Să considerăm că proiectăm un model de învățare automată. Se spune că un model este un model bun de învățare automată dacă generalizează orice date noi de intrare din domeniul problemei într-un mod corespunzător. Acest lucru ne ajută să facem predicții în datele viitoare, pe care modelul de date nu le-a văzut niciodată.
Să presupunem acum că dorim să verificăm cât de bine modelul nostru de învățare automată învață și generalizează la noile date. Pentru aceasta avem supraadaptare și subadaptare, care sunt în mare parte responsabile pentru performanțele slabe ale algoritmilor de învățare automată.
Înainte de a ne scufunda mai departe, să înțelegem doi termeni importanți:
Bias – Ipoteze făcute de un model pentru a face o funcție mai ușor de învățat.
Varianță – Dacă vă antrenați datele pe date de antrenament și obțineți o eroare foarte mică, la schimbarea datelor și apoi la antrenarea aceluiași model anterior aveți o eroare mare, aceasta este varianța.
Subadaptare:
Se spune că un model statistic sau un algoritm de învățare automată are o subadaptare atunci când nu poate capta tendința de bază a datelor. (Este ca și cum ai încerca să potrivești pantaloni subdimensionați!) Subadaptarea distruge acuratețea modelului nostru de învățare automată. Apariția sa înseamnă pur și simplu că modelul nostru sau algoritmul nu se potrivește suficient de bine datelor. De obicei, se întâmplă atunci când avem mai puține date pentru a construi un model precis și, de asemenea, atunci când încercăm să construim un model liniar cu date neliniare. În astfel de cazuri, regulile modelului de învățare automată sunt prea ușoare și flexibile pentru a fi aplicate pe astfel de date minime și, prin urmare, modelul va face probabil o mulțime de predicții greșite. Subadaptarea poate fi evitată prin utilizarea mai multor date și, de asemenea, prin reducerea caracteristicilor prin selectarea caracteristicilor.
În rezumat, Underfitting – High bias and low variance
Tehnici de reducere a subadaptării :
1. Creșteți complexitatea modelului
2. Creșteți numărul de caracteristici, efectuând ingineria caracteristicilor
3. Eliminați zgomotul din date.
4. Creșteți numărul de epoci sau creșteți durata antrenamentului pentru a obține rezultate mai bune.
Supraajustarea:
Se spune că un model statistic este supraajustat, atunci când îl antrenăm cu o mulțime de date (exact ca și cum ne-am potrivi în pantaloni supradimensionați!). Atunci când un model este antrenat cu atât de multe date, acesta începe să învețe din zgomotul și intrările de date inexacte din setul nostru de date. Apoi, modelul nu clasifică corect datele, din cauza prea multor detalii și a zgomotului. Cauzele supraadaptării sunt metodele neparametrice și neliniare, deoarece aceste tipuri de algoritmi de învățare automată au mai multă libertate în construirea modelului pe baza setului de date și, prin urmare, pot construi cu adevărat modele nerealiste. O soluție pentru a evita supraadaptarea este folosirea unui algoritm liniar dacă avem date liniare sau folosirea parametrilor cum ar fi adâncimea maximă dacă folosim arbori de decizie.
În câteva cuvinte, Supraadaptarea – Varianță mare și bias scăzut
Exemple:
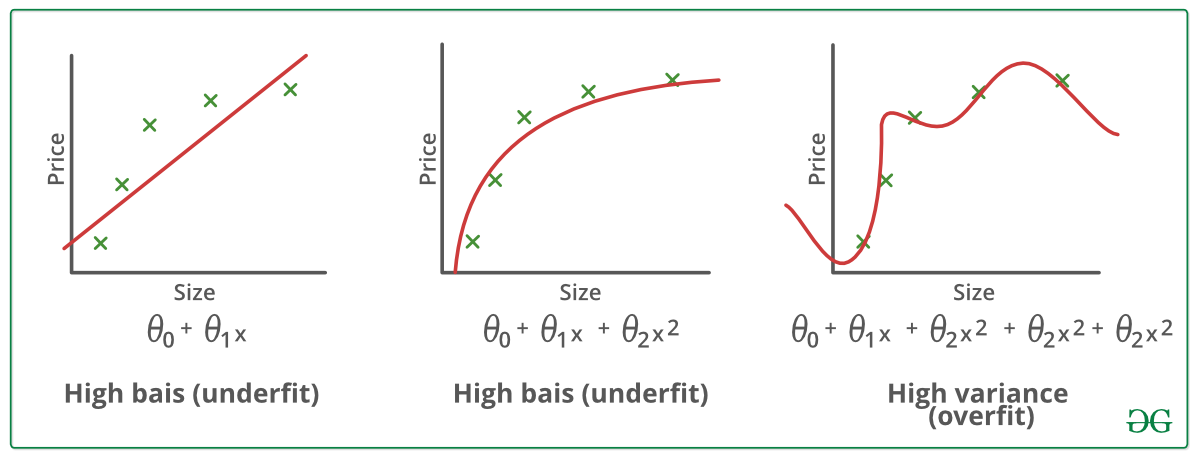

Tehnici de reducere a supraadaptării :
1. Creșteți datele de instruire.
2. Reduceți complexitatea modelului.
3. Oprirea timpurie în timpul fazei de instruire (fiți cu ochii pe pierderea pe perioada de instruire, de îndată ce pierderea începe să crească opriți instruirea).
4. Regularizarea Ridge și regularizarea Lasso
5. Utilizați dropout pentru rețelele neuronale pentru a aborda supraadaptarea.
Buna potrivire într-un model statistic:
În mod normal, cazul în care modelul face predicțiile cu eroare 0, se spune că are o bună potrivire la date. Această situație este realizabilă la un punct situat între supraadaptare și subadaptare. Pentru a o înțelege, va trebui să ne uităm la performanța modelului nostru odată cu trecerea timpului, în timp ce acesta învață din setul de date de instruire.
Cu trecerea timpului, modelul nostru va continua să învețe și, astfel, eroarea pentru model pe datele de instruire și de testare va continua să scadă. Dacă va învăța prea mult timp, modelul va deveni mai predispus la supraadaptare din cauza prezenței zgomotului și a detaliilor mai puțin utile. Prin urmare, performanța modelului nostru va scădea. Pentru a obține o potrivire bună, ne vom opri la un punct situat chiar înainte de momentul în care eroarea începe să crească. În acest punct se spune că modelul are aptitudini bune pe seturile de date de instruire, precum și pe setul nostru de date de testare nevăzut.
.