Considérons que nous concevons un modèle d’apprentissage automatique. On dit qu’un modèle est un bon modèle d’apprentissage automatique s’il généralise correctement toute nouvelle donnée d’entrée du domaine du problème. Cela nous aide à faire des prédictions dans les données futures, que le modèle de données n’a jamais vu.
Maintenant, supposons que nous voulons vérifier comment notre modèle d’apprentissage automatique apprend et généralise aux nouvelles données. Pour cela, nous avons l’overfitting et l’underfitting, qui sont principalement responsables des mauvaises performances des algorithmes d’apprentissage automatique.
Avant de plonger plus loin, comprenons deux termes importants :
Bias – Hypothèses faites par un modèle pour rendre une fonction plus facile à apprendre.
Variance – Si vous entraînez vos données sur des données d’entraînement et obtenez une erreur très faible, en changeant les données puis en entraînant le même modèle précédent, vous rencontrez une erreur élevée, c’est la variance.
Sous-adaptation:
Un modèle statistique ou un algorithme d’apprentissage automatique est dit sous-adapté lorsqu’il ne peut pas capturer la tendance sous-jacente des données. (C’est comme essayer d’adapter un pantalon trop grand !) L’underfitting détruit la précision de notre modèle d’apprentissage automatique. Son apparition signifie simplement que notre modèle ou l’algorithme ne s’adapte pas assez bien aux données. Cela se produit généralement lorsque nous avons moins de données pour construire un modèle précis et aussi lorsque nous essayons de construire un modèle linéaire avec des données non linéaires. Dans de tels cas, les règles du modèle d’apprentissage automatique sont trop faciles et trop souples pour être appliquées à des données aussi minimes et, par conséquent, le modèle fera probablement beaucoup de prédictions erronées. L’underfitting peut être évité en utilisant plus de données et aussi en réduisant les caractéristiques par la sélection des caractéristiques.
En un mot, Underfitting – Biais élevé et faible variance
Techniques pour réduire l’underfitting :
1. Augmenter la complexité du modèle
2. Augmenter le nombre de caractéristiques, en effectuant de l’ingénierie des caractéristiques
3. Supprimer le bruit des données.
4. Augmenter le nombre d’époques ou augmenter la durée de l’entraînement pour obtenir de meilleurs résultats.
Surajustement :
Un modèle statistique est dit surajusté, lorsque nous l’entraînons avec beaucoup de données (tout comme s’adapter à un pantalon trop grand !). Quand un modèle est entraîné avec autant de données, il commence à apprendre à partir du bruit et des entrées de données inexactes dans notre ensemble de données. Le modèle ne catégorise alors pas correctement les données, en raison du trop grand nombre de détails et du bruit. Les causes de l’overfitting sont les méthodes non paramétriques et non linéaires, car ces types d’algorithmes d’apprentissage automatique ont plus de liberté dans la construction du modèle basé sur l’ensemble de données et peuvent donc vraiment construire des modèles irréalistes. Une solution pour éviter l’overfitting est d’utiliser un algorithme linéaire si nous avons des données linéaires ou d’utiliser les paramètres comme la profondeur maximale si nous utilisons des arbres de décision.
En un mot, Overfitting – Haute variance et faible biais
Exemples:
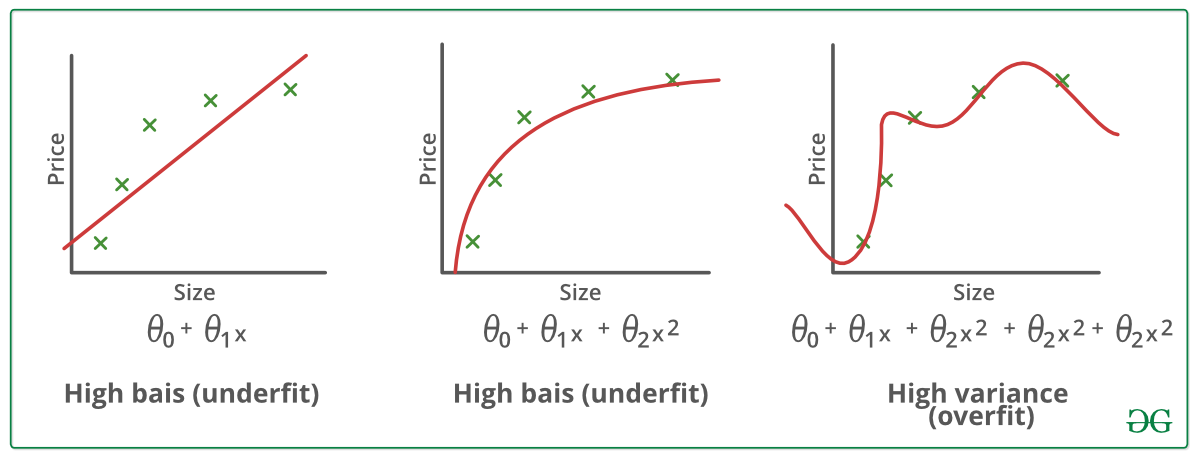

Techniques pour réduire l’overfitting :
1. Augmenter les données d’entraînement.
2. Réduire la complexité du modèle.
3. Arrêt précoce pendant la phase d’entraînement (avoir un œil sur la perte sur la période d’entraînement dès que la perte commence à augmenter arrêter l’entraînement).
4. Régularisation Ridge et Régularisation Lasso
5. Utiliser le dropout pour les réseaux neuronaux afin de lutter contre l’overfitting.
Bon ajustement dans un modèle statistique :
Enfin, le cas où le modèle fait les prédictions avec 0 erreur, est dit avoir un bon ajustement sur les données. Cette situation est réalisable à un endroit situé entre l’overfitting et l’underfitting. Pour la comprendre, nous devrons regarder les performances de notre modèle au fil du temps, alors qu’il apprend à partir d’un jeu de données d’entraînement.
Au fil du temps, notre modèle va continuer à apprendre et donc l’erreur du modèle sur les données d’entraînement et de test va continuer à diminuer. S’il apprend pendant trop longtemps, le modèle sera plus enclin à l’overfitting en raison de la présence de bruit et de détails moins utiles. Par conséquent, la performance de notre modèle diminuera. Afin d’obtenir un bon ajustement, nous nous arrêterons à un point juste avant celui où l’erreur commence à augmenter. À ce point, on dit que le modèle a de bonnes compétences sur les ensembles de données d’entraînement ainsi que sur notre ensemble de données de test non vu.