Angenommen, wir entwerfen ein Modell für maschinelles Lernen. Ein Modell ist dann ein gutes Modell für maschinelles Lernen, wenn es neue Eingabedaten aus dem Problembereich in geeigneter Weise verallgemeinert. Dies hilft uns, Vorhersagen für zukünftige Daten zu treffen, die das Modell noch nie gesehen hat.
Angenommen, wir wollen überprüfen, wie gut unser maschinelles Lernmodell lernt und auf neue Daten verallgemeinert. Dafür gibt es Overfitting und Underfitting, die hauptverantwortlich für die schlechten Leistungen der maschinellen Lernalgorithmen sind.
Bevor wir weiter eintauchen, wollen wir zwei wichtige Begriffe verstehen:
Bias – Annahmen, die von einem Modell gemacht werden, um eine Funktion leichter erlernbar zu machen.
Varianz – Wenn Sie Ihre Daten auf Trainingsdaten trainieren und einen sehr niedrigen Fehler erhalten, wenn Sie die Daten ändern und dann dasselbe frühere Modell trainieren, erhalten Sie einen hohen Fehler, das ist Varianz.
Unteranpassung:
Ein statistisches Modell oder ein Algorithmus für maschinelles Lernen wird als unterangepasst bezeichnet, wenn es den zugrunde liegenden Trend der Daten nicht erfassen kann. (Das ist so, als würde man versuchen, eine zu kleine Hose anzupassen!) Underfitting zerstört die Genauigkeit unseres maschinellen Lernmodells. Es bedeutet einfach, dass unser Modell oder der Algorithmus nicht gut genug auf die Daten passt. Dies geschieht in der Regel, wenn wir weniger Daten haben, um ein genaues Modell zu erstellen, und auch, wenn wir versuchen, ein lineares Modell mit nicht linearen Daten zu erstellen. In solchen Fällen sind die Regeln des maschinellen Lernmodells zu einfach und flexibel, um auf solch minimale Daten angewandt zu werden, und daher wird das Modell wahrscheinlich viele falsche Vorhersagen machen. Underfitting kann vermieden werden, indem mehr Daten verwendet werden und die Merkmale durch Merkmalsauswahl reduziert werden.
Zusammengefasst: Underfitting – Hohe Verzerrung und geringe Varianz
Techniken zur Verringerung von Underfitting:
1. Erhöhen Sie die Modellkomplexität
2. Erhöhen Sie die Anzahl der Merkmale, indem Sie Feature Engineering durchführen
3. Entfernen Sie das Rauschen aus den Daten.
4. Erhöhen Sie die Anzahl der Epochen oder verlängern Sie die Trainingsdauer, um bessere Ergebnisse zu erzielen.
Overfitting:
Ein statistisches Modell wird als überangepasst bezeichnet, wenn wir es mit einer großen Menge an Daten trainieren (so wie wir uns selbst in zu große Hosen passen!). Wenn ein Modell mit so vielen Daten trainiert wird, beginnt es aus dem Rauschen und den ungenauen Dateneinträgen in unserem Datensatz zu lernen. Dann kategorisiert das Modell die Daten nicht mehr richtig, weil es zu viele Details und Rauschen gibt. Die Ursachen für die Überanpassung sind die nichtparametrischen und nichtlinearen Methoden, da diese Arten von Algorithmen für maschinelles Lernen mehr Freiheiten bei der Erstellung des Modells auf der Grundlage des Datensatzes haben und daher wirklich unrealistische Modelle erstellen können. Eine Lösung zur Vermeidung von Overfitting ist die Verwendung eines linearen Algorithmus, wenn wir lineare Daten haben, oder die Verwendung von Parametern wie der maximalen Tiefe, wenn wir Entscheidungsbäume verwenden.
Zusammenfassend: Overfitting – Hohe Varianz und geringe Verzerrung
Beispiele:
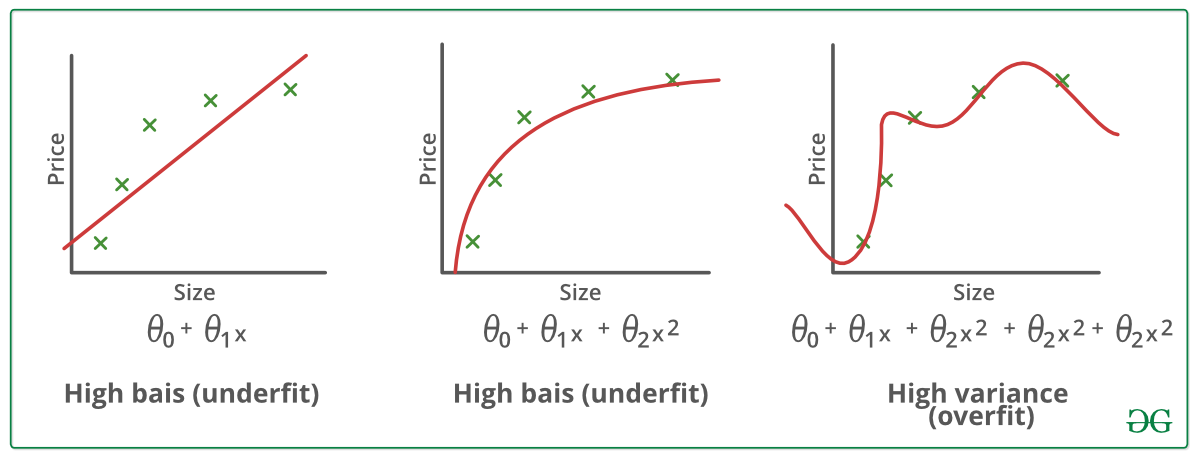

Techniken zur Reduzierung von Overfitting:
1. Erhöhen Sie die Trainingsdaten.
2. Reduzieren Sie die Komplexität des Modells.
3. Frühzeitiges Stoppen während der Trainingsphase (behalten Sie den Verlust über den Trainingszeitraum im Auge, sobald der Verlust anfängt zu steigen, stoppen Sie das Training).
4. Ridge Regularization und Lasso Regularization
5. Dropout für neuronale Netze verwenden, um Überanpassung zu vermeiden.
Gute Anpassung in einem statistischen Modell:
Genauer gesagt, der Fall, in dem das Modell die Vorhersagen mit 0 Fehler macht, wird als gute Anpassung an die Daten bezeichnet. Diese Situation ist an einem Punkt zwischen Overfitting und Underfitting zu erreichen. Um dies zu verstehen, müssen wir uns die Leistung unseres Modells im Laufe der Zeit ansehen, während es aus dem Trainingsdatensatz lernt.
Mit der Zeit lernt unser Modell weiter und somit wird der Fehler des Modells für die Trainings- und Testdaten immer geringer. Wenn es zu lange lernt, wird das Modell aufgrund von Rauschen und weniger nützlichen Details anfälliger für eine Überanpassung. Daher wird die Leistung unseres Modells abnehmen. Um eine gute Anpassung zu erreichen, stoppen wir an einem Punkt, kurz bevor der Fehler zu steigen beginnt. An diesem Punkt ist das Modell sowohl in den Trainingsdatensätzen als auch in unserem ungesehenen Testdatensatz gut geeignet.