Consideremos que estamos diseñando un modelo de aprendizaje automático. Se dice que un modelo es un buen modelo de aprendizaje automático si generaliza cualquier nuevo dato de entrada del dominio del problema de forma adecuada. Esto nos ayuda a hacer predicciones en los datos futuros, que el modelo de datos nunca ha visto.
Ahora, supongamos que queremos comprobar lo bien que nuestro modelo de aprendizaje automático aprende y generaliza a los nuevos datos. Para ello tenemos el sobreajuste y el infraajuste, que son los principales responsables de los malos resultados de los algoritmos de aprendizaje automático.
Antes de profundizar, vamos a entender dos términos importantes:
Bias – Supuestos realizados por un modelo para hacer una función más fácil de aprender.
Varianza – Si entrenas tus datos en datos de entrenamiento y obtienes un error muy bajo, al cambiar los datos y luego entrenar el mismo modelo anterior experimentas un alto error, esto es varianza.
Subajuste:
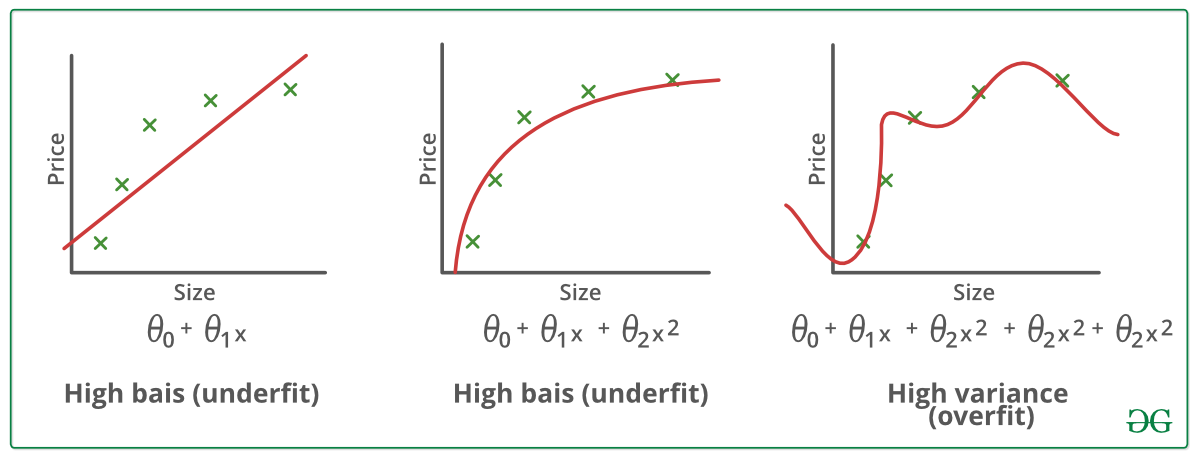
Se dice que un modelo estadístico o un algoritmo de aprendizaje automático tiene subajuste cuando no puede capturar la tendencia subyacente de los datos. (¡Es como intentar ajustar unos pantalones demasiado pequeños!) El infraajuste destruye la precisión de nuestro modelo de aprendizaje automático. Su aparición significa simplemente que nuestro modelo o el algoritmo no se ajusta lo suficientemente bien a los datos. Suele ocurrir cuando tenemos menos datos para construir un modelo preciso y también cuando intentamos construir un modelo lineal con unos datos no lineales. En estos casos, las reglas del modelo de aprendizaje automático son demasiado fáciles y flexibles para aplicarlas a unos datos tan mínimos y, por tanto, el modelo probablemente hará muchas predicciones erróneas. El underfitting puede evitarse utilizando más datos y también reduciendo las características mediante la selección de características.
En pocas palabras, Underfitting – Alto sesgo y baja varianza
Técnicas para reducir el underfitting :
1. Aumentar la complejidad del modelo
2. Aumentar el número de características, realizando ingeniería de características
3. Eliminar el ruido de los datos.
4. Aumentar el número de épocas o aumentar la duración del entrenamiento para obtener mejores resultados.
Sobreadaptación:
Se dice que un modelo estadístico está sobreadaptado, cuando lo entrenamos con muchos datos (¡como si nos pusiéramos unos pantalones demasiado grandes!). Cuando un modelo se entrena con tantos datos, empieza a aprender del ruido y de las entradas de datos inexactas de nuestro conjunto de datos. Entonces el modelo no categoriza los datos correctamente, debido al exceso de detalles y ruido. Las causas del sobreajuste son los métodos no paramétricos y no lineales, ya que estos tipos de algoritmos de aprendizaje automático tienen más libertad a la hora de construir el modelo basado en el conjunto de datos y, por lo tanto, pueden construir realmente modelos poco realistas. Una solución para evitar el overfitting es utilizar un algoritmo lineal si tenemos datos lineales o utilizar los parámetros como la profundidad máxima si estamos utilizando árboles de decisión.
En pocas palabras, Overfitting – Alta varianza y bajo sesgo
Ejemplos:

Técnicas para reducir el overfitting :
1. Aumentar los datos de entrenamiento.
2. Reducir la complejidad del modelo.
3. Parada temprana durante la fase de entrenamiento (tener un ojo puesto en la pérdida durante el periodo de entrenamiento, tan pronto como la pérdida empiece a aumentar parar el entrenamiento).
4. Regularización Ridge y Regularización Lasso
5. Utilizar dropout para redes neuronales para atajar el overfitting.
Buen ajuste en un modelo estadístico:
En realidad, el caso en que el modelo hace las predicciones con 0 error, se dice que tiene un buen ajuste sobre los datos. Esta situación es alcanzable en un punto intermedio entre el sobreajuste y el infraajuste. Para entenderlo tendremos que observar el rendimiento de nuestro modelo con el paso del tiempo, mientras está aprendiendo del conjunto de datos de entrenamiento.
Con el paso del tiempo, nuestro modelo seguirá aprendiendo y, por tanto, el error del modelo en los datos de entrenamiento y prueba seguirá disminuyendo. Si aprende durante demasiado tiempo, el modelo será más propenso a sobreajustarse debido a la presencia de ruido y detalles menos útiles. Por lo tanto, el rendimiento de nuestro modelo disminuirá. Para conseguir un buen ajuste, nos detendremos en un punto justo antes de que el error empiece a aumentar. En este punto se dice que el modelo tiene buenas habilidades en los conjuntos de datos de entrenamiento así como en nuestro conjunto de datos de prueba no visto.