Vi kan tänka oss att vi utformar en modell för maskininlärning. En modell sägs vara en bra maskininlärningsmodell om den generaliserar alla nya indata från problemområdet på ett korrekt sätt. Detta hjälper oss att göra förutsägelser i framtida data, som datamodellen aldrig har sett.
Antag att vi nu vill kontrollera hur väl vår maskininlärningsmodell lär sig och generaliserar till nya data. För det har vi överanpassning och underanpassning, som är huvudansvariga för maskininlärningsalgoritmernas dåliga prestanda.
För att dyka vidare ska vi förstå två viktiga termer:
Bias – Antaganden som görs av en modell för att göra en funktion lättare att lära in.
Varians – Om du tränar dina data på träningsdata och får ett mycket lågt fel, men när du ändrar data och sedan tränar samma tidigare modell får du ett högt fel, detta är varians.
Underanpassning:
En statistisk modell eller en maskininlärningsalgoritm sägs ha en underanpassning när den inte kan fånga den underliggande trenden i data. (Det är precis som att försöka passa underdimensionerade byxor!) Underanpassning förstör noggrannheten hos vår maskininlärningsmodell. Dess förekomst innebär helt enkelt att vår modell eller algoritm inte passar data tillräckligt bra. Det inträffar vanligtvis när vi har färre data för att bygga en korrekt modell och även när vi försöker bygga en linjär modell med icke-linjära data. I sådana fall är reglerna i modellen för maskininlärning för enkla och flexibla för att kunna tillämpas på sådana minimala data, och därför kommer modellen förmodligen att göra många felaktiga förutsägelser. Underfitting kan undvikas genom att använda mer data och även genom att minska funktionerna genom funktionsval.
In a nutshell, Underfitting – hög bias och låg varians
Tekniker för att minska underfitting :
1. Öka modellens komplexitet
2. Öka antalet funktioner, genom att utföra feature engineering
3. Ta bort brus från data.
4. Öka antalet epoker eller öka träningstiden för att få bättre resultat.
Overfitting:
En statistisk modell sägs vara överanpassad när vi tränar den med mycket data (precis som att passa in oss själva i överdimensionerade byxor!). När en modell tränas med så mycket data börjar den lära sig av bruset och felaktiga dataposter i vår datamängd. Då kategoriserar modellen inte data korrekt, på grund av för många detaljer och brus. Orsakerna till överanpassning är de icke-parametriska och icke-linjära metoderna eftersom dessa typer av algoritmer för maskininlärning har större frihet när det gäller att bygga modellen utifrån datamängden och därför kan de verkligen bygga orealistiska modeller. En lösning för att undvika överanpassning är att använda en linjär algoritm om vi har linjära data eller att använda parametrar som maximalt djup om vi använder beslutsträd.
In a nutshell, Overfitting – Hög varians och låg bias
Exempel:
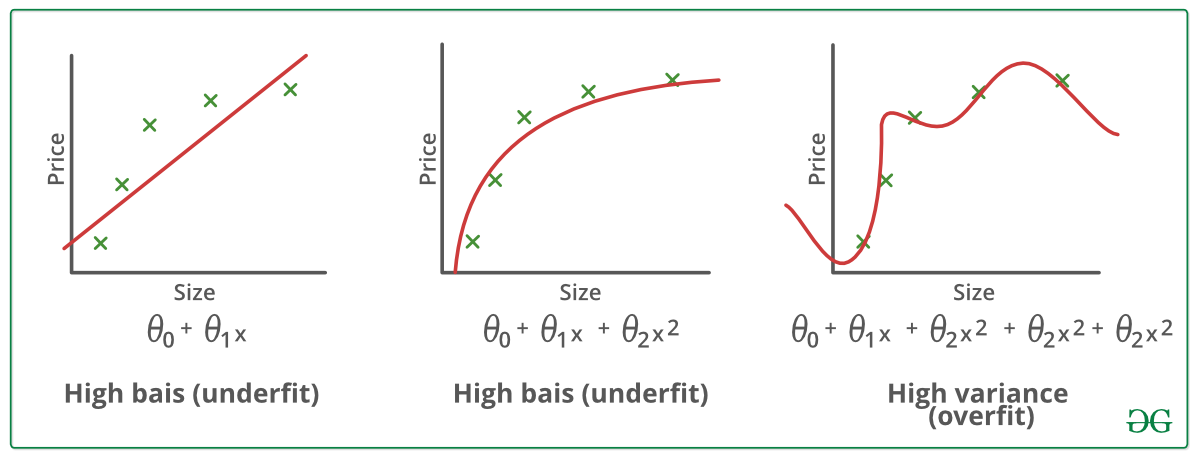

Tekniker för att minska överanpassning :
1. Öka antalet träningsdata
2. Minska modellens komplexitet
3. Tidigt stopp under träningsfasen (ha ett öga på förlusten under träningsperioden så snart förlusten börjar öka stoppa träningen)
4. Ridge Regularization och Lasso Regularization
5. Använd dropout för neurala nätverk för att hantera överanpassning.
God anpassning i en statistisk modell:
I själva verket sägs det fall då modellen gör förutsägelserna med 0 fel att den har en god anpassning på data. Denna situation kan uppnås på en punkt mellan överanpassning och underanpassning. För att förstå det måste vi titta på hur vår modell presterar med tiden, medan den lär sig från träningsdata.
Med tiden kommer vår modell att fortsätta att lära sig och därmed kommer felet för modellen på tränings- och testdata att fortsätta att minska. Om den lär sig för länge kommer modellen att bli mer benägen att överanpassas på grund av förekomsten av brus och mindre användbara detaljer. Därför kommer modellens prestanda att minska. För att få en bra anpassning kommer vi att sluta vid en punkt strax före den punkt där felet börjar öka. Vid denna punkt sägs modellen ha goda färdigheter på träningsdatamängder samt vår osynliga testdatamängd.