siksi ne voivat todella rakentaa epärealistisia malleja. Ratkaisu ylisovittamisen välttämiseksi on lineaarisen algoritmin käyttäminen, jos meillä on lineaarinen data, tai parametrien, kuten maksimaalisen syvyyden, käyttäminen, jos käytämme päätöspuita.
Ylisovittaminen pähkinänkuoressa – Korkea varianssi ja matala harha
Esimerkkejä:
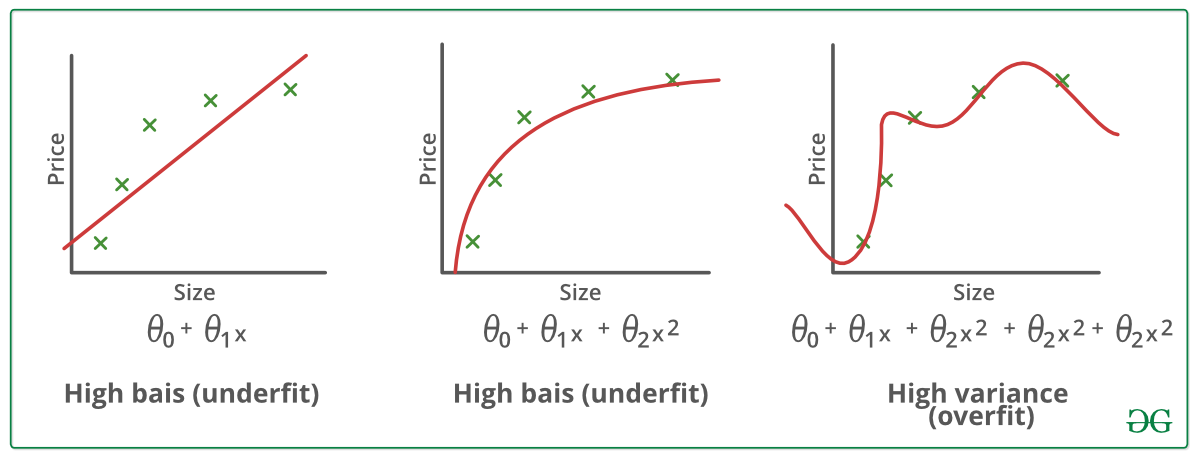

Tekniikoita ylisovittamisen pienentämiselle :
1. Lisää harjoitusdataa.
2. Vähennä mallin monimutkaisuutta.
3. Varhainen lopettaminen harjoitteluvaiheen aikana (pidä silmällä häviötä harjoittelujakson aikana heti kun häviö alkaa kasvaa lopeta harjoittelu).
4. Ridge-regularisointi ja Lasso-regularisointi
5. Ridge Regularization ja Lasso Regularization. Käytä pudotusta neuroverkoissa ylisovittamisen torjumiseksi.
Hyvä sovitus tilastollisessa mallissa:
Todennäköisesti tapauksessa, jossa malli tekee ennusteet 0 virheellä, puhutaan hyvästä sovituksesta dataan. Tämä tilanne on saavutettavissa overfittingin ja underfittingin välimaastossa. Ymmärtääksemme sen meidän on tarkasteltava mallimme suorituskykyä ajan kuluessa, kun se oppii harjoitusaineistosta.
Ajan kuluessa mallimme jatkaa oppimista ja siten mallin virheet harjoitus- ja testausdatassa pienenevät jatkuvasti. Jos se oppii liian kauan, malli on alttiimpi ylisovittamiselle kohinan ja vähemmän hyödyllisten yksityiskohtien vuoksi. Näin ollen mallin suorituskyky heikkenee. Jotta saamme hyvän sovituksen, pysähdymme pisteeseen juuri ennen kuin virhe alkaa kasvaa. Tässä pisteessä mallilla sanotaan olevan hyvät taidot harjoitustietoaineistoissa sekä näkymättömässä testitietoaineistossamme.