Lad os antage, at vi er ved at designe en maskinlæringsmodel. En model siges at være en god maskinindlæringsmodel, hvis den generaliserer alle nye inputdata fra problemdomænet på en korrekt måde. Dette hjælper os med at foretage forudsigelser i fremtidige data, som datamodellen aldrig har set.
Nu antager vi, at vi ønsker at kontrollere, hvor godt vores maskinlæringsmodel lærer og generaliserer til de nye data. Til det formål har vi overfitting og underfitting, som er hovedansvarlige for maskinlæringsalgoritmernes dårlige præstationer.
Hvor vi dykker videre, skal vi forstå to vigtige begreber:
Bias – Antagelser, som en model gør for at gøre en funktion lettere at lære.
Varians – Hvis du træner dine data på træningsdata og opnår en meget lav fejl, men ved at ændre dataene og derefter træne den samme tidligere model oplever du en høj fejl, er der tale om varians.
Underfitting:
En statistisk model eller en maskinlæringsalgoritme siges at have underfitting, når den ikke kan indfange den underliggende tendens i dataene. (Det er ligesom at forsøge at passe undermålsbukser!) Underfitting ødelægger nøjagtigheden af vores maskinlæringsmodel. Dens forekomst betyder simpelthen, at vores model eller algoritme ikke passer godt nok til dataene. Det sker normalt, når vi har færre data til at opbygge en præcis model, og også når vi forsøger at opbygge en lineær model med ikke-lineære data. I sådanne tilfælde er maskinlæringsmodellens regler for nemme og fleksible til at kunne anvendes på så minimale data, og derfor vil modellen sandsynligvis komme med en masse forkerte forudsigelser. Underfitting kan undgås ved at bruge flere data og også ved at reducere funktionerne ved hjælp af funktionsudvælgelse.
I en nøddeskal, Underfitting – høj bias og lav varians
Teknikker til at reducere underfitting :
1. Øg modellens kompleksitet
2. Øg antallet af funktioner, udfør feature engineering
3. Fjern støj fra dataene.
4. Øg antallet af epoker eller øg varigheden af træningen for at få bedre resultater.
Overfitting:
En statistisk model siges at være overfittet, når vi træner den med en masse data (ligesom at passe os selv i overdimensionerede bukser!). Når en model bliver trænet med så mange data, begynder den at lære af støjen og de unøjagtige dataposter i vores datasæt. Så kategoriserer modellen ikke dataene korrekt, fordi der er for mange detaljer og støj. Årsagerne til overfitting er de ikke-parametriske og ikke-lineære metoder, fordi disse typer maskinlæringsalgoritmer har større frihed til at opbygge modellen ud fra datasættet, og derfor kan de virkelig opbygge urealistiske modeller. En løsning til at undgå overfitting er at bruge en lineær algoritme, hvis vi har lineære data, eller at bruge parametre som den maksimale dybde, hvis vi bruger beslutningstræer.
I en nøddeskal, Overfitting – høj varians og lav bias
Eksempler:
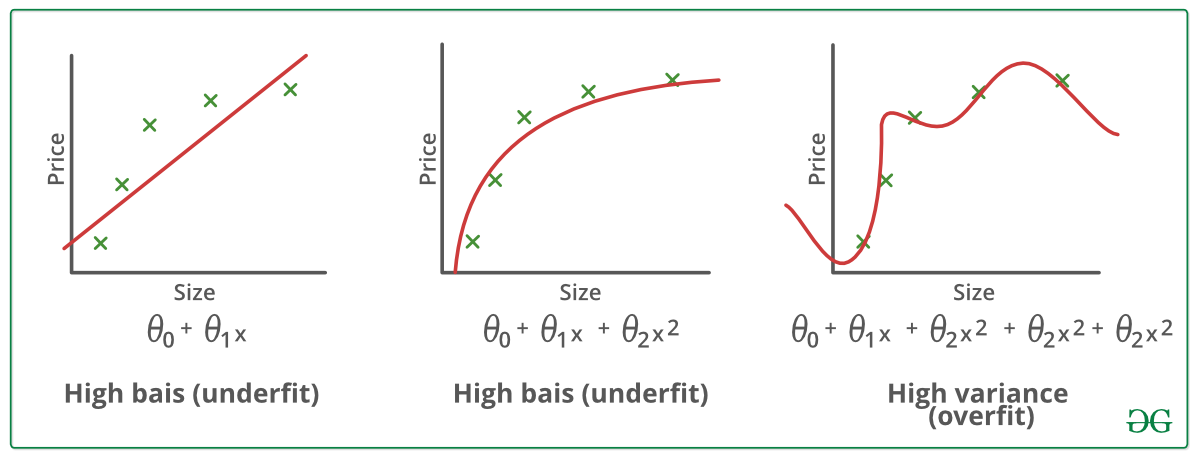

Teknikker til at reducere overfitting :
1. Øg træningsdata.
2. Reducer modellens kompleksitet.
3. Tidlig stop i træningsfasen (hav øje med tabet i løbet af træningsperioden, så snart tabet begynder at stige, stop træningen).
4. Ridge Regularization og Lasso Regularization
5. Brug dropout for neurale netværk til at tackle overfitting.
God tilpasning i en statistisk model:
Det tilfælde, hvor modellen foretager forudsigelserne med 0 fejl, siges at have en god tilpasning på dataene. Denne situation kan opnås på et sted mellem overfitting og underfitting. For at forstå det skal vi se på vores models ydeevne med tiden, mens den lærer fra træningsdatasættet.
Med tiden vil vores model blive ved med at lære, og dermed vil modellens fejl på trænings- og testdataene blive ved med at falde. Hvis den lærer i for lang tid, vil modellen blive mere tilbøjelig til at overtilpasse på grund af tilstedeværelsen af støj og mindre nyttige detaljer. Derfor vil modellens ydeevne falde. For at få en god tilpasning vil vi stoppe på et punkt lige før det punkt, hvor fejlen begynder at stige. På dette punkt siges modellen at have gode færdigheder på såvel træningsdatasæt som på vores usete testdatasæt.